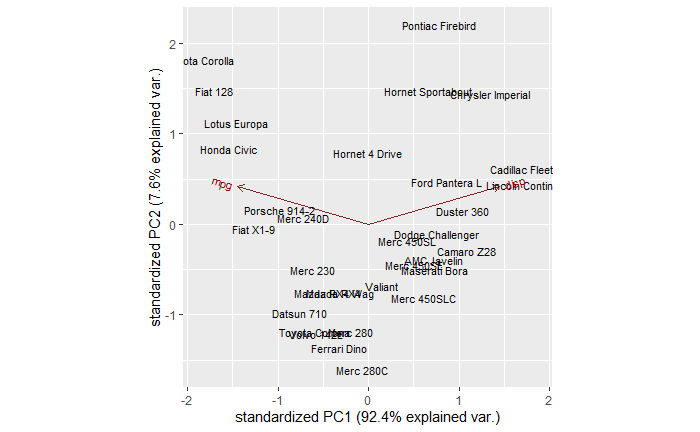
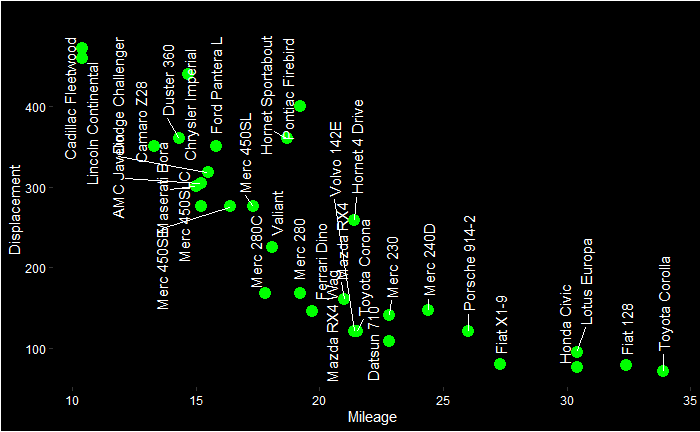
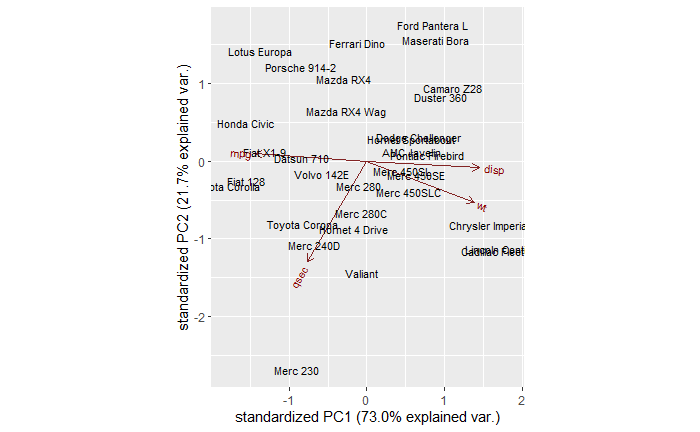
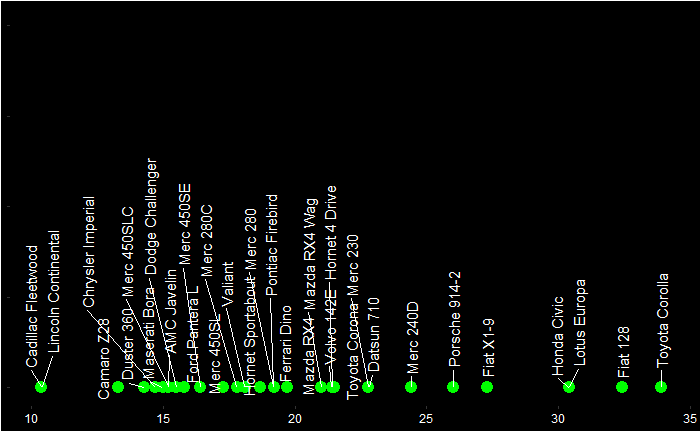
Representativeness Heuristics
Heuristics are mental shortcuts or straightforward rules of thumb, often developed from past experiences, used to make quick decisions. While it helps enormously to cut down time and effort to make decisions – decisions are taxing to the brain – occasionally, it can also lead to troubles. For example, a popular heuristic, the availability bias, makes us think that we live in an era of violence more than ever before, thanks to the day-to-day images we see in the media.
Here, we look at another one – the representativeness heuristics. The best way to describe it is:
“If it looks like a duck, swims like a duck, and quacks like a duck, then it probably is a duck”.
In representativeness heuristics, when compelled to make a decision, one compares herself with a prototype (or stereotype) of an event or behaviour she already has in mind.
In the famous Linda’s Problem, the image of a girl who participates in a demonstration drives us to tag her as a feminist.
A known example with more serious implications is racial profiling. It is when the police search for a crime suspect or an airport security officer doing random checks disproportionately focus on blacks or people of colour.
Representativeness Heuristics Read More »