Imagine you live in a town of ten thousand inhabitants. And you wanted to understand some of their habits, say, what type of food they eat, the festivals they celebrate etc. What will you do?
You go and ask every one of them. That could well be possible, as the town is not that big, 10,000 people. But you think it is a lot of effort, and you decide to employ a sampling agent. She goes to the supermarket and takes a survey of 100 people. She just did that and now tells you what she found.
She averaged the survey results and made a point estimate. She did some math and established confidence intervals to communicate. She says: “I can say with 95% confidence level that the average person of the town eats between 4.6 to 5.4 loaves of bread a day”. How do we understand her?
The first thing is about the range – she gave a range [4.6 to 5.4]. It may have suggested you a mean (the bird in the picture) equals five and a spread (of its wings) of +/- 0.4. Then she says about a confidence interval as a percentage. What it means is if one does 100 such samples, 95 of the samples may have ranges that include the true average of the population – the latter is a big unknown as she never got a chance to sample everyone. This sample could be one of them, but we never know, as it was the only sample.
Some examples are below.
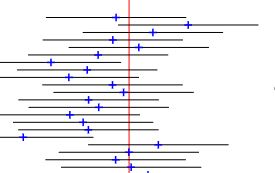
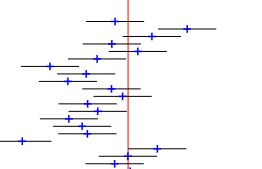
Confidence Interval of 95% of a set of 20 samples with a large range. Note that out of 20 samples, 19 of them cover the true population mean, represented as a red vertical line. Confidence Interval of 90% of a set of 20 samples. Out of 20 samples, 18 of them cover the true population mean, represented as a red vertical line. Confidence Interval of 50% of a set of 20 samples; about half (10) of them cover the true population mean.
Note: as the value of the confidence interval increases, the length of the wings, some multiples of the standard deviation, also increases. More on how to construct a confidence interval is in another post.
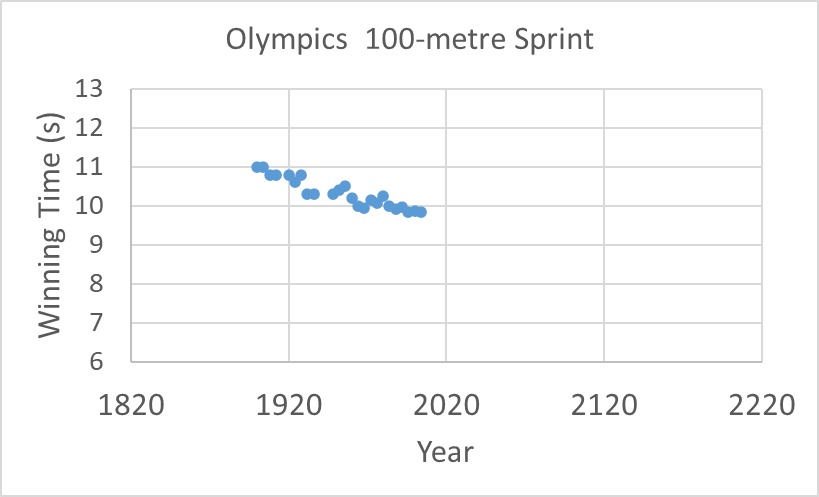
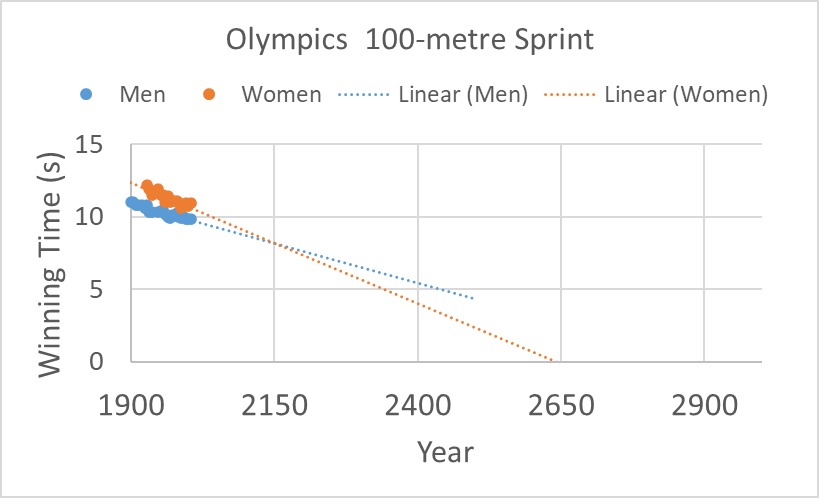
An ever-improving linear progression of sprint timings? Then what is your forecast, say, in the year 2200 or the year 2800?
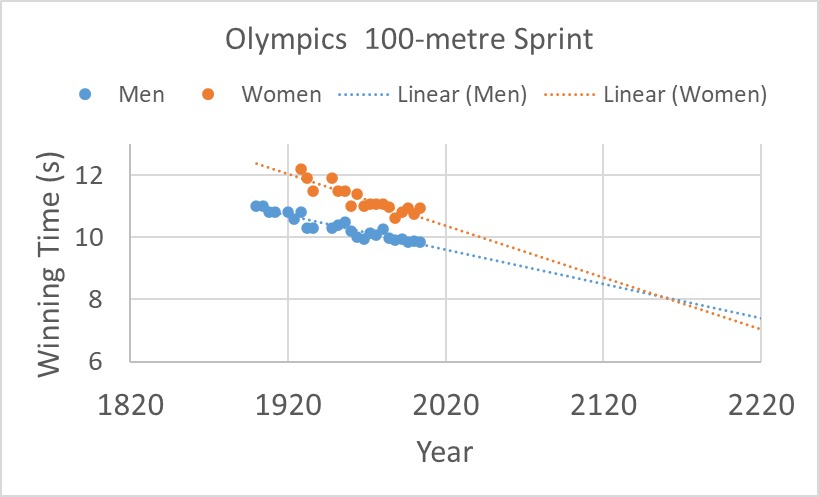
It was what happened in 2004 when a group of researchers published in the prestigious science journal nature. The article was titled, Momentous Sprint at the 2156 Olympics?: Women Sprinters are Closing the Gap on Men and May One Day Overtake Them! The study plotted men’s and women’s winning timings in Olympic 100-sprints and extrapolated to the future, similar to what I reproduced below:
And the result? A mockery of a publication in the most coveted journal in science.
The Straight Line Instinct
It is an example of what is known as the straight-line instinct, a term coined in the book Factfulness by Hans Rosling. Rosling talks about the general tendency of people to extrapolate things linearly without any regard to actual physics (or biology). Straight-line thinking is very natural to human beings. That is how we escape from a stone thrown straight at us or avoid hitting a pedestrian crossing the road ahead of us while driving.
What is Wrong with the Analysis?
First, they should have done a sanity check, especially after seeing the outcome. Some alarm bells ought to have rung not just after seeing women sprinters crossing men in the future, but more importantly at the prospect of humans crossing the 100-metre mark in zero time on extrapolating the graph even further.
Second, they did the crime of collecting a few data covering about 100 years and extrapolated over another 200. Third, they ignored the science of athletic training, early improvements and subsequent plateauing of human performance. It is like a baby in the growing phase. If you look closely, the women’s event in the Olympics started about 25 years after the men’s. So, the massive early improvements in timing lagged for many years.
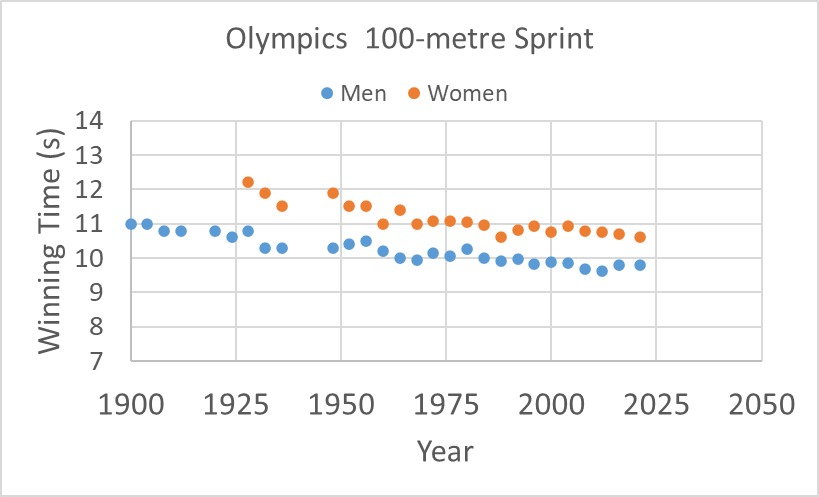
Before we close, let us have a final look at the data updated to the latest Olympics that happened in 2021.
Mixing is the reality of life; pure only exists in our imagination.
Humans have this love for purity and feel shame about the undeniable reality of mixing. While people in some parts of the world are proud of eating a ‘purely’ vegetarian diet, others list everything they could recollect from their harddisks to proclaim their superior ancestry. They are all right, but only for a negligibly short duration in history. Human history does not give a damn about vegetable eaters, and the same for any exclusive ancestry!
A landmark research paper came out in September 2019 in the journal Science titled, ‘The formation of human populations in South and Central Asia’. It was a report based on ancient DNA data from 523 individuals spanning the last 8000 years, from Central Asia and northernmost South Asia.
Migration of Yamnaya Steppe Pastoralists
The paper was primarily on the migration of the Eurasian Steppe to South Asia around 3000 years ago. The ‘Steppe Ancentry’ or Yamnaya culture was active around 5000 years ago in present-day Ukraine and Russia. The folks from that region had travelled to either side of the world, to Europe and South Asia. Today we talk about the guys and, perhaps some girls, who migrated to the east.
It is relevant here to talk about another DNA study published in Nature in 2009. This study genotyped 125 DNA samples of 25 different groups of India and did what is known as a Principal Component Analysis (PCA) of the data. Based on the similarities of the allele, they found a relationship between people of the North and South of India. An ancestral component, they call it ANI (Ancestral North Indian), varied from 76% for the North to 40% in the south. The remaining fraction is the ASI (Ancestral South Indians). Note that a ‘Pure’ ASI, closer to the earliest humans (travelled from Africa, of course), was not seen in that study.
Where are those people? That is next
Flashback
ASI was ‘ruling the land’ and Indus Valley Civilisation (IVC) was flourishing when the Steppe folks arrived in present-day India. But that would change soon, and the visitors would form a mix, which is the base of the continuous band from North to South that we saw earlier. So was ASI was the original one? The answer is a firm NO. ASI was a mix of what is known as AASI and a group of people with Iranian farmer ancestry. And who were this AASI? Well, they were the people who came 40,000 years ago, yes, from the cradle of homo sapiens, Africa. Of course, the Iranian farmers also went from Africa, but a few tens of thousands of years earlier.
Piecing All Together
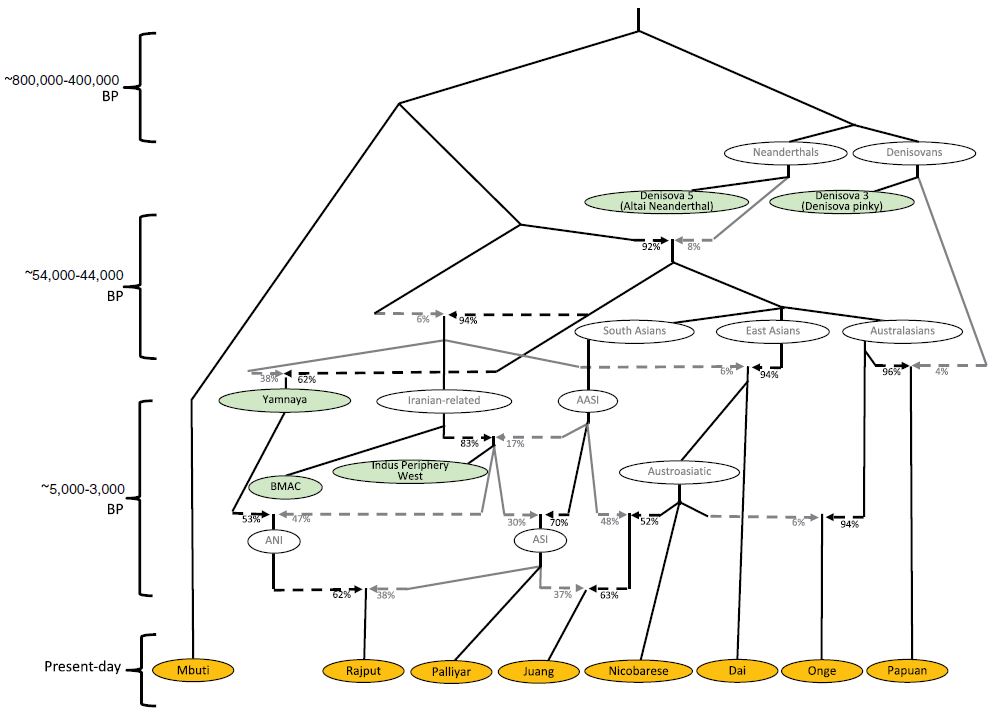
The following picture, copied from the Science paper, summarises the whole story.
Why Is It Important?
It is always fun to learn more and more about the incredible spread of homo sapiens from Africa to the rest of the world. It is equally wonderful to note how dynamic was the intermixing of population. Also, notice one irony. These results, the vivid stratification of ANI and ASI, were possible due to their obsession with endogamy in the last few hundred years. That way, they preserved the signatures of the founders or else it would have been a complete mixing of genes.
The formation of human populations in South and Central Asia: Science
I want to continue the discussion on population. Again, another myth that has been dividing society for quite some time. It’s about the fertility of Muslims in India. First, check this data.
Now, you get the picture. The Muslim population has been at the receiving end of stereotyping on family sizes. As the largest minority religion, they have been looked at with a lot of suspicion by the majority in India. It was the suspicion of being overtaken one day by the minorities and, as expected, became a key discussion point in many elections.
It was a fact in the past, and it still is, that Mulsim women have an average fertility rate more than most of the other religions. It is also a fact that they made the most solid improvement in the last 20 years.
The Reality of Fertility Rates
Religious leaders advocate for more children in their community as a show of strength, and getting lost in that noise is easy. But what happens inside the family is quite different. Family size selection is often determined by economic status, coming from the need to have more ‘boys’ to support households. It has been proven beyond any doubt that female education and economic empowerment are the factors that determine family size. Check this data if you are still in doubt.
The current fertility levels of India are a powerful testimony of how communities are climbing the ladder of social and economic development. We should acknowledge this, and policymakers should strive to establish even more parity among various communities in society.
At the end of their report, Pew Research also shows a population projection for 2050.
News items about population growth are sure to grab a lot of attention. For the government, it means planning, and for the public, it concerns sharing resources. For the groups with a vested interest, it is all about the ‘others’ and the potential threat they become to ‘us’. India is no exception.
That is why the news about India’s fertility rate falling below the replacement rate is very important. According to the latest National Family Health Survey 2019-21, the number of children per fertile woman in India is 2.0. In other words, from now on, the number of children born can’t match the number of parents (which is two!).
Was it a sudden phenomenon that no one knew coming? False. The fertility rate has been on a free fall since 1960—from about 5.9 to what we have today! Now, leave this post and click this Gapminder link.
Then why has the population been increasing all these years? Surely not because children were going up or the old were living longer. It is because the number of adults has been going up. To understand this, you should know the shape of India’s demography.
This population pyramid is from 2011, but an older version is not expected to be hugely dissimilar. We can do the math in another post, but remember this. Children of today (say 0 to 20 years) have to fill the large neck that appears in the pyramid. The people getting out of the system due to old age are from an even narrower side.
What is the probability of creating a fully developed animal or a human being? Creationists often use this argument to challenge science, but that is understandable. What is depressing is to see many scientists, too, falling into their trap.
Look at this mind-boggling probability. Think about one biological molecule in our body – haemoglobin. The molecule consists of 4 chains of amino acids, and each chain is about 146 links consisting of a possible 20 amino acids. So, to get a functional molecule, it needs to get one right out of (20)146 options. How is it then possible to have the whole human body created? Since your random processes can’t explain such ‘beautiful crafts’ of nature, you better accept my design theory!
It is a valid question, except that today’s complex systems are not formed like this. The answer lies in evolution. You and I are today because of the accumulated small changes. Not from any single change. Getting a small change is relatively easy, with about a few million unforced errors happening every day.
The complex systems we see today all originated from simpler systems. And those simpler ones, from even simpler ancestors. Until the stage, when the first life, some RNA-based self-replicating molecule, was formed! And how are they made? By chance in the chemistry laboratory of the earth using simple gases in the presence of heating, cooling and lightning. Stanley Lloyd Miller and Harold Clayton Urey proved that in 1953 by using methane, ammonia, water, hydrogen, and electric discharge to produce amino acids. Subsequent works of scientists synthesised the building bases of RNA from simple molecules.
In my post on SLC24A5 or the one on plant breeding, we have seen that a simple change in a random gene location can produce wonders. Think about it. There have been 3.5 billion years passed since the first life. Millions of trivial changes happened, a few of them passed through the sieves of nature, and a number of them got rejected to extinction. It is called natural selection.
This time we discuss another story from the paper of Tversky and Kahneman – about the biases originating from our inability to make adjustments from an initial value. In other words, the initial value anchors to our head.
To illustrate this bias: the following expressions were given to two groups of high-school students to estimate in 5 seconds. to the first group: 1 x 2 x 3 x 4 x 5 x 6 x 7 x 8 to the second group: 8 x 7 x 6 x 5 x 4 x 3 x 2 x 1
The median estimate for the first group was 512, and that of the second was 2250 (the correct answer is 40320)!
Our Estimation of Success and Risks
Overestimation of benefits and underestimation of downsides are things we see every day. On the one hand, it was necessary for us, as a species, to make progress, yet it could seriously land in failure to deliver quality products in the end.
Conjunctive Events
Imagine, the success of a project depends on eight independent chances, each with 95% probability (almost a pass for each!). So overall, the project has (0.95)8 = 66% chance of success. Often people overestimate this as the number 0.95 gets them into a belief of surety of success. These are conjunctive events, where the outcome is a joint probability or conjunction with one other.
Disjunctive Events
A classic case of a disjunctive event is the estimation of risk. Each stage of your project has a tiny probability, about 5%, that can stop the business. What is the overall risk of failing? You know by now that you can’t multiply all those tiny numbers, instead estimate the chance not to lose in any step and then subtract it from 1. (1 – (0.95)8) = 33%. You don’t finish in one out of three cases. People underestimate risks because the starting point appears too small to be significant.
Consider a group of 10 people who form committees of k members, 2 < k < 8. How many different committees of k members can be formed?
Judgment under Uncertainty: Heuristics and Biases, Tversky and Kahneman
The third story from Tversky and Kahneman paper is about the role of imaginability in the estimation of probabilities. Consider this group of 10 people who form committees of a minimum of 2 up to a maximum of 8. To find how many possible ways to form teams, you need to apply what is known as Combinations, which is nothing but the binomial coefficient that you have seen earlier. i. e. Combinationsof n things taken k at a time without repetition.
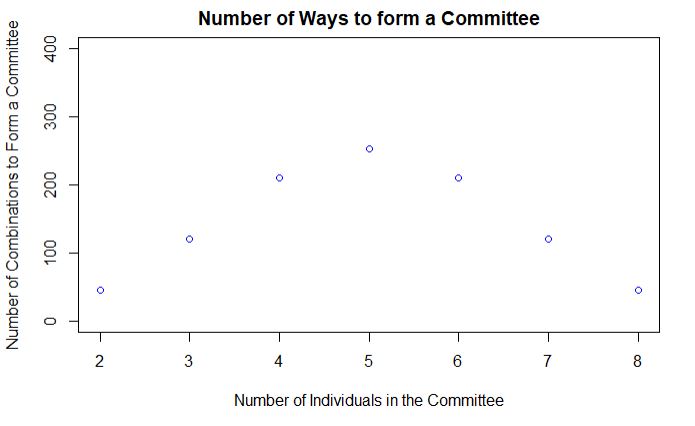
For 3-member teams, it comes out to be 10C3 or 120. The choice increases to the maximum for 5 (252 combinations), and then decreases symmetrically such that nCk = nCn-k (number of 3-member groups = number of 7-member groups and so on).
The following R code uses the function choose(n,k) to evaluate the binomial coefficient and plots the outcome.
committe <- function(n,k){
choose(n,k)
}
diff <- seq(2,8)
diff_com <- mapply(committe, diff, n = 10)
plot(x = diff, y = diff_com, main = paste("Number of Ways to form a Committee"), xlab = "Number of Individuals in the Committee", ylab = "Number of Combinations to Form a Committee", col = "blue", ylim = c(0,400))
It requires number crunching, and mental constructs don’t always help. In a study, when people were asked to make guesses, the median estimate of the number of 2-member committees was around 70; 8-member committees were at 20. So, imagining a few two-member teams were possible in mind, whereas 8-member groups were beyond its capacity.
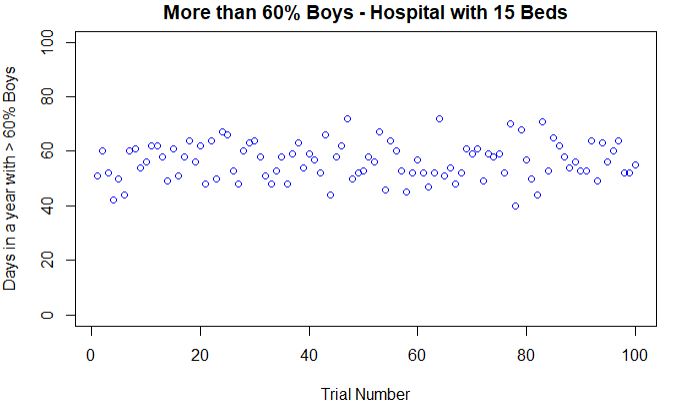
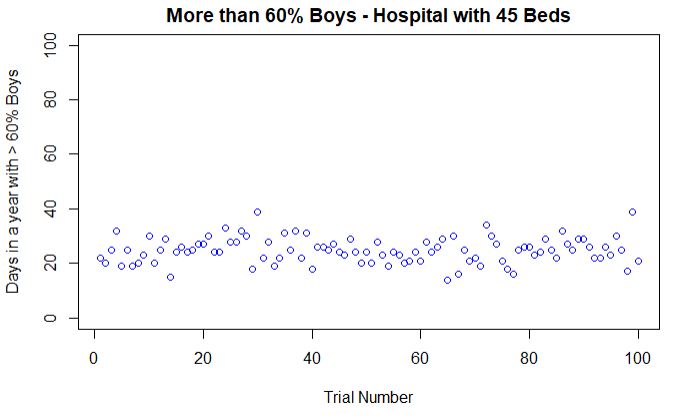
A certain town is served by two hospitals. In the larger hospital about 45 babies are born each day, and in the smaller hospital about 15 babies are born each day. As you know, about 50 percent of all babies are boys. However, the exact percentage varies from day to day. Sometimes it may be higher than 50 percent, sometimes lower.
For a period of 1 year, each hospital recorded the days on which more than 60 percent of the babies born were boys. Which hospital do you think recorded more such days?
b The larger hospital b The smaller hospital b About the same
Judgment under Uncertainty: Heuristics and Biases, Tversky and Kahneman
If you recall the law of large numbers, you would have guessed the correct answer, i. e. the smaller hospital. Because as the number of births increases, the gender of the baby comes closer to the expected percentage of 50.
If you still doubt, let’s run a simple Monte Carlo run using the following R code,
days <- 365
birth <- 15
boy <- 0.5
boys <- replicate(days, {
prob_birth <- sample(c(0,1), birth, prob = c((1-boy), boy), replace = TRUE)
mean(prob_birth)*100
})
sum(boys > 60)
Run this code 100 times and plot the answers, the probabilities of a day in which more than 60% were boys:
Now, change the number of births to 45 and re-run the calculations:
What about more than 60% of girls?
Let me end this piece with this one. Which hospital do you expect more number of days with less than 40% of boys? No marks for guessing: it is still the small hospital.
“Steve is very shy and withdrawn, invariably helpful, but with little interest in people, or in the world of reality. A meek and tidy soul, he has a need for order and structure, and a passion for detail.”
Judgment under Uncertainty: Heuristics and Biases, Tversky and Kahneman
Following the clues above, your task is to guess if Steve is a farmer or a librarian.
A significant proportion of people may have guessed Steve was a librarian. Some of the others who chose farmer may have done it so out of suspicion of the build-up.
Back to Bayes’ics
Remember the Bayes’ theorem? If not, read my earlier post, The Equation of life.
P(Lib|D) = P(D|Lib) x P(Lib) / [P(D|Lib) x P(Lib) + P(D|noLib) x P(noLib)]
Let us check the chance for the frequent answer – that Steve was a librarian – to be true (P(Lib|D)). I am ready to support the argument that all librarians fit this stereotype (P(D|Lib) = 1) if that was a concern. It is unlikely to be valid, but I give you that benefit of the doubt. Estimating the prior probability of librarian in a set of farmers and librarians (P(Lib)) is the task that needs data. Based on the available data in the public domain, in the US, that ratio is 0.026!
P(D|noLib) or the description fitting farmers is tricky, but I make an assumption least 10% of the farmer community can have shy and withdrawn men! P(noLib) is nothing but 1 – P(Lib). Substitute all the numbers
(1 * 0.026)/[(1 * 0.026)+(0.1 * 0.974)] = 0.21.
Even if all the librarians fit your mental stereotype, you are right only 20% of the time. To paraphrase what late Hans Rosling used to say: a chimp would do a better job; she picks the correct answer 50% of the time.
It’s not about Maths
The message here is not about the math, nor about the research required to get an accurate answer. It is only about being mindful about our biases and how much they can lead to inaccurate perceptions about others.