Bayes Factor – Continued
Let’s progress further the concept of Bayes Factor (BF). In the last post, the BF was defined in favour of the null hypothesis (BF01). From now on, we focus on BF10 or the Bayes factor in favour of the alternate hypothesis.
Bayes Factor10 = P(Data|H1) / P(Data|H0)
As per Bayes theorem:
P(H1|D) = [P(D|H1) P(H1)] / P(D)
P(H0|D) = [P(D|H0) P(H0)] / P(D)
[P(H1|D) / P(H0|D)] = [P(D|H1) P(H1)] / [P(D|H0) P(H0)]
[P(H1|D) / P(H0|D)] = [P(D|H1) / [P(D|H0)] [P(H1)] / P(H0)]
Posterior Odds = BF10 x Prior Odds
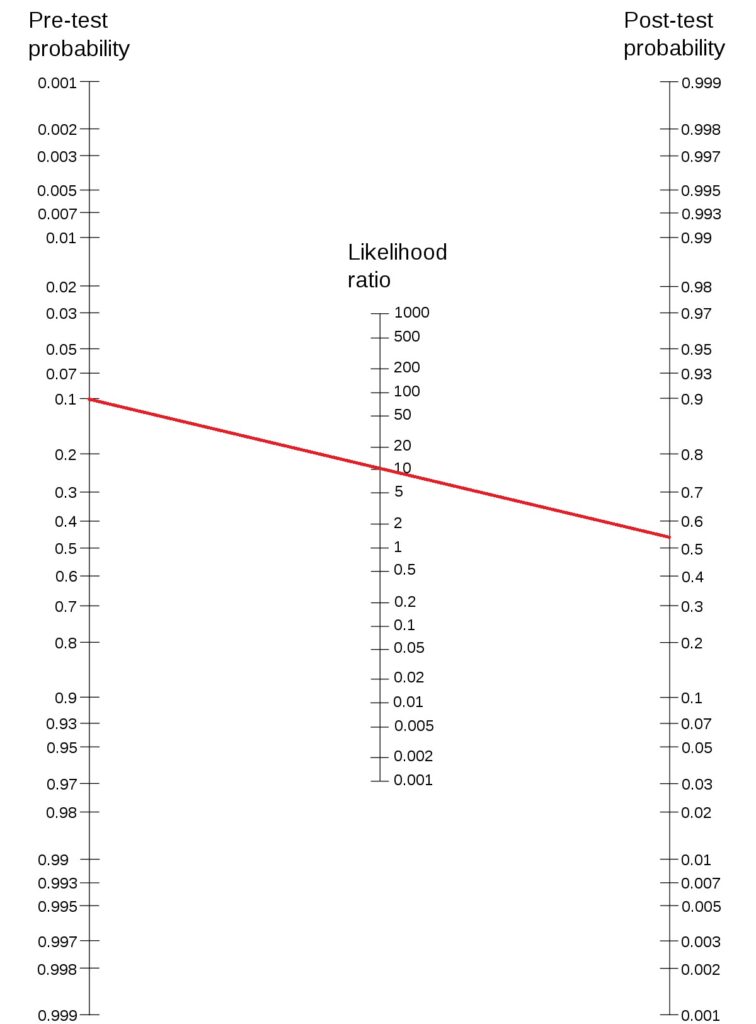
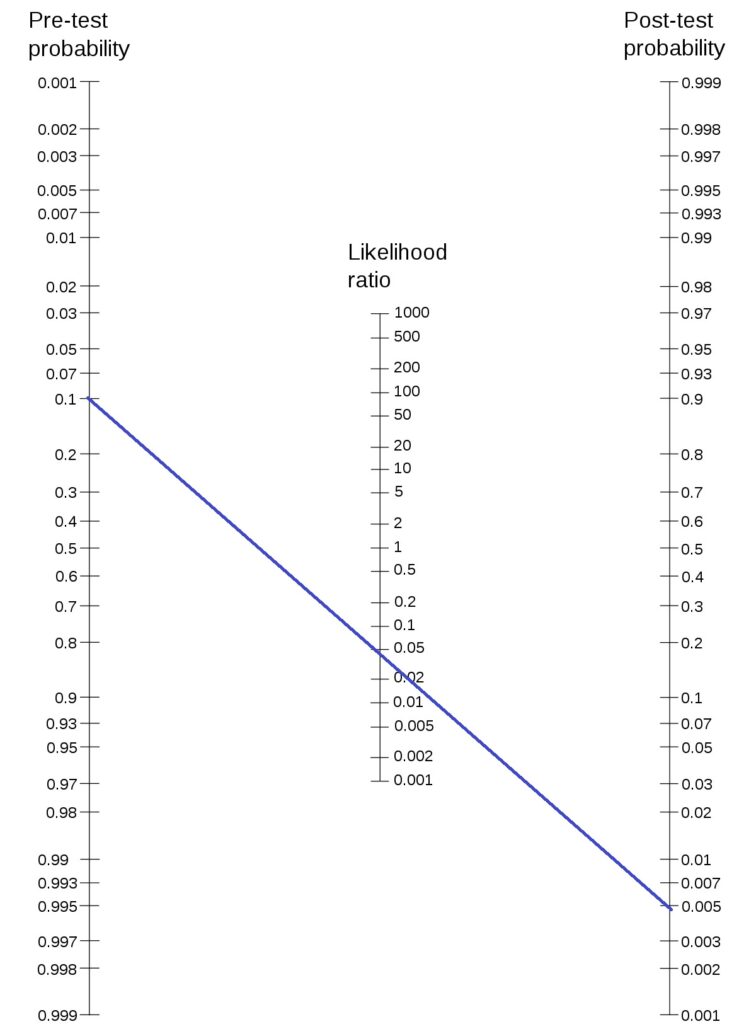
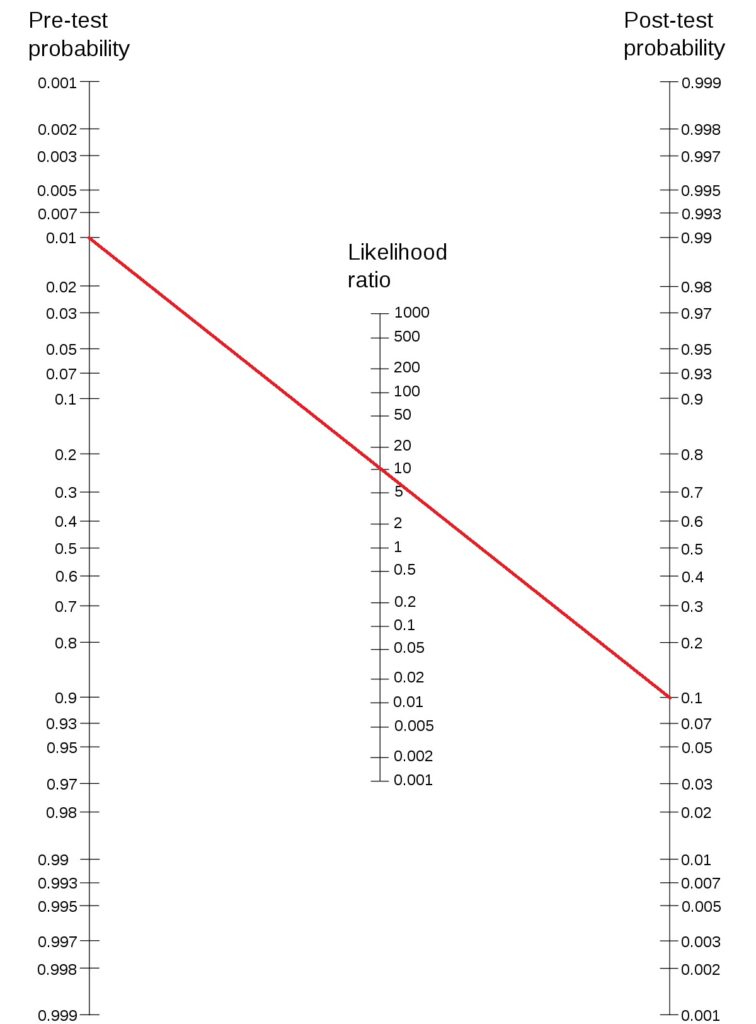
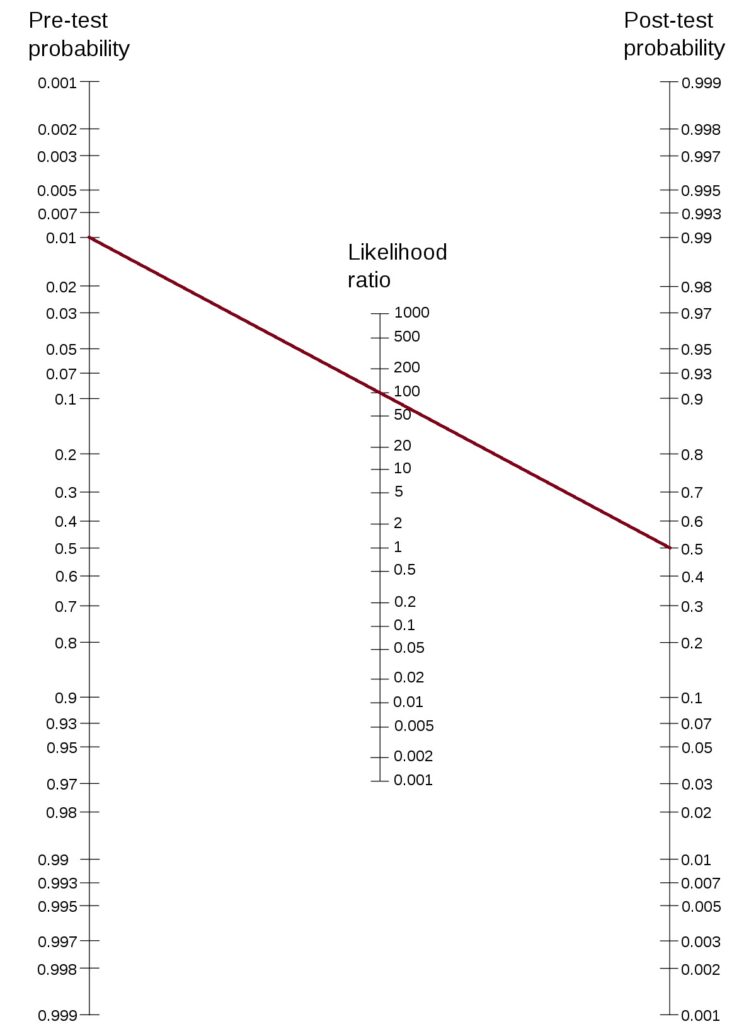
This definition is significant in determining the strength of the alternate hypothesis given the experimental data or P(H1|D). Note that an experimenter is always interested in it, but the traditional hypothesis testing and p-values never helped her to know it. Let’s see how it works:
Let the prior probability for your hypothesis be 0.25 (25%), which is 1:3 prior odds (note: P(H1) + P(H0) = 1 and P(H1|D) + P(H0|D) = 1). And the BF10 is 5, which is pretty moderate evidence and is not far from a p-value of 0.05. The posterior odds become 5:3 (P(H1|D) / P(H0|D)). This corresponds to a posterior probability for the alternate hypothesis (P(H1|D)) = 5/8 = 0.625 (62.5%).
So, a Bayes Factor of 5 has improved the prior probability of the hypothesis from 25% to 62.5%.
Bayes Factor – Continued Read More »