Martingale appears a compelling strategy to make money from the Roulette game. In the Martingale technique, you make an even-money (bottom row of the layout) bet. If successful, you win a unit profit (payoff is 1 to 1); end of the story. If you fail, you stay for another spin but double the wager, and you continue this pattern until you win. The argument is that if you play the game infinitely, the chances of repeated failure reach zero. That is a correct argument.
The opposite is also true – if you are on a losing track, withdrawing from the game or continuing on a reduced bet than required will result in losses. And that is what the casino will do. They put bet limits, say, at 500 dollars. That means, once your wager reaches above 500, you got to stay at 500, suggesting a loss of money even if you win from there onwards.
I will start the illustration with the first bet and win.
Try
Bet
Outcome
Spent
Gained
Profit
1
1
WIN
1
2
1
Imagine you lost the first spin, and as per Martingale strategy, you double the bet and continue at the same spot.
Try
Bet
Outcome
Spent
Gained
Profit
1
1
FAIL
1
2
2
WIN
3
4
1
This doubling bets each time appears like you double the potential profit also. But in reality, you exactly get the starting unit. Here is the illustration of winning after eight successive rounds of failure.
Try
Bet
Outcome
Spent
Gained
Profit
1
1
FAIL
1
2
2
FAIL
3
3
4
FAIL
7
4
8
FAIL
15
5
16
FAIL
31
6
32
FAIL
63
7
64
FAIL
127
8
128
FAIL
255
9
256
WIN
511
512
1
Once your doubling reaches above 500, you have to stay at 500, suggesting a loss of money even if you win from here onwards.
Try
Bet
Outcome
Spent
Gained
Profit
1
1
FAIL
1
2
2
FAIL
3
3
4
FAIL
7
4
8
FAIL
15
5
16
FAIL
31
6
32
FAIL
63
7
64
FAIL
127
8
128
FAIL
255
9
256
FAIL
511
10
500
WIN
1011
1000
-11
You will argue that losing nine rounds in a row is highly unlikely. That is true; after all, the probability of staying on the losing course for nine spins is (20/38)9 = 0.3%.
That is why the motivation for playing the game is crucial. If it is for fun and making a dollar or two, this makes a perfect strategy. However, if you want to make money by this strategy, you will see the odds of getting nine successive fail is no smaller. Suppose the wheel spins 200 times the chance of nine failures in a row is one in three (see the earlier post for the calculations). The nightmare possibility can come on the 9th or the 600th.
The other argument is to start with more than 1 unit, as at the end of the day, one dollar starting bet will only get you 1 dollar as profit. Imagine you start with 5 dollars. The table is below.
Try
Bet
Outcome
Spent
Gained
Profit
1
5
FAIL
5
2
10
FAIL
15
3
20
FAIL
35
4
40
FAIL
75
5
80
FAIL
155
6
160
FAIL
315
7
320
WIN
635
640
5
The trouble with this is that you approach your ceiling in seven spins, and you lose 135 even if you win the 8th round. Now, the probability of getting seven consecutive fail in 200 games is almost certain (100%)! An extreme case is putting the first bet at 500. If you fail the first time, the game is no more any strategy, as you have only one chance to recover or lose 1000.
Martingale Strategy is Fun
It is a strategy to have fun, test your probability models and earn a few dollars but not get rich. The doubling of bets gives a feeling of doubling the profit, but we have seen that the final gain is always equal to the initial bet and higher the initial, you reach the ‘ceiling’ faster. If you continue the excitement after a few successes (1 or 2 dollars), the odds will hit you and take away everything.
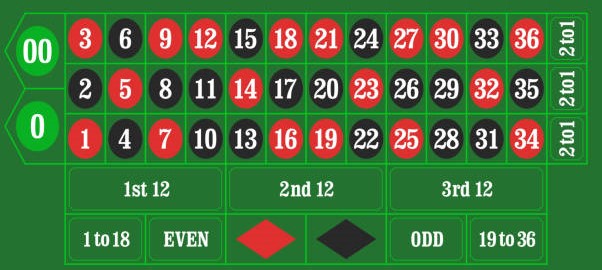
The rules of roulette appear complex, with so many types of bets and payoffs. We have seen the basic odds of roulette in an older post, and this time we spend time demystifying the complexity. First, look at the wheel (American roulette).
And the layout on which the player places the bet is:
Now, various possible bets and payoffs.
Bet
Explanation
numbers covered
Payoff
Straight
the bet covers a number
1
35 to 1
Split
bet on two adjacent numbers on the layout
2
17 to 1
Street
bet on a column of 3 numbers (e.g. 12, 11, 10)
3
11 to 1
Corner
any block of 4 numbers of 2 x 2 (e.g. 32, 35, 31, 34)
4
8 to 1
Basket
five number combination of 00, 0, 3, 2, 1
5
6 to 1
Double Street
2 adjacent columns of the layout; a bet covers 6 numbers
6
5 to 1
A dozen
1-12, 13-24 or 25-36, by placing a bet on one of the 3 locations of the layout
12
2 to 1
Even-money
odd/even, red/black, low (1-18), high (19-36)
18
1 to 1
Now, forget everything and let’s find out how payoffs are made, and what the expected values are.
Expected Value, E
The expected value of a random variable is a weighted average. In other words, you take the value of each variable, multiply it by its probability to occur and sum over all the variables. Imagine a coin-tossing game – you get one dollar for a head and lose 1 for a tail. The outcomes hear and tails, are random variables, each with a chance of 1 in 2 (0.5). So, the expected value = P(H) x V(H) + P(T) x V(T) = (1/2)x(1) + (1/2)(-1) = 0. Or, if you play the game over and over, you are expected to gain (or lose) nothing, but you should play for a long time to see that outcome. I have used V to denote value.
Another example: you play 6-sided dice. You get 6 dollars if the dice rolls on 3, and lose 1 dollar for everything else. The expected value (if you play long enough) is E = (1/6)(-1) + (1/6)(-1) + (1/6)(6) + (1/6)(-1) + (1/6)(-1) + (1/6)(-1) = (6/6) – (5/6) = 1/6. So, keep playing.
Roulette
We have seen how it works in Casino games. We will formalise it this time. Look carefully at the last two columns of the bet-payoff table, and you can make a formula payoff = (36 – numbers covered ) / numbers covered. The formula holds good except for Basket, where the answer is (36-5)/5 = 6.2, but the casino rounds it off to 6 (benefits who?).
Let N be the number of pockets on the wheel (38 for American and 37 for European), and n be the number covered. The chance of getting one number from 38 possibilities is (1/38). The probability of getting one out of two numbers (such as a split) is (1/38) + (1/38) = 2/38 – remember the addition rule of mutually exclusive events? So the generalised formula for getting one number in a bet that covers n numbers is n/38, and the expected value is
There is something special about the final equation – that it is independent of the numbers covered but depends only on the number of pockets on the roulette wheel. In other words, if the game has a smart payoff structure given by a formula (36 – numbers covered ) / numbers covered, you get a bet-independent payoff (or a constant payoff).
House wins, always
We will plug in numbers and find out the advantage – you already know it’s a house advantage for any N more than 36. So for the American, it is (36-38)/38 = – 0.0526 or 5.26%; for the European, it is (36-37)/37 = – 0.027 or 2.7%. The Basket doesn’t exactly fit the rule, and its house advantage is higher at 7.89%.
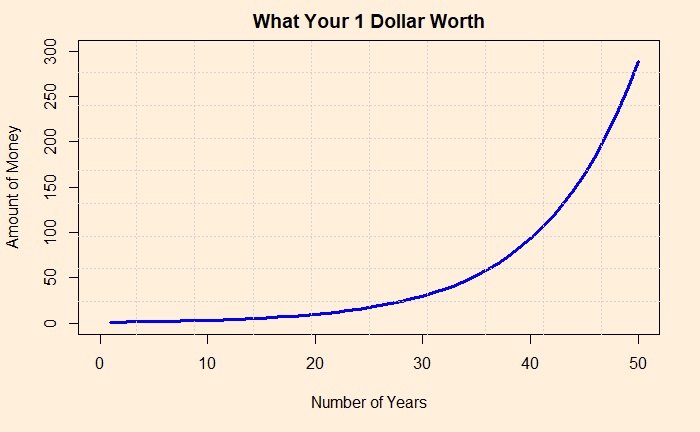
The rule of compounding is in the following manner. Your money is on the y-axis, and the number of years you have invested in is on the X. Here, you invested 1 dollar and fetched average yearly returns of 12%.
Read the conditions
Each number is important. Read the conditions regarding the fees to enter and exit a scheme. Do you want to know the price you pay for not doing it? Read the next section.
If you allow 2% to go, you lose 60%
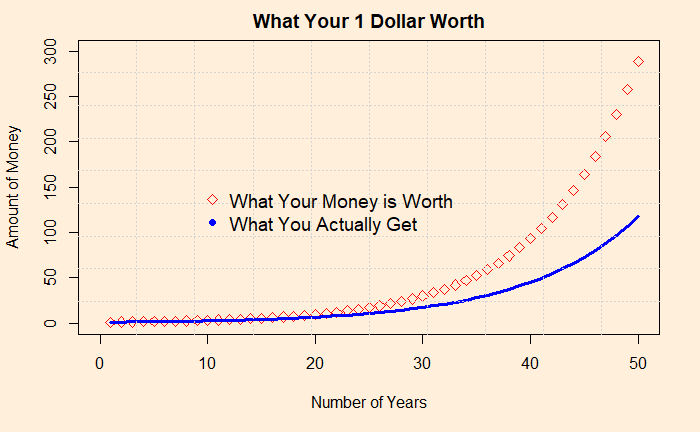
You have a product that can give a 12% annual return from two sources: 1) takes no expense ratio and 2) takes a 2% expense ratio. Take the one with no expense ratio. In India, this means buying direct mutual funds and not regular ones. Look what happens to an investment worth 12% (red diamonds) and the one with 2% subtracted.
At the end of the 50th year, your one dollar is worth 289, yet you get 117! Where did the rest go?
Trust the plots above
or remember the formula of compounding
Most financial advisors are just agents
who have conflicts of interest.
In summary, do the scheme of your choice, not the agent’s. Remember the rule of compounding.
Testing programs are not about machines but the people behind them.
We get into the calculations straight away. The equations that we made last time are:
Before we go further, let me show the output of 8 scenarios obtained by varying sensitivity and prevalence.
Case #
Sensitivity
Specificity
Prevalence
Chance of Disease for +ve (%)
Missed in 10000 tests
1
0.65
0.98
0.001
3
4
2
0.75
0.98
0.001
3.6
2.5
3
0.85
0.98
0.001
4
1.5
4
0.95
0.98
0.001
4.5
0.5
5
0.65
0.98
0.01
24
36
6
0.75
0.98
0.01
27
25
7
0.85
0.98
0.01
30
15
8
0.95
0.98
0.01
32
5
Chance of Disease for +ve = probability that a person is infected given her test result is positive. Missed in 10000 tests = the number of infected people showing negative results in every 10,000 tests.
Note that I fixed specificity in those calculations. The leading test methods of Covid19, RT-PCR and rapid Antigen are both known to have exceptionally low false-positive rates or specificities of close to 100%.
Now the results.
Before the Spread
It is when the prevalence of the disease was at 0.001 or 0.1%. While it is pretty disheartening to know that 95% of the people who tested positive and isolated did not have the disease, you can argue that it was a small sacrifice one did for society! The scenarios of low prevalence also seem to offer a comparative advantage for carrying out random tests using more expensive higher sensitivity tests. Those are also occasions of extensive quarantine rules for the incoming crowd.
After the Spread
Once the disease has displayed its monstrous feat in the community, the focus must change from prevention to mitigation. The priority of the public health system shifts to providing quality care to the infected people, and the removal of highly infectious people comes next. Devoting more efforts to testing a large population using time-consuming and expensive methods is no more practical for medical staff, who are now required at the patient care. And by now, even the highest accurate test throws more infected people into the population than the least sensitive method when the infection rate was a tenth.
Working Smart
A community spread also rings the time to switch the mode of operation. The problem is massive, and the resources are limited. An ideal situation to intervene and innovate. But first, we need to understand the root cause of the varied sensitivity and estimate the risk of leaving out the false negative.
Reason for Low Sensitivity
The sensitivity of Covid tests is spread all over the place – from 40% to 100%. It is true for RT-PCR, even truer for rapid (antigen) tests. The reasons for an ultimate false-negative test may lie with a lower viral load of the infected person, the improper sample (swab) collection, the poor quality of the kit used, inadequate extraction of the sample at the laboratory, a substandard detector of the instrument, or all of them. You can add them up, but in the end, what matters is the concentration of viral particles in the detection chamber.
Both techniques require a minimum concentration of viral particles in the test solution. Imagine a sample that contains lower than the critical concentration. RT PCR manages this shortfall by amplifying the material in the lab, cycle by cycle, each doubling the count. That defines the cycle threshold (CT) as the number of amplification cycles required for the fluorescent signal to cross the detection threshold.
Suppose the solution requires a million particles per ml of the solution (that appears in front of the fluorescent detector), and you get there by running the cycle 21 times. You get a signal, you confirm positive and report CT = 21. If the concentration at that moment was just 100, you don’t get a response, and you continue the amplification step until you reach CT = 35 (100 x 2(35 – 21) – 2 to the power 14 – is > 1 million). The machine suddenly detects, and you report a positive at CT = 35. However, this process can’t go forever; depending on the protocols, the CT has a cut-off of 35 to 40.
On the other hand, Antigen tests detect the presence of viral protein, and it has no means to amplify the quantity. After all, it is a quick point of care test. A direct comparison with the PCR family does not make much sense, as the two techniques work on different principles. But reports suggest sensitivities of > 90% for antigen tests for CT = 28 and lower. You can spare a thought at the irony that an Antigen test is sensitive to detect the presence of the virus that the PCR machine would have taken 28 rounds of amplification. But that is not the point. If you have the facility to amplify, why not use it.
The Risk of Leaving out the Infected
It is a subject of immense debate. Some scientists argue that the objectives of the testing program should be to detect and isolate the infectious and not every infected. While this makes sense in principle, there is a vital flaw in the argument. There is an underlying assumption that the person with too few counts to detect is always on the right side of the infection timeline – in the post-infectious phase. In reality, the person who got the negative test in a rapid screening can also be in the incubation period and becomes infectious in a few days. They point to the shape of the infection curve, which is skewed to the right, or fewer days to incubate to sizeable viral quantity and more time on the right. Another suggestion is to test more frequently so that the person who missed due to a lower count comes back for the test a day or two later and then caught.
How to Increase Sensitivity
There are a bunch of activities the system can do. The first in the list is to tighten the quality control or prevent all the loss mechanisms from the time of sampling till detection. That is training and procedures. The second is to change the strategy from analytical regime to clinical – from random screening to targetted testing. For example, if the qualified medical professional identifies patients with flu-like symptoms, the probability of catching a high-concentrated sample increases. Once that sample goes to the testing device for the antigen, you either find the suspect (covid) or not (flu), but it was not due to any lack of virus from the swab. If the health practitioner still suspects, she may recommend an RT PCR, but no more a random decision.
In Summary
We are in the middle of a pandemic. The old ways of prevention are no more practical. Covid diagnostics started as a clinical challenge, but somewhere along the journey, that shifted more to analytics. While test-kit manufacturers, laboratories, data scientists and the public are all valuable players to maximise the output, the lead must go back to trained medical professionals. A triage system, based on experiences to identify symptoms and suggested follow up actions, is a strategy worth the effort to stop this deluge of cases.
Last time we set the objective: i.e. to find the posterior distribution of the expected value, from a Poisson distributed set of variables using a Gamma distribution of the mean as the prior information.
Caution: Math Ahead!
So we have a function and a prior. We will obtain the posterior using Bayes’ theorem.
The integral in the denominator will be a constant. Therefore,
Look at the above equation carefully. Don’t you see the resemblance with a Gamma p.d.f, sans the constant?
End Game
So if you know a prior gamma, you can get a posterior gamma based on the above equations. Recall the table from the previous post. The Sum of xi is 42000 and n is 7. Assume Gamma(6000,1) as a prior. This leads to a posterior of Gamma( 48000,8). Mean = 48000/8 and variance = 48000/82. The standard error becomes the square root of variance divided by the square root of n.
Expanding the Prior Landscape
Naturally, you may be wondering why I chose a prior that has a mean of 6000, or where I got that distribution from etc. And these are valid arguments. The prior was arbitrarily chosen to perform the calculations. In reality, you can get it from several sources – from similar shops in the town, scenarios created for worst (or best) case situations and so on. Rule number one in the scientific process is to challenge, and two is to experiment. So, we run a few cases and see what happens.
Imagine you come up with a prior of Gamma(8000,2). What does this mean? A distribution with a mean of 4000 and a variance of 2000 (standard deviation 44). [Recall mean = a/b; variance = a/b2 ]. The original distribution (Poisson) remains the same because it is your data.
Take another, Gamma(8000,1). A distribution with a mean of 8000 and a variance of 8000 (standard deviation 89).
Yes, the updated distributions do change positions, but they still hang around the original (from own data) probability density created by the Poisson function.
You may have noticed the power of Bayesian inference. The prior information can change expectations on the future yet retain the core elements.
Do you remember the shopping mall example? The one which attracts about 6000 customers a day? Now your task is to establish an expected value, the number of customers in a given day, and a confidence interval around it. You have the customer visits from the previous week as a reference.
Day
Number of Visitors
Monday
6023
Tuesday
6001
Wednesday
5971
Thursday
6045
Friday
5970
Saturday
5950
Sunday
6040
The simplest way is: find out the mean, assume a distribution, and calculate the standard error. Let’s do that first. Since the number of visitors is counts, and we think their arrivals are random and independent (are they?), we choose to use Poisson distribution. Average of all those numbers give 6000, so it is
In English, it meant: for fetching the distribution of counts at a given average (mu), we decided to use a Poisson distribution with a parameter mu.
The advantage of using the Poisson is that we can now get the variance easily. For Poisson, the mean and variance are both the same, equal to mu = 6000. Therefore,
Bayesian Statistics
By now, you may have sensed that the best way to capture the uncertainties of customer visits is to consider the average too as a variable. After all, the present mean (6000) is just from a week’s data. Since the average is no more limited to integers but can also be fractions, we go for continuous distributions such as Gamma distribution to represent. In other words, a distribution of mu is my prior knowledge of average. And our objective is to get the updated mu or the posterior. So we are finally at the Baysian space for distributions or Bayesian statistics.
In Summary
You use the prior knowledge of the expected value (or average) through a Gamma distribution and apply it to the variable defined by a Poisson distribution. No marks for guessing: the posterior will be a Gamma! We will complete the exercise in the next post.
Last time I’ve argued that Bayes’ technique of learning by updating knowledge, however ideal it is, is not the approach most of us would follow. This time we will see a Bayesian approach that we do, albeit subconsciously, in judging performances. For that, we take the example of Baseball.
Did Jose Iglesias appear to beat the all-time MLB record, which was more than a century-old, when he started the 2013 season with nine hits in 20 bats? His batting average in April was 0.45, with another 330 more batting to go! To most people who knew the historical averages, Jose’s performance might have appeared as a beginner’s luck!
Hierarchical model
One way to analyse Jose’s is using the technique we have used in the past, also known as frequentist statistics. By calculating the mean at the end of April, standard deviation and confidence interval. But we can do better using the historical average as prior data and following the Bayesian approach. Such techniques are known as hierarchical models.
The hierarchical models get the name because the calculations take multiple steps to reach the final estimate. The first level is player to player variability, and the second is the game to game variability of a player.
What we need to predict using the hierarchical model is Jose’s batting average at the end of the season, given that he has hit 45% in the first 20. By then, Jose’s average would be a dot on a larger distribution, the probability distribution of a parameter p (a player’s success probability for this season, but we don’t know that yet), and we assume a normal distribution. We will take the expected value of p or the average to be 0.255, last season’s average, with a standard error (SE) of 0.023 (there is a formula to calculate SE from p). By the way, SE = standard deviation / (square root of N).
Taking beginner’s luck seriously
Jose batted the first 20 at an average of 0.45, and we estimate the standard error of 0.111, as we do for any other probability distribution. If the MLB places its player averages on a normal distribution, Jose today is at the extreme right on 0.45, or an observed average of Y. Its expected value is 0.255!
In our shorthand notation, Y|p ~ N(p, 0.111); we don’t know what p is, but it is more like the probability of success of a Bernoulli trial.
Calculate Posterior Distribution
The objective is to estimate E(p), given that the player has an average Y and standard error SE. The notation is E(p|Y). We express this as a weighted average of all players and Jose. E(p|Y) = B x 0.255 + (1-B) x 0.45, where B is a weightage factor calculated based on the standard errors of the player and the system. B = (0.111)2 /[(0.111)2 + (0.023)2]. As per this, B -> 1 when the player standard error is large and B -> 0 if it is small. In our case B = 0.96. It is not surprising if you look at the standard error of Jose’s performance, which is worse than the overall historical average, simply because of the smaller number (20) of matches he played in 2013 compared to all players in the previous season.
So E(p|Y=0.45) = 0.96 x 0.255 + (1-0.96) x 0.45 = 0.263. This is the updated (posterior) average of Jose.
We have seen Bayes’ theorem before. It is a way of updating the chance of an event to occur based on what is known as a prior probability. Check the formula, in case you forgot it because we will use it again.
We do an exercise to illustrate today’s storyline, courtesy – a course in Bayesian statistics run by the University of Canterbury. You learn about a café in town. The shop has two baristas, one experienced and one less experienced. You also came to know that the experienced makes excellent coffee 80% of the time, good coffee 15% and average coffee 5% of the time. For the less experienced, the performance stats are 20%, 50% and 30%, respectively. Your task is to go to the cafe, order, enjoy the coffee and identify the barista.
You order a cup of coffee and find it an excellent one. Is this prepared by A? Let’s use Bayes’ equation. But, where do you start? You need a prior probability to begin. One way is to assign a 50-50 chance of encountering A on that day. Another way is to use your knowledge about the workdays per week, which sounds better than 50-50.
The chance that A made your coffee, given that it was an excellent coffee: P(A|E) = 0.8 x (5/7) / [0.8 x (5/7) + 0.2 x (2/7)] = 0.90
There is a 90% chance that A prepared your coffee. In other words, the initial estimate of (5/7), based on the work pattern, is updated to a higher value.
You got time to spend on another cup of coffee, and it turned out to be an average one! Now you update your estimate using the following calculation, = 0.05 x (0.9) / [0.05 x (0.9) + 0.3 x (0.1)] = 0.625
Note that the new prior probability is 0.9 and not 5/7. The updated chance (also known as the posterior probability) is still in favour of A but reduced from 90% to 63%.
The true scientist in you tries another coffee, and the outcome was an excellent coffee, and the updated chance is now 87%. At this stage, you decided to end the exercise and conclude that the barista of that day was the experienced one.
Natural Learning Process
This process of updating knowledge based on new information is considered by many as natural learning. I would view this as the ideal learning process, which rarely happens, naturally. In real life, most of us like to carry on the baggage of knowledge – be it from our parents, peers or other dogmatic texts, and resists every opportunity to update. In other words, you ignore new information or the information that does not tally with the existing.
In my opinion, scientific training is the only way to counter the tendency to carry on the baggage. The evidence-based worldview is not natural and needs forceful cultivation.
Back to Café
In the barista story, you may be wondering why the process repeated a few times, and the enquirer settled for a lower probability than what occurred after the first cup. To get the answer, consider the exact three cups of coffee but in a different order, say the average one first. What difference do you see?
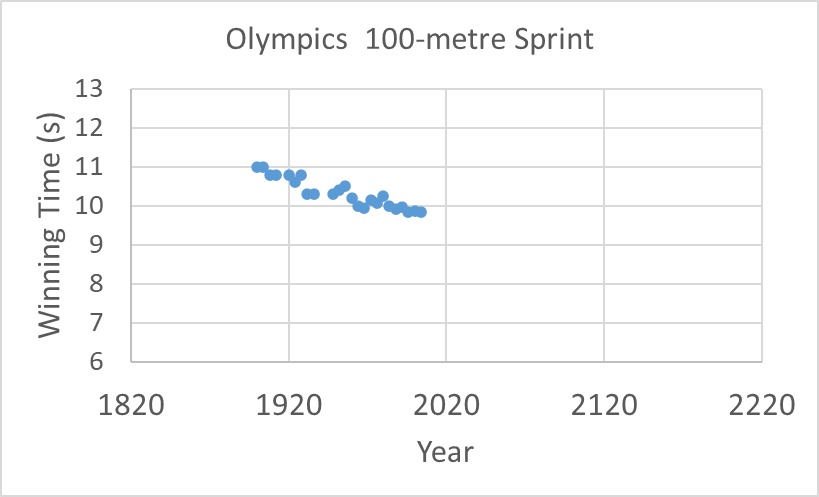
An ever-improving linear progression of sprint timings? Then what is your forecast, say, in the year 2200 or the year 2800?
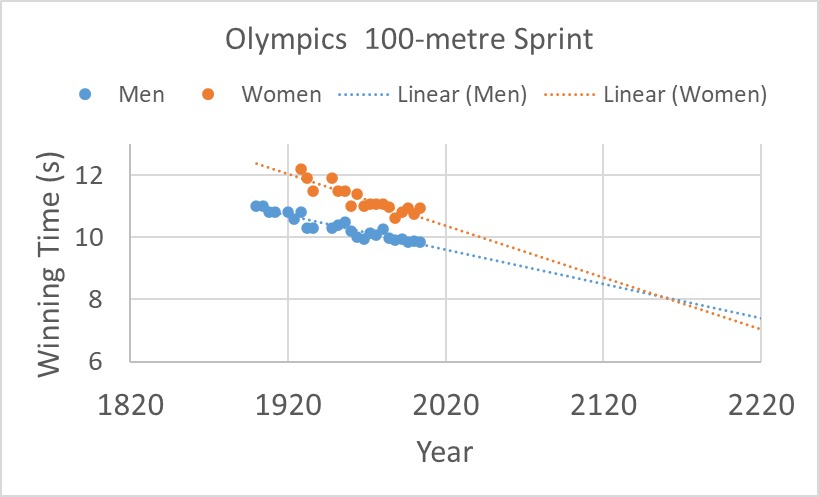
It was what happened in 2004 when a group of researchers published in the prestigious science journal nature. The article was titled, Momentous Sprint at the 2156 Olympics?: Women Sprinters are Closing the Gap on Men and May One Day Overtake Them! The study plotted men’s and women’s winning timings in Olympic 100-sprints and extrapolated to the future, similar to what I reproduced below:
And the result? A mockery of a publication in the most coveted journal in science.
The Straight Line Instinct
It is an example of what is known as the straight-line instinct, a term coined in the book Factfulness by Hans Rosling. Rosling talks about the general tendency of people to extrapolate things linearly without any regard to actual physics (or biology). Straight-line thinking is very natural to human beings. That is how we escape from a stone thrown straight at us or avoid hitting a pedestrian crossing the road ahead of us while driving.
What is Wrong with the Analysis?
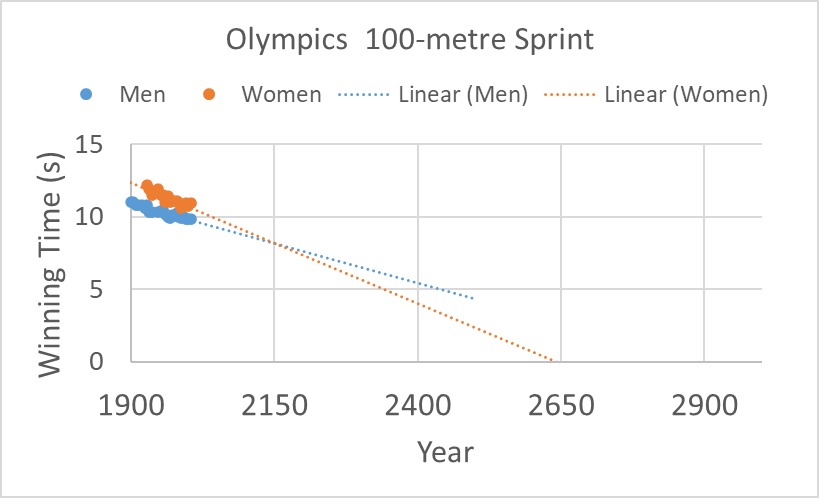
First, they should have done a sanity check, especially after seeing the outcome. Some alarm bells ought to have rung not just after seeing women sprinters crossing men in the future, but more importantly at the prospect of humans crossing the 100-metre mark in zero time on extrapolating the graph even further.
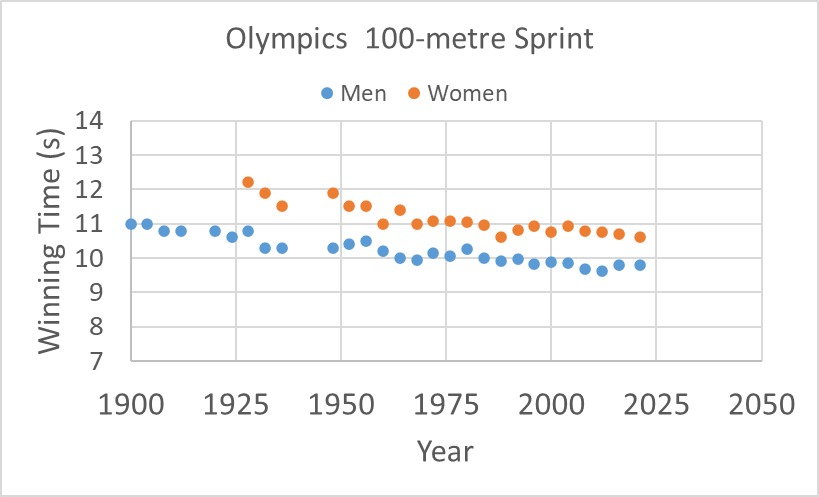
Second, they did the crime of collecting a few data covering about 100 years and extrapolated over another 200. Third, they ignored the science of athletic training, early improvements and subsequent plateauing of human performance. It is like a baby in the growing phase. If you look closely, the women’s event in the Olympics started about 25 years after the men’s. So, the massive early improvements in timing lagged for many years.
Before we close, let us have a final look at the data updated to the latest Olympics that happened in 2021.
This time we discuss another story from the paper of Tversky and Kahneman – about the biases originating from our inability to make adjustments from an initial value. In other words, the initial value anchors to our head.
To illustrate this bias: the following expressions were given to two groups of high-school students to estimate in 5 seconds. to the first group: 1 x 2 x 3 x 4 x 5 x 6 x 7 x 8 to the second group: 8 x 7 x 6 x 5 x 4 x 3 x 2 x 1
The median estimate for the first group was 512, and that of the second was 2250 (the correct answer is 40320)!
Our Estimation of Success and Risks
Overestimation of benefits and underestimation of downsides are things we see every day. On the one hand, it was necessary for us, as a species, to make progress, yet it could seriously land in failure to deliver quality products in the end.
Conjunctive Events
Imagine, the success of a project depends on eight independent chances, each with 95% probability (almost a pass for each!). So overall, the project has (0.95)8 = 66% chance of success. Often people overestimate this as the number 0.95 gets them into a belief of surety of success. These are conjunctive events, where the outcome is a joint probability or conjunction with one other.
Disjunctive Events
A classic case of a disjunctive event is the estimation of risk. Each stage of your project has a tiny probability, about 5%, that can stop the business. What is the overall risk of failing? You know by now that you can’t multiply all those tiny numbers, instead estimate the chance not to lose in any step and then subtract it from 1. (1 – (0.95)8) = 33%. You don’t finish in one out of three cases. People underestimate risks because the starting point appears too small to be significant.