Reaching one hundred days is a milestone. The general focus of my posts over these days, and also likely in the near future, has been about understanding risks, differentiating them from perceived risks and making decisions in situations of uncertainty using prior information, also known as Bayesian thinking. It started from the misery of seeing how the responsible agents of society -journalists, the political leadership, or whoever influences the public – ignore critical thinking and present a distorted view of reality.
Probability and evolution
A subplot that is closely associated with probability and randomness is the topic of evolutionary biology. It is hard to comprehend, yet the truth about life is that it moved from one juncture to another through chance. Evolution is misleading if you view the probability from hindsight. Changes happen through random errors, but one at a time, so that every step in the process is a high-probability event. Indeed, getting an error at a specified location during the body’s 30 trillion cell divisions is close to zero, but getting one at an unspecified somewhere is close to one. In other words, the designer has deeper trouble explaining a move than a drunken gambler!
Biases and fallacies
Next up is our biases and fallacies. The title of this post already suggests two of them – survivorship bias and the fallacy of hindsight. The probability of delivering an uninterrupted string of 100 articles in 100 days is small, and I would never have chosen the present title had I missed a post on one of these days. Now that it happened (luck, effort or something else), I claim I’ve accomplished a low-probability event. As long as I have the power to change the blog title until the last minute, I am fine. But scheduling a post today, for 100 days from now, with a caption of 200 days, is risky and, therefore, not a wise thing to do if you are risk-averse.
Deteminism or probability
Why does the subject of probability matter so much when we can understand physical processes in a deterministic sense? We grew up in a deterministic world, i.e. a world that taught us about actions and reactions, causes and effects. However, we also deal with situations where the outcomes are uncertain, which is the realm of probability. The impact of lifestyle on health, growth of wealth in the market, action of viruses on people with varying levels of immunity, the possibility of earthquakes, droughts, the list is endless. You can argue that the complexity of variables and the gaps in the understanding demand stochastic reasoning.
Updation of knowledge and Bayesian thinking
However imperfect it may be, Bayesian thinking is second nature to us. You are watching an NBA match in the last seconds, and your team is trailing by a point. Your team gets two free throws. What is in your mind when Steph Curry comes in for those? Contrast that with Ben Simmons. It is intuitive Bayesian thinking. It is not a surprise that you are more at ease with Curry’s 91% success rate in free throws than Ben, who is at 60%. You may not remember those numbers, but you know it from gut feeling.
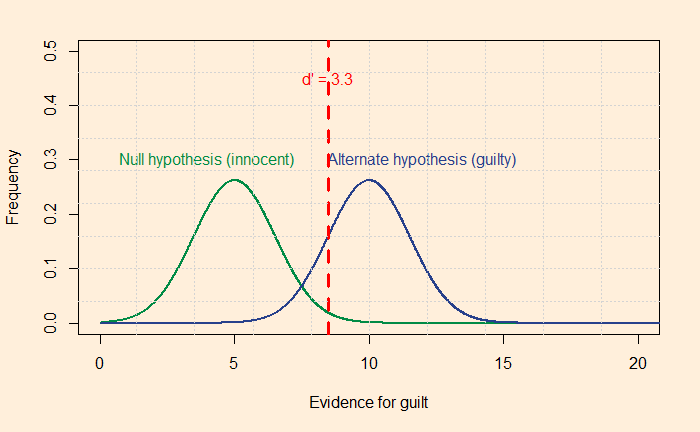
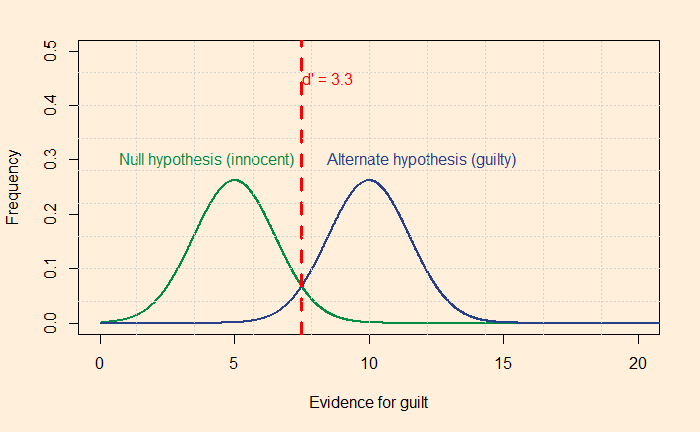
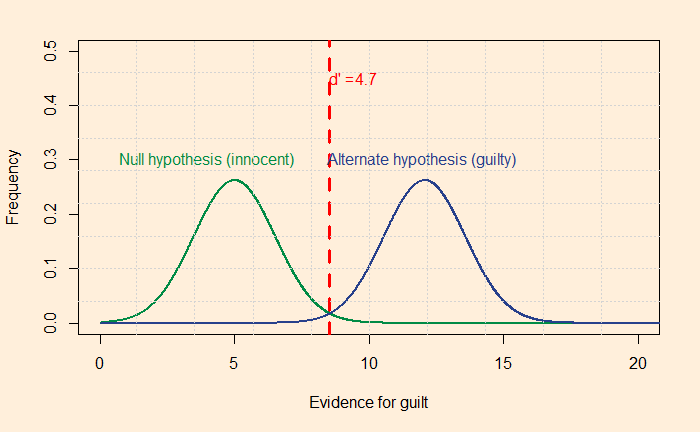
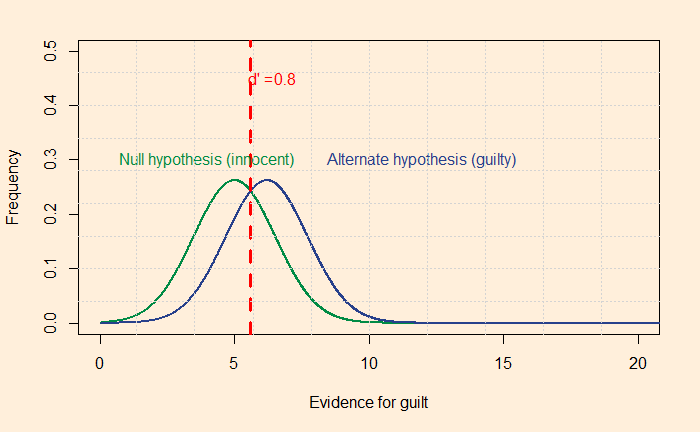
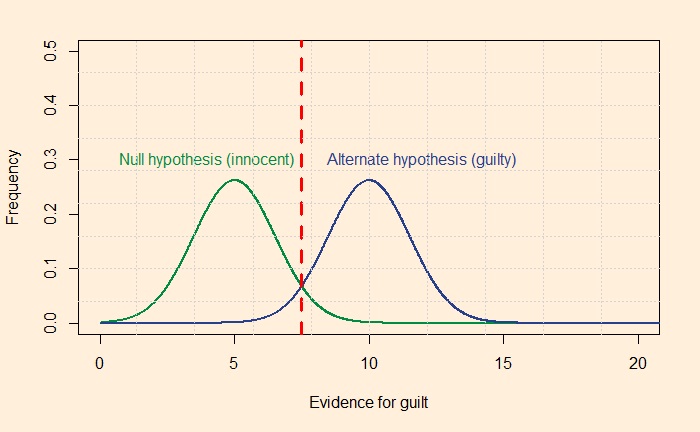
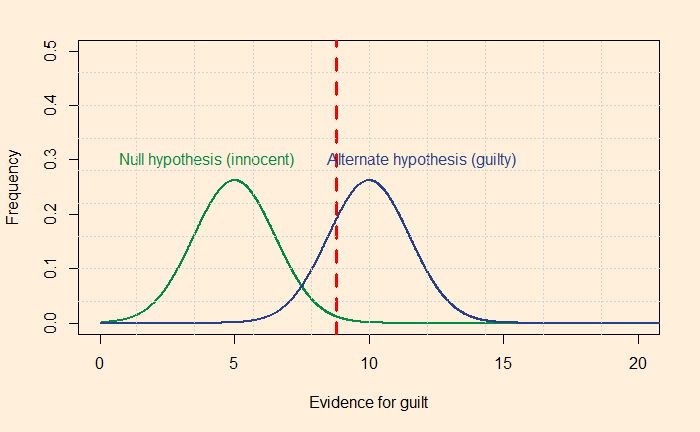
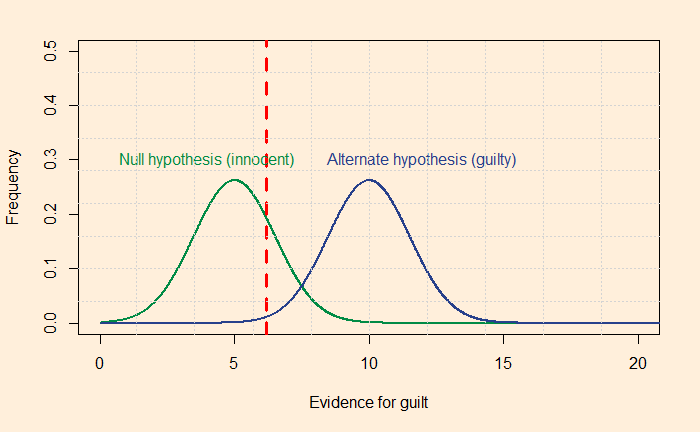
Yet, being rational requires constant training. Your innate Baysian is too vulnerable to biases and fallacies. You start missing the base rates, confuse the hypothesis given the evidence with evidence given the hypothesis, or overestimate the prior due to recency bias. Surviving the sea of probability is hard, fighting the wind of lies and the sirens of misinformation. So what do you prefer, put wax in the ears, tie tight to the mast or get the rational power, listen to the music, and persist the voyage?