T&K Stories – 3. Biases of Imaginability
Consider a group of 10 people who form committees of k members, 2 < k < 8. How many different committees of k members can be formed?
Judgment under Uncertainty: Heuristics and Biases, Tversky and Kahneman
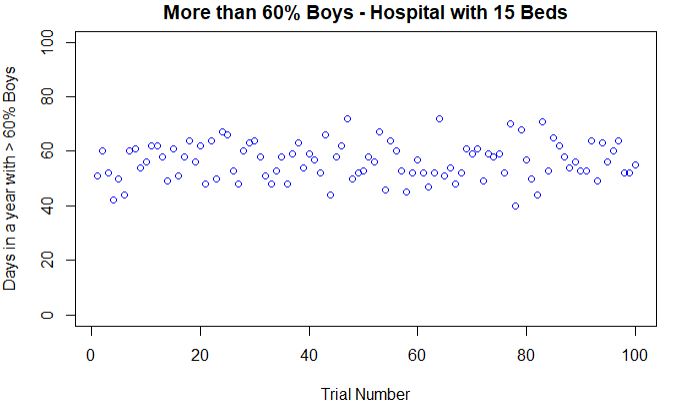
The third story from Tversky and Kahneman paper is about the role of imaginability in the estimation of probabilities. Consider this group of 10 people who form committees of a minimum of 2 up to a maximum of 8. To find how many possible ways to form teams, you need to apply what is known as Combinations, which is nothing but the binomial coefficient that you have seen earlier. i. e. Combinations of n things taken k at a time without repetition.
For 3-member teams, it comes out to be 10C3 or 120. The choice increases to the maximum for 5 (252 combinations), and then decreases symmetrically such that nCk = nCn-k (number of 3-member groups = number of 7-member groups and so on).
The following R code uses the function choose(n,k) to evaluate the binomial coefficient and plots the outcome.
committe <- function(n,k){
choose(n,k)
}
diff <- seq(2,8)
diff_com <- mapply(committe, diff, n = 10)
plot(x = diff, y = diff_com, main = paste("Number of Ways to form a Committee"), xlab = "Number of Individuals in the Committee", ylab = "Number of Combinations to Form a Committee", col = "blue", ylim = c(0,400))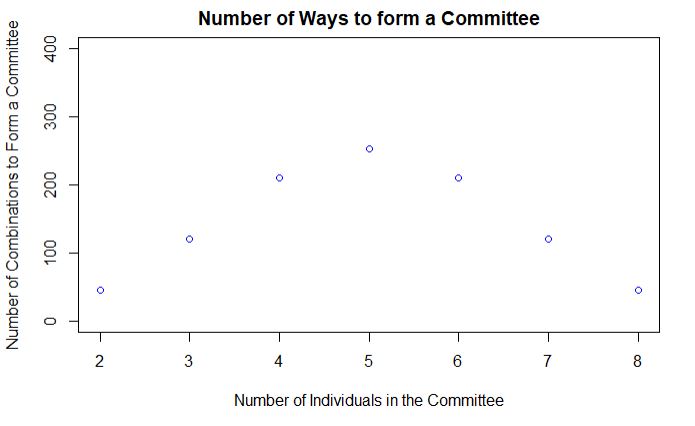
It requires number crunching, and mental constructs don’t always help. In a study, when people were asked to make guesses, the median estimate of the number of 2-member committees was around 70; 8-member committees were at 20. So, imagining a few two-member teams were possible in mind, whereas 8-member groups were beyond its capacity.
Tversky, A.; Kahneman, D., Science, 1974 (185), Issue 4157, 1124-1131
T&K Stories – 3. Biases of Imaginability Read More »