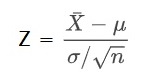Last time I’ve argued that Bayes’ technique of learning by updating knowledge, however ideal it is, is not the approach most of us would follow. This time we will see a Bayesian approach that we do, albeit subconsciously, in judging performances. For that, we take the example of Baseball.
Did Jose Iglesias appear to beat the all-time MLB record, which was more than a century-old, when he started the 2013 season with nine hits in 20 bats? His batting average in April was 0.45, with another 330 more batting to go! To most people who knew the historical averages, Jose’s performance might have appeared as a beginner’s luck!
Hierarchical model
One way to analyse Jose’s is using the technique we have used in the past, also known as frequentist statistics. By calculating the mean at the end of April, standard deviation and confidence interval. But we can do better using the historical average as prior data and following the Bayesian approach. Such techniques are known as hierarchical models.
The hierarchical models get the name because the calculations take multiple steps to reach the final estimate. The first level is player to player variability, and the second is the game to game variability of a player.
What we need to predict using the hierarchical model is Jose’s batting average at the end of the season, given that he has hit 45% in the first 20. By then, Jose’s average would be a dot on a larger distribution, the probability distribution of a parameter p (a player’s success probability for this season, but we don’t know that yet), and we assume a normal distribution. We will take the expected value of p or the average to be 0.255, last season’s average, with a standard error (SE) of 0.023 (there is a formula to calculate SE from p). By the way, SE = standard deviation / (square root of N).
Taking beginner’s luck seriously
Jose batted the first 20 at an average of 0.45, and we estimate the standard error of 0.111, as we do for any other probability distribution. If the MLB places its player averages on a normal distribution, Jose today is at the extreme right on 0.45, or an observed average of Y. Its expected value is 0.255!
In our shorthand notation, Y|p ~ N(p, 0.111); we don’t know what p is, but it is more like the probability of success of a Bernoulli trial.
Calculate Posterior Distribution
The objective is to estimate E(p), given that the player has an average Y and standard error SE. The notation is E(p|Y). We express this as a weighted average of all players and Jose. E(p|Y) = B x 0.255 + (1-B) x 0.45, where B is a weightage factor calculated based on the standard errors of the player and the system. B = (0.111)2 /[(0.111)2 + (0.023)2]. As per this, B -> 1 when the player standard error is large and B -> 0 if it is small. In our case B = 0.96. It is not surprising if you look at the standard error of Jose’s performance, which is worse than the overall historical average, simply because of the smaller number (20) of matches he played in 2013 compared to all players in the previous season.
So E(p|Y=0.45) = 0.96 x 0.255 + (1-0.96) x 0.45 = 0.263. This is the updated (posterior) average of Jose.
We have seen before how fertility rates have come down, some faster than others, but all of them nonetheless. I had promised you to do the math to show that the overall population would grow for some more time before plateauing. Today, we will do that. So, we join the celebrations of Indians who just made it to 2.0 last year.
The calculations are fairly basic, as the objective is to prove the point, not accuracy. We’ll start with the last census, the 2011 census. The following two graphs summarise the data.
Population Distribution – India 2011Population Distribution: Men and Women – India 2011
The ages are grouped in blocks of 5 years; therefore, we take 5-year steps in our calculations. In each step, we jump once to the next bucket. So people in 0-4 become part of 5-9, and so on. In the process, we multiply the survival chance of each age group using life tables presented in the census portal. That leaves the newborn group – 0-4 – to be filled up. We add up four groups that cover women from age 20 to 40 and divide by 4 to standardise and multiply with the average fertility rate, starting with 2.1 in 2011 and reducing by 0.01 per year until it reaches a steady rate of 1.85 (remember, in 2020 it became 2.0).
The results after a few years are in the following plot.
Now, we will plot the total population for all these years until 2061.
It is quite reassuring that this simple treatment was not far from the more advanced forecasting done by The Lancet in 2020, which forecasted a peak population of 1.6 B in 2048.
In Summary
The flurry of incoming guests has certainly come down. But the population hotel has many vacant rooms to occupy, thanks to the extraordinary decades of prosperity and good public health. They have to be filled up first before the number of people checking out can match the fresh inmates!
Fertility, Mortality, and Population Scenarios for 195 Countries: The Lancet
I was not originally planning to write this piece here. It just happened as an immune response to a fast-spreading youtube virus.
What is the debate?
The argument of the youtube virus was: “vaccines protect from illness. It is well-known that the current vaccines are not stopping the disease from spreading. The current vaccines only manage the condition from becoming worse. Therefore, they are not vaccines, and the system is cheating people”. He also uses a fallacy called theappeal to authority and invokes high-profile personalities from the Indian Council of Medical Research to support his view (I didn’t think a fact-check was necessary; evidence should lead and not personalities).
The vaccinated are getting infected!
I have made two posts already to show using data that the current vaccines are just delivering as they promised. Also proved mathematically, the reason for the large number of breakthrough infections for Covid, while there are near-zero levels for those vaccinated against traditional illnesses. Some of the old vaccines appear so good because their prevalence is negligible these days. Once you view the present-day covid vaccines in that light (of super high prevalence in society), you appreciate the work they are doing.
Infection vs Disease
Infection happens when pathogens (bacteria, viruses, others) enter the body and multiply. So what can prevent an infection? A barrier around your nose and mouth or by staying at home! On the other hand, disease occurs when the infection begins damaging cells. The signs of symptoms appear, and the body’s immune system acts. It is worth noting that many of the symptoms result from the activities of the immune system; fever is a well-known one.
Prevention vs Mitigation
These are two terms typically used in risk management. Their definitions are below (taken from OALD).
Prevention: the act of stopping something bad from happening. Mitigation: a reduction in how unpleasant, serious, etc. something is.
It is easy for humans to jump into the binary of prevention vs mitigation, or vaccine vs medicine. But life is more than such binaries and is full of things in between. Say the risk of getting a stroke. Doing exercises, eating balanced food, and leading a healthy lifestyle are considered prevention strategies. Suppose you have high blood pressure and you take medicines to control it. You may call it mitigation to the condition called high blood pressure. Or it can also be prevention for the real issue, the chance of getting a stroke or a heart attack or a kidney failure. In other words, prevention vs mitigation becomes a philosophical debate.
A boost to immunity?
The most useless definition of how vaccines work is boosting immunity. As a scientist, you want better. What about this: vaccines trigger immunise response in the body? It sounds better, but what is that?
When pathogens enter the body, they attach to the cell and use their resources to multiply. While all the cohabitant microbes do these (the human body has more microbes than the number of cells), only a few guys are called pathogens for a reason. They spit out antigens that can cause harm to the cell. The body uses a few techniques to mitigate this. Yes, ‘mitigate’ is my word of choice, from the viewpoint of the antigen, but you may use ‘prevent’ from the cell’s point of view. The body may respond with fever (heat inactivates many viruses), a chemical called interferon (which blocks viruses from reproducing), or deploy antibodies and other cells to target the invader.
How do Covid vaccines work?
Most of the Covid vaccines are targetting the production of antibodies against spike proteins. The antibodies, produced by the body, connect to the anchor points of the virus (the spikes), nullify the attachment of the latter, and eventually its proliferation.
One thing is clear: you need to somehow get antibodies to where it is required. Many new-generation covid vaccines work by transferring the genetic information – that produces the protein-spike – to our cells, either through messenger RNAs or by inserting it inside other viruses. Once the body gets the code, it starts making spike proteins, and antibodies follow.
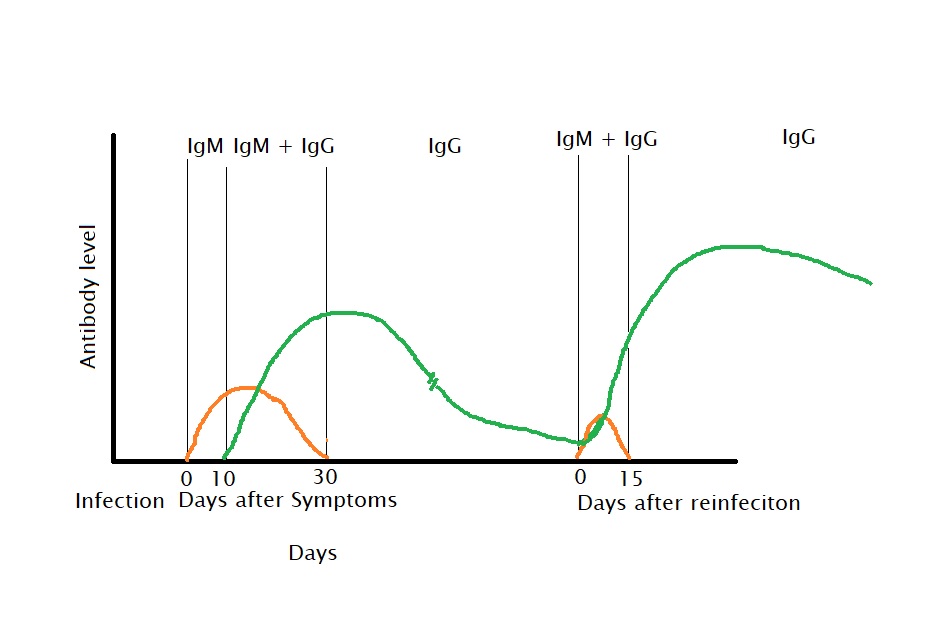
Infection and Reinfection Curves
A simple schematic of antibody production. The numbers are indicative and may vary from person to person or from disease to disease.
Several publications are available that quantify antibodies produced from various covid vaccines. To give a personal touch, the following are data from my blood tests, taken at three different intervals after my vaccine jabs.
Test done in July 2021Test Done in August 2021Test done in November 2021
Laws of mass action – What makes the debate possible?
The reaction rate between A and B forming a product is proportional to their concentrations and rate constant. The higher the concentrations or the rate constant, the faster is the reaction. Any standard chemistry textbooks will give you details. Four reactions are important to consider – the first two are against us, and the last two are with us. 1) virus + resources -> 2 virus, 2) virus + cell -> destruction. 3) blood plasma -> antibodies 4) virus + antibody -> safe product. We want items 3 and 4 to happen faster than 1 and 2.
Suppose an individual gets exposed to a high viral load. It makes the virus concentration of reactions 1 & 2 high and forces the reactions to go faster. The reaction that matters the most, reaction-4, will take some time as the amount of antibody, in the beginning, is zero. If the first reactions manage to destroy more cells, you are in big trouble. This is the trouble with Covid19; it multiplies faster and has a high sticking tendency due to its spikes.
What is the end goal of the debate?
The virus is ubiquitous now that you can see all possible ways it demonstrates in public – from people who get up without any symptoms to people dying even after getting multiple doses of vaccines. We are talking about hundreds of millions of bodies carrying out these reactions in real time. Whenever that happened in the past, they took millions of life along with them.
You will never know the real goal of the debate, but I can tell you the result. It is confusion, mistrust in the system and ultimately vaccine hesitancy. These are proving, once again, that it is easy to confuse people, by using well-known facts, but by taking them out of context and making a louder noise.
Is it prevention or mitigation? The question is not valid, and it is not either-or. Prevention and mitigation are just viewpoints that we might get based on your body’s performance. These vaccines are like any other vaccine; their job is to provide scenarios of the first infection, and are our best weapon to fight the disease, so get it. There are hundreds of data, not opinions, available in public space that support this. The only difference this time? The lab work is happening in front of you, with spotlights on!
Further Read
Safety and immunogenicity of the ChAdOx1 nCoV-19 vaccine: The Lancet
Another probability paradox – was first introduced by Martin Gardner in 1959. Let me introduce my version of the questions.
1) Mr X has two children. The first one is a girl, and what is the probability that both the children are girls?
2) Mr Y has two children. At least one of them is a girl, and what is the probability that both the children are girls?
No Two on the First
There are many ways to solve it, the simplest first. If the first one is a girl, all you have to get is the chance that the second child is a girl. Since the gender of the second child doesn’t depend on the first, the probability is 1/2. So the answer is 1/2.
The is another way, write down all the possibilities. BB, BG, GB, and GG; B represents boy, G means girl. Since the first person is a girl, the first two options go away, and the answer to choose 1 out of 2 for a GG = 1/2.
The Second will Psych You Up
The second problem is where the controversy is. Let’s take the second approach to solve it. As before, the four possibilities are BB, BG, GB, GG. Since at least one is a girl, BB goes away, and your chance of getting GG out of 3 options is 1/3.
Simple? But I do not want to agree with that. What was the difference if the question was like this: Mr Y has two children. At least one of them is a girl, and what is the probability that the other is also a girl? For all practical purposes, both the statements of problem 2 mean the same, perhaps not for mathematicians (by the way, this can be the fallacy to counter!). If at least one is a girl, the other can only be one of the two – which is 1/2. So?
What about this: if the prior information says at least one of them is a girl, you can not have BG and GB as two options (like permutation vs combination)?. So you have to look for GG from two options GG and BG/GB 😜.
We have seen Bayes’ theorem before. It is a way of updating the chance of an event to occur based on what is known as a prior probability. Check the formula, in case you forgot it because we will use it again.
We do an exercise to illustrate today’s storyline, courtesy – a course in Bayesian statistics run by the University of Canterbury. You learn about a café in town. The shop has two baristas, one experienced and one less experienced. You also came to know that the experienced makes excellent coffee 80% of the time, good coffee 15% and average coffee 5% of the time. For the less experienced, the performance stats are 20%, 50% and 30%, respectively. Your task is to go to the cafe, order, enjoy the coffee and identify the barista.
You order a cup of coffee and find it an excellent one. Is this prepared by A? Let’s use Bayes’ equation. But, where do you start? You need a prior probability to begin. One way is to assign a 50-50 chance of encountering A on that day. Another way is to use your knowledge about the workdays per week, which sounds better than 50-50.
The chance that A made your coffee, given that it was an excellent coffee: P(A|E) = 0.8 x (5/7) / [0.8 x (5/7) + 0.2 x (2/7)] = 0.90
There is a 90% chance that A prepared your coffee. In other words, the initial estimate of (5/7), based on the work pattern, is updated to a higher value.
You got time to spend on another cup of coffee, and it turned out to be an average one! Now you update your estimate using the following calculation, = 0.05 x (0.9) / [0.05 x (0.9) + 0.3 x (0.1)] = 0.625
Note that the new prior probability is 0.9 and not 5/7. The updated chance (also known as the posterior probability) is still in favour of A but reduced from 90% to 63%.
The true scientist in you tries another coffee, and the outcome was an excellent coffee, and the updated chance is now 87%. At this stage, you decided to end the exercise and conclude that the barista of that day was the experienced one.
Natural Learning Process
This process of updating knowledge based on new information is considered by many as natural learning. I would view this as the ideal learning process, which rarely happens, naturally. In real life, most of us like to carry on the baggage of knowledge – be it from our parents, peers or other dogmatic texts, and resists every opportunity to update. In other words, you ignore new information or the information that does not tally with the existing.
In my opinion, scientific training is the only way to counter the tendency to carry on the baggage. The evidence-based worldview is not natural and needs forceful cultivation.
Back to Café
In the barista story, you may be wondering why the process repeated a few times, and the enquirer settled for a lower probability than what occurred after the first cup. To get the answer, consider the exact three cups of coffee but in a different order, say the average one first. What difference do you see?
The blame instinct drives us to attribute more power and influence to individuals than they deserve, for bad or good. Political leaders and CEOs in particular often claim they are more powerful than they are.
Hans Rosling from the book Factfulness
Blame instinct and claim instinct! For a modern-day leader, be it a politician or a CEO, the former brings the power, and the latter keeps it. In one of the previous posts, we have looked at the unsubstantiated blame against Muslims in India and the reality of population growth. This time we look at the other side, the claim factories and the success of child-control policies.
Most of you are familiar with the one-child policy of China and the ‘blockbuster’ success that it brought. I remember this message used to echo everywhere when I was growing up in the eighties. Interestingly, even today, after all these years, when so much data are publically available for free that rejected the whole notion, some leaders maintain the rhetoric.
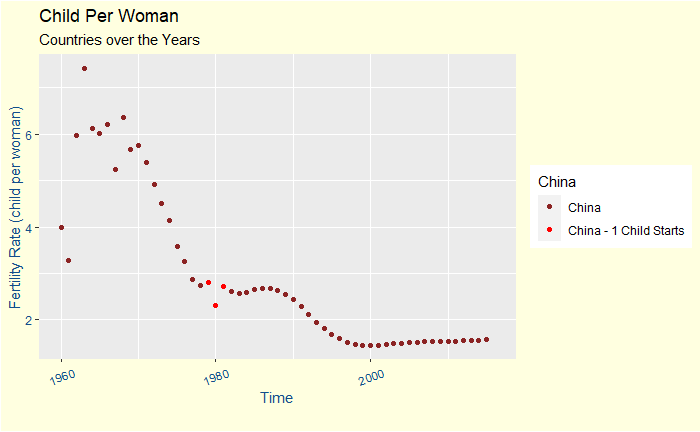
Come back to the China report. The following is a plot of the fertility rate of women in China from 1960 to 2016. For complete data and visualisations, go to the gapminder website.
As per Wikipedia, the Chinese government started the policy in 1980. In the plot, I’ve marked three years – 1979, 1980 and 1981 – in red to show, in the big picture, the timing when the government was implementing the policy. The Chinese women fertility rates have been on a sliding-down path since the 70s. The policy of 1980 may have only reduced its pace, but that I leave to your imagination.
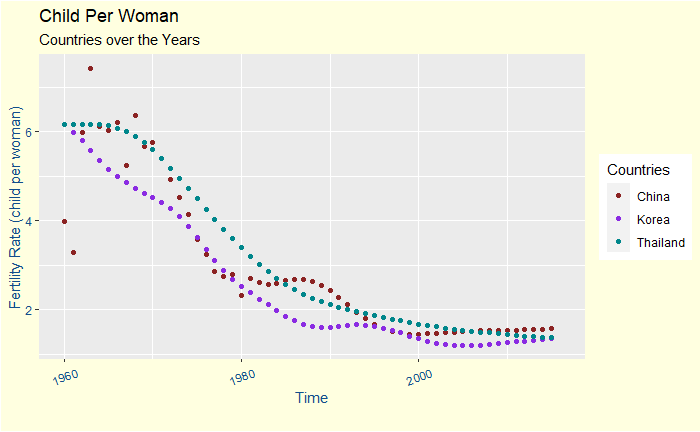
My claim above based on a plot is not entirely bulletproof. It is impossible to show that the policy did not work as the child per woman was either kept low or decreased during the period. To discover the results and remove any anomalies, we must compare the trend with other countries. So, let’s examine two countries in East Asia that did not impose such a burden on their people – South Korea and Thailand.
Did it stop in South Korea and Thailand? No, the whole of Asia has shown declines in female fertility since the middle of the twentieth century.
Thoughtful Examinations of Data
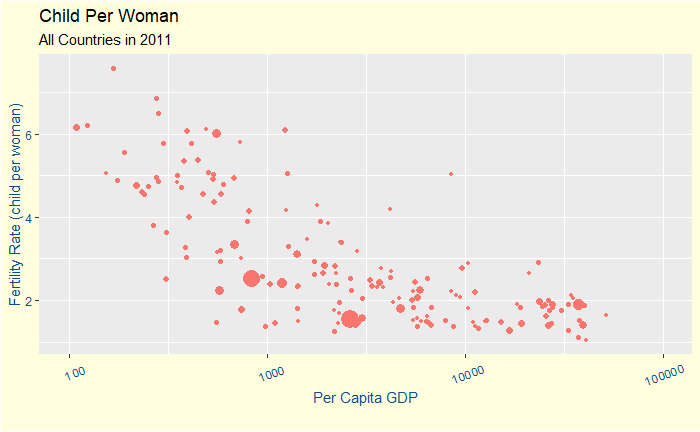
The results show the power of evidence and reflect the time we are living, the age of free and publically available data. The data showed beyond doubt that economic status and education are stronger predictors of smaller families than other popular beliefs, such as religion or strong rulers.
The size of the symbol represents the population of the country.
In simple words, when a mother is educated and financially independent enough to know that her society has the means to get her children to pass their childhood, she starts to prefer a smaller family! A family that can have a quality life and where the children can climb the social and economic ladder.
Why are Claims So Powerful?
It is so convenient. Something that happened without any intervention from the all-powerful is difficult for humans to admit, especially for the powerful humans! The public also believes them as the claims go hand in hand with the almighty image of the powerful.
Today is all about Stephen Curry. We talk about him; everything else can wait. On the 14th of December 2021, Steph became the all-time leader of 3-point shooting in the NBA.
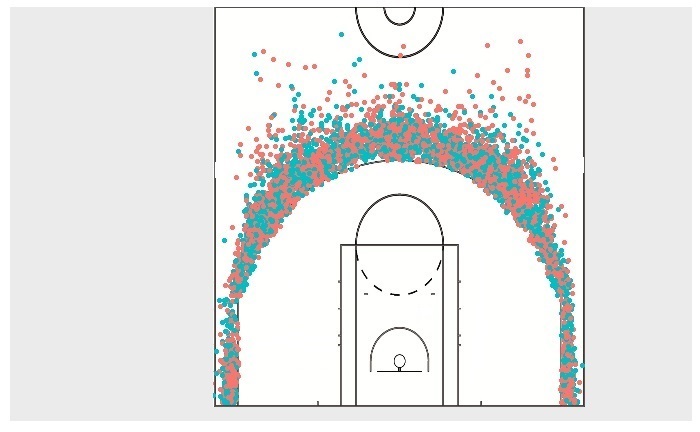
We give the tribute by checking and visualising a few of his performance highlights in the NBA. First, what he is famous for – the 3 point shooting. Following is a visualisation of all three-point attempts (successful and unsuccessful) from 2010 until 2018.
The blue dots represent the successful, and the red dots represent the failed attempts. The output was generated using the following R code:
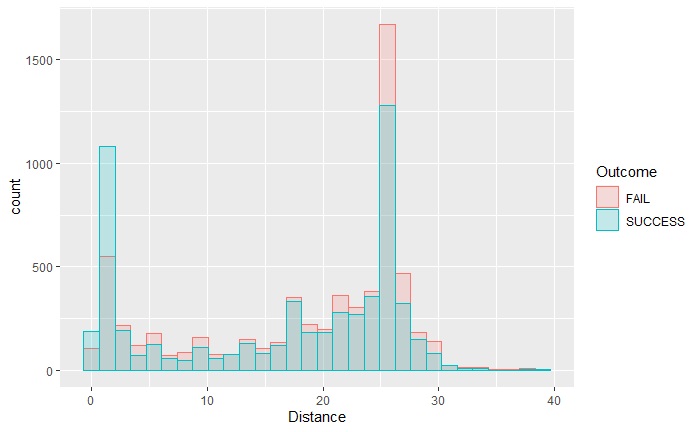
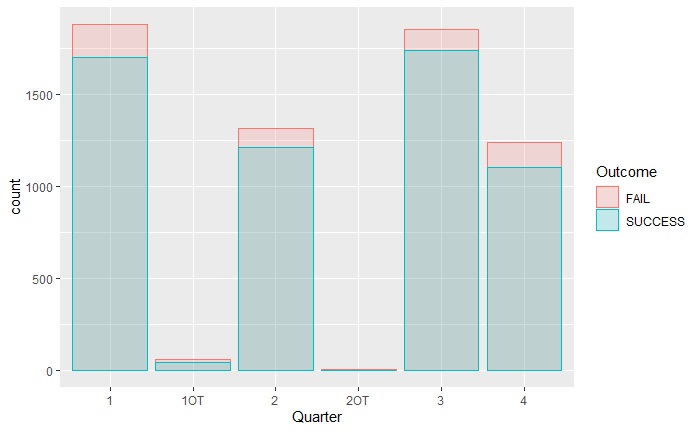
Following are histograms of his attempts and successes from different distances and in various quarters. Note that my plots are only as good as the data in hand (that too ended in 2018). And I realise that it missed shots that Curry did from beyond the centre line!
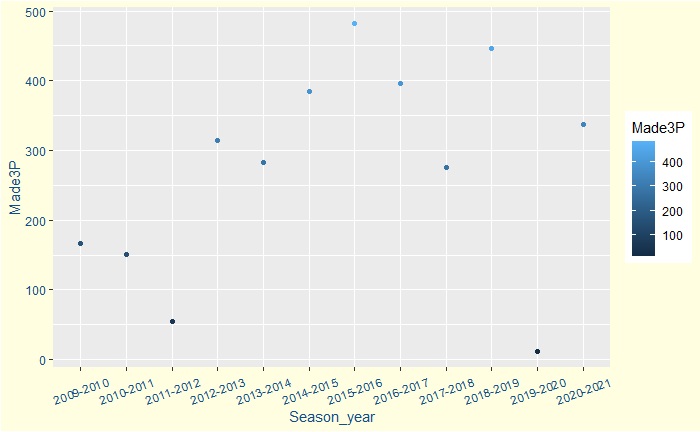
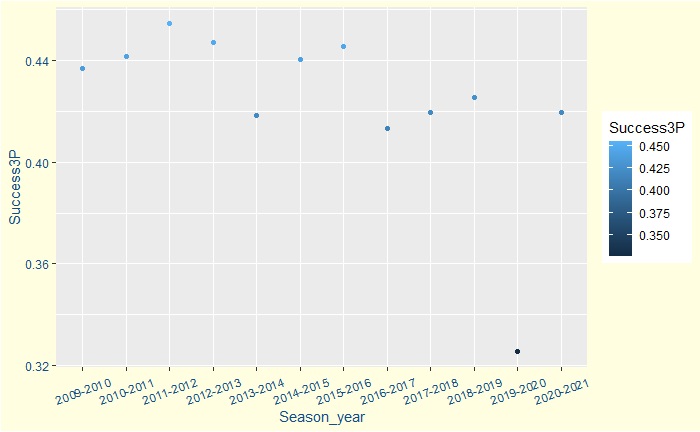
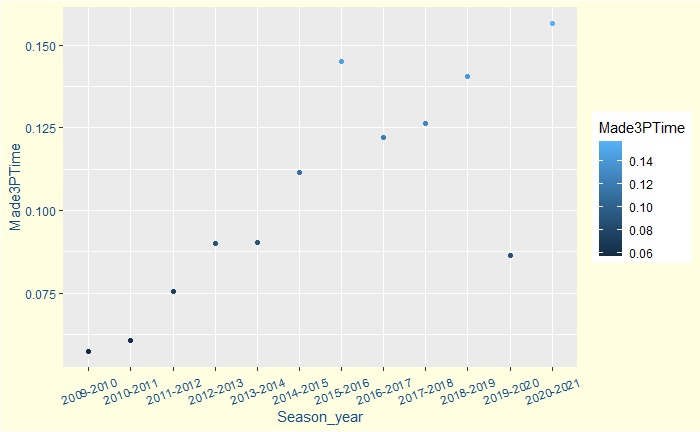
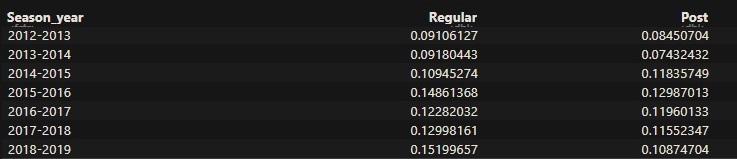
Now, let’s look at how Steph has made his three-pointers over the seasons. The stats include regular and post-seasons. Steph had a blockbuster season in 2015-16, in which he became the season MVP.
Steph maintained a high 3 point percentage success rate of above 40% in most seasons
With ever-increasing efficiency (3 points made per minute of play)
With excellent regular-season and decent post-season efficiencies. You may remember that two of them – 2015-16 and 2018-19 – resulted in his team, Golden State Warriors, losing in the NBA finals.
FiveThirtyEight (538) is a website based in the US that specialises in opinion poll analysis. They lead the art of election prediction, especially the US presidential, through poll aggregation strategy.
Let us look at a poll aggregator methodology and how it forecasts better than individual pollsters. Take the 2012 US presidential election, in which Obama won against Mitt Romney by a margin of 3.9%. We approach it through a simplistic model and not necessarily what 538 might have done.
Assume Top-Rated Pollsters Got It Right
Let’s try and build 12 poll outcomes that came in the last week before the election. The sample sizes of each of these polls are 1298, 533, 1342, 897, 774, 254, 812, 324, 1291, 1056, 2172 and 516 – a total of 11269 (remember that number). We don’t know anything about the details of voter preference, but we assume all the posters got it right – the 3.9% margin.
Since we don’t have any details, we simulate the survey, starting with the first pollster, 1298 samples. The following R code gives preference to 1298 people with an overall 4% advantage for Obama over Romney.
The code mimics choosing 1298 items from an urn containing a large number of balls having two colours, one being more prevalent than the other by a 4% chance.
Now, we follow the step-by-step procedure as we did before
Number of samples – 1298
Calculate the mean – In one realisation, I get 0.534
Calculate the standard deviation and divide by the square root of the sample size. It’s 0.499/√1298 = 0.0139
Take a 95% confidence interval and assume a standard normal distribution. (0.534 – 1.96 x 0.0139) and (0.534 – 1.96 x 0.0139). 0.50 and 0.56.
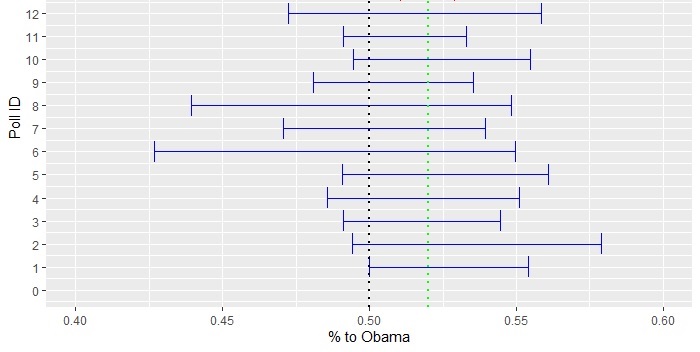
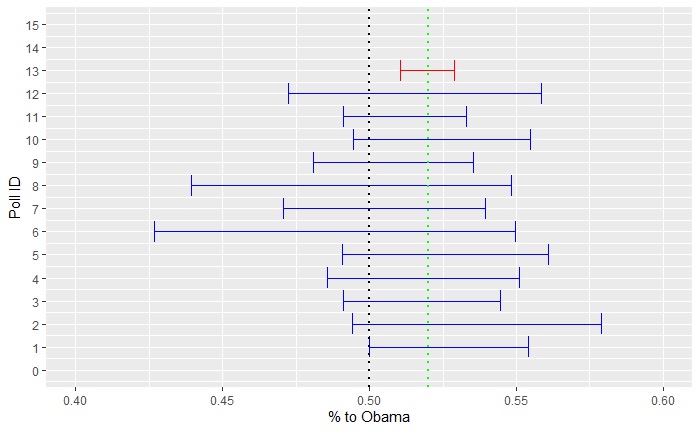
Repeat this for all the pollsters using their respective sample sizes but at a constant 4% margin on the win. One such realisation of all the 12 poles is presented below in the error plot.
Two features of the error bars are worth noting. First, the actual outcome, 0.52, is covered by every pollster. Second, all of them covered the toss-up (a crossing over 0.5) scenario. While the first point is expected 95% of the time (by definition), the second one is more frequent for surveys with fewer participants.
Now, use the aggregator technique. Suddenly, you have 11269 samples available. Repeat all the steps above, and you get, in realisation, 0.51 and 0.53. Include that in the main plot (red error bar), and you get the following:
For the aggregator, the confidence interval no longer covers a toss-up.
Advantages of Aggregator Strategy
The strength lies in the increased sampling size available to the aggregator. They also get the opportunity to select surveys that are known to be representative. For example, 538 provides a grading scheme to rate the quality of pollsters.
We have seen how survey methodologies based on the Central Limit Theorem work in forecasting. As you know already, CLT assumes three basic properties – independence, randomness, and the requirement to have the same underlying distribution. Together they are known as independent and identically distributed (i.i.d.).
The most common example of the system at work is election forecasting. Unlike the case with rolling dice or tossing coins, election forecasting is all about surveying the real world, and sometimes they go wrong. This time we examine some of the common reasons why the pollsters get it wrong.
Not Enough Samples
The simplest one is, of course, when there are too few numbers. You have seen that the spread of uncertainty is inversely related to the square root of the number of samples. I doubt it is a big concern; pollsters often choose sample sizes correctly, and the minimum number can be as few as 30.
Selection Bias
An example of selection bias was the calls via landlines for surveys during the US presidential polls in 2008 and 2012. Pew Research has found that the respondents of landlines, that too in the evening time when the pollsters typically make the call, were Republican-leaning. The opposite was true for cell phone users, who also happened to be the younger crowd and Obama supporters!
The second type of selection bias is also known as the house effect. Here the selection bias originates from the polling firms themselves. It happens when the polling firm has a favourite candidate and therefore publishes survey results that favour its liking.
Bradley Effect
Sometimes people simply lie, especially when their stands are at odds with socially accepted values. A classic case was in 1982 when the African-American candidate Tom Bradley, predicted to be the winner of the California governor’s race by exit polls, was lost. The respondents had clear racial preferences for the white candidate but did not want to admit that race played a role in their selection.
This one is going to be one heck of a post, so hold tight. We need to start with the central limit theorem, and you know it by now. It says that the distributions of some properties of surveys, such as sum or average, follow a normal distribution if the sampling is proper. Go to this post for a refresher. By the way, don’t you think that if the sum is a distribution, the ‘average’ is also a distribution? After all, the average is the sum over a constant, the number of members in a survey.
Let me list down a few things in preparation for the upcoming roller-coaster ride.
Population – everything; if you go and survey everybody, you don’t need anything else, end of the story. A country’s voting is done by all its population. The outcome has no uncertainty.
Sample – sub-set of the population; all your statistics wizardry is required on samples. An opinion poll is on a selected sample, a few potential voters, so there is uncertainty.
Mean – the average of measurements. The sample mean is what we get from each survey; finding the population mean is our task.
Standard Deviation – a mathematical way of getting the variation of data. Use sample or population as add-ons, as before.
Then, there are five notations: sample size is n, the population mean is mu (μ), the population standard deviation is sigma (σ), the sample mean is Xbar (X̄), and the sample standard deviation is S.
Your task is to get μ and σ using one or a set of X̄ and S. All you have with you is trust in the Central Limit Theorem that says the mean of the entire distribution of all X̄ values is μ, and the standard deviation of the distribution of X̄ is σ/√n.
Mathematical Manipulations
We know that X̄ shows a normal distribution (CLT). If you subtract a constant, the outcome is still a normal distribution. So we minus μ (we don’t know μ, but that doesn’t matter). Similarly, if you divide with a constant, the distribution is still normal, so we divide with σ/√n. The new distribution is uniform, but everything else has changed now. The new mean is 0 (remember: the mean of all survey results plotted as a distribution will coincide with the population mean). And the new standard deviation is 1 (because we divided it by the exact quantity). This distribution is known by a different name – the standard normal distribution, N (of the new variable Z).
Z forms a new normal distribution with mean = 0 and standard deviation = 1. Or N(0,1)
If That Holds
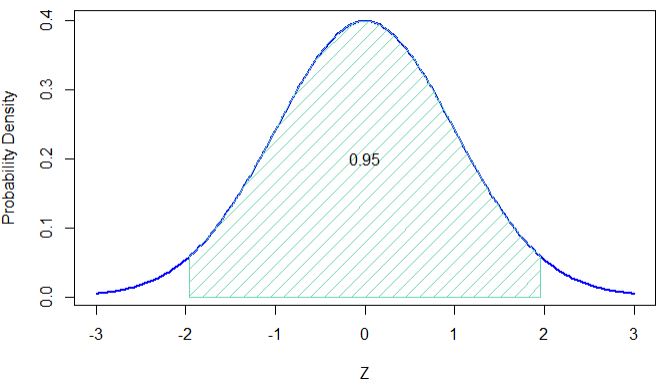
The probability that Z lies between -1.96 and +1.96 is 0.95, or 95%. If it were a normal distribution and we wanted to cover a distance of 2 times the standard deviation, shouldn’t it be plus or minus 2 and not 1.96? How did that happen? The answer is that we did not go for 2 sigma but a 95% interval. If you draw the standard normal distribution curve and check it, you will find that 95% of the distribution lies between -1.96 and +1.96.
3. If you know the population standard deviation, σ. σ = 2. Divide σ with √n = 2 / √100 = 2 / 10 = 0.2. If you don’t know σ, you have to use S, the sample standard deviation. Assume S is also 2, and you get S /√n = 0.2.
4. If you know the population standard deviation, Choose the confidence interval. In our case, it was 95%. So as per the previous section, it is -(1.96 x 0.2) and +(1.96 x 0.2). That is 5 – 0.392 and 5 + 0.392 or [4.96, 5.4], which is my 95% confidence interval.
Not Over Yet
5. If you do not know the population standard deviation, As before, choose the confidence interval, which is 95%. The new interval is not between +(1.96) and -(1.96) but on a modified range. The value 1.96 becomes a function of the sample size -1 (the degrees of freedom). For smaller sample sizes, the number increases. For n = 2, it can be as large as +/- 12.71! In short, it is no longer a standard normal distribution but a t-distribution.
But we are lucky as our n is 100 (and the degrees of freedom = 99), and the multiplication factor is 1.984. -(1.984 x 0.2) and +(1.984 x 0.2). That is 5 – 0.3968 and 5 + 0.3968 or [4.96, 5.4], which is my 95% confidence interval.