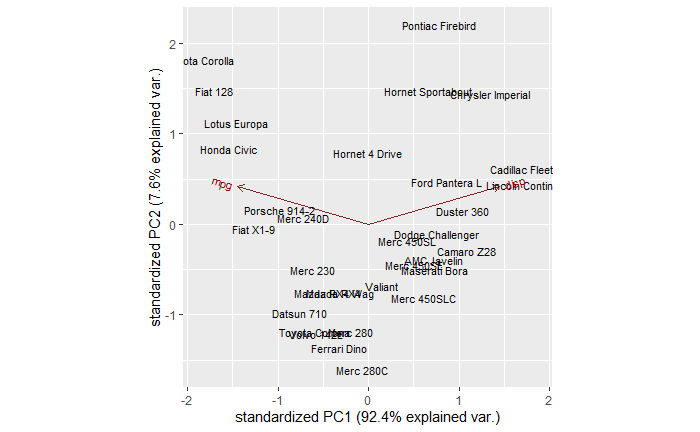
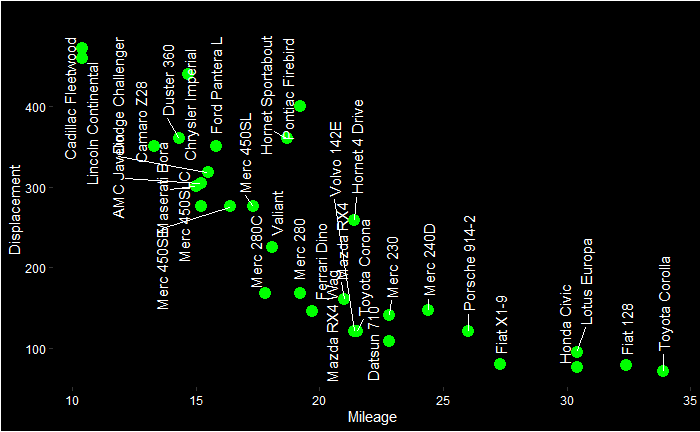
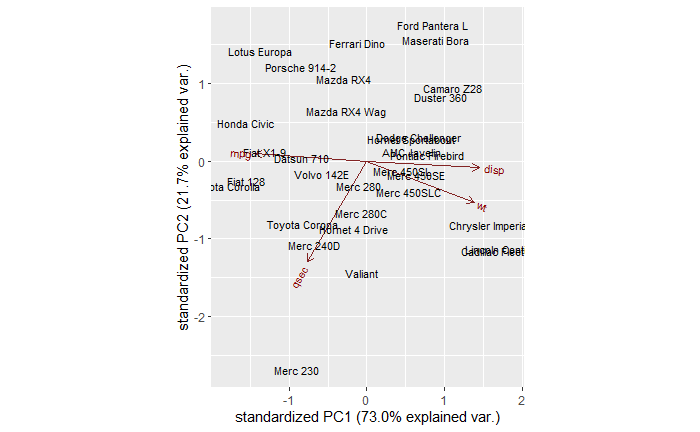
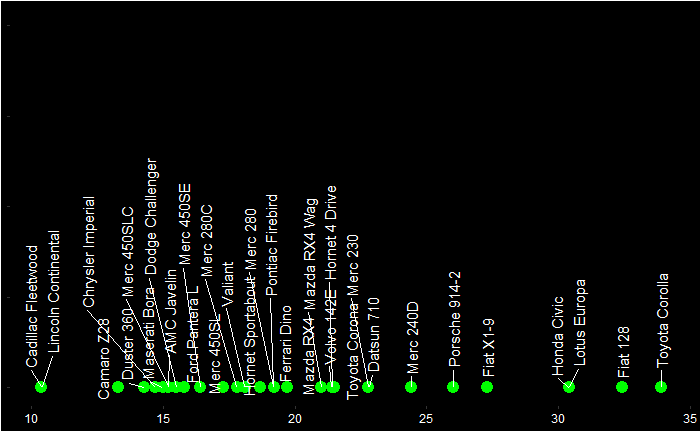
People lament about the dominance of beliefs and the reduction of scientific temperament in society. Unfortunately, it is a fact and can only be worse in future. And I want to argue that it can only be like that. Let’s look at a few reasons why achieving scientific character is a mission impossible.
It’s another religion
Unfortunately, it has to be.
Take the example of the discovery of gravitational waves in 2015. The number of people involved in the observation, which includes the setting hypothesis, the detection, and the mathematical modelling, could be about 1000. The rest of the world (1000 short of 7 billion) only gets the publication, which is already a heavily cut-down, readable version of the actual data.
Imagine a million people downloaded the paper.
As per an old report in physics today, the percentage of physics graduates (minimum decent training level in this field) was about 0.01. It suggests the inconvenient truth that 99.99% of people are already at a considerable disadvantage.
I.e., half all physics graduates and the rest others!
The people who understand the model (the specific mathematics behind the event) are even fewer and could be in the hundreds at best.
All the others – 6999 million out of 7000 – get the news from the media. And they must trust the report. A belief system is created but is not going to last like a religion, as we shall see soon.
What is Science
Most people know science through technology, the application of the former into products. To define it in one word: science is hypothesis testing. And most people are alien to it. It is probabilistic, conditional, and will/must update with time. Each of these contradicts the doctrines of religion.
Probabilistic thinkers meet the real people
Back to the gravitational waves: Movements on the ground, temperature changes in the instruments or numerous other known or unknown errors can all lead to artificial signals or noises. The importance of the results led to keeping a significance level for the rejection of the null hypothesis (that the observed signal is a noise) to be extremely low – one in a billion. If you recall, most of our ordinary life experiments that is one in 20!
The team investigating the gravitational waves published the findings (as real) only when they found the probability that it could happen by chance is one in a billion. Yet, they would only use the words such as ‘likely’, ‘probably’ or ‘mostly’, to respond to the public, who want ‘yes’ or ‘no’ as answers.
And they change with time
Science updates with new information. Remember the chaos during covid time? The understanding of the illness changed daily during the pandemic. The use of masks (to use or not to use) and modes of contagion (airborne vs liquid-borne), to name a few. While the changes of advice were perfectly understandable and acceptable for those scientists, it was causing confusion and anger to the 99.99%.