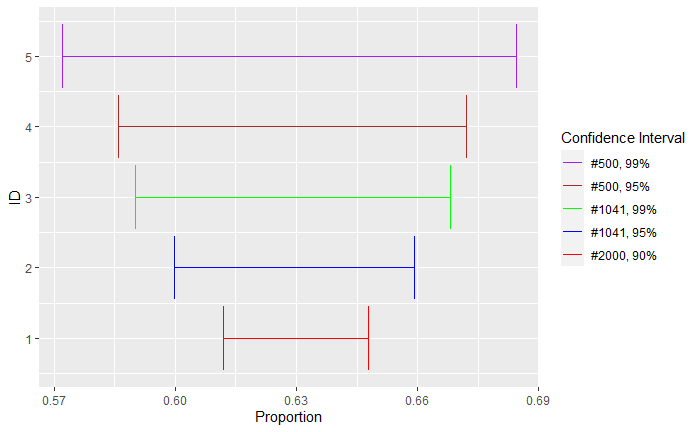
A recent study suggests that 63% of the people in a city believe in parapsychological phenomena. The study surveyed 1041 residents. What is the margin of error of the results at a 95% confidence interval?
This is the problem of estimating the margin of error on point estimates from a sample. You may know by now that the ultimate goal is to calculate the population proportion, for which sampling (and thus obtaining the sample proportion) is the only practical path. The point estimate of proportion, p, is evaluated from x, the number of successes (people who said “YES” to parapsychology here), and the sample size (n):
p = x/n
The remaining, 1 – p, is the proportion of failures (n – x out of n).
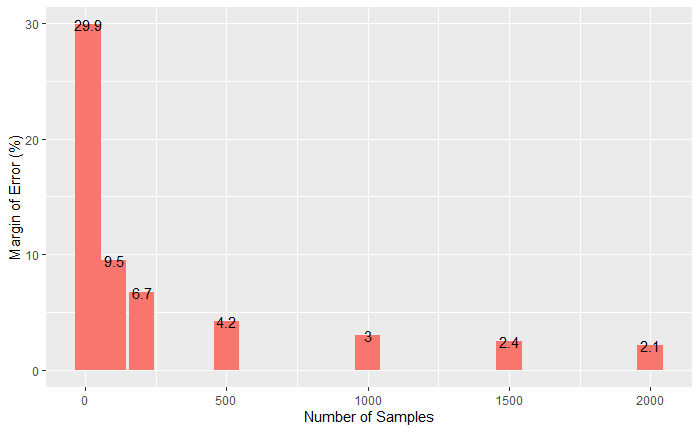
In the given sample, 0.63 is the p or the proportion of people who believed in parapsychology. Can you conclude that 0.63 remains the fraction of similar believers in the city? The answer is No; therefore, we estimate the margin of error by applying the formula. The margin of error gives the expected range of values to capture the population at some confidence level.
margin of error = z-critical value x square root (p x (1-p) / n)

z-critical value for a 95% confidence interval is 1.96, for 99% is 2.576, etc.
The whole process can be done in one step using R.
prop.test(proportion*n_sample, n_sample, p = NULL, alternative = "two.sided",
correct = TRUE, conf.level = 0.95)
1-sample proportions test with continuity correction
data: proportion * n_sample out of n_sample, null probability 0.5
X-squared = 69.853, df = 1, p-value < 2.2e-16
alternative hypothesis: true p is not equal to 0.5
95 percent confidence interval:
0.5997570 0.6592715
sample estimates:
p
0.63
Or by applying the formula directly.
n_sample <- 1041
proportion <- 0.63
std_error <- sqrt(proportion*(1-proportion)/n_sample)
margin <- std_error*qnorm(0.975)
proportion + margin
proportion - margin
The margin of error is 0.029, and the confidence interval is found by adding and subtracting it from the sample proportion (0.63).
[ 0.600, 0.659]
So, we are 95% confident that the true proportion of the population lies between 0.600 and 0.659, right? Not really; it only means that if you perform several random samples from this population, we expect about 95% of those intervals to contain the true proportion.