Parametric vs Non-Parametric Tests
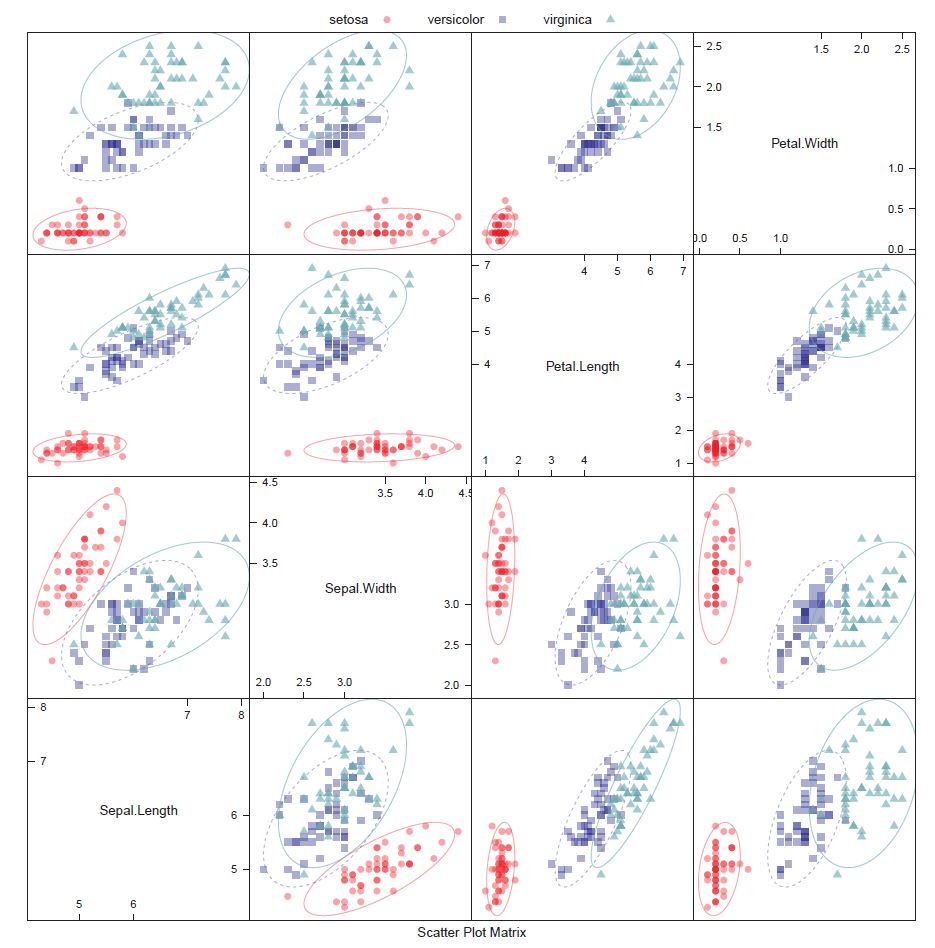
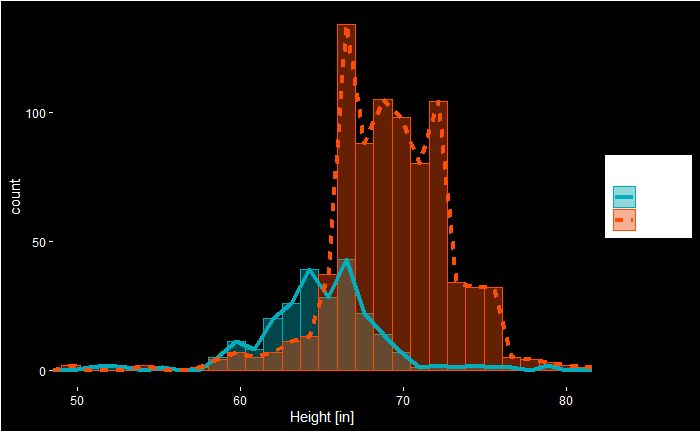
In many statistical inference tests, you may have noticed an inherent assumption that the sample has been taken from a distribution (e.g. normal distribution). Well, those people are performing a parametric test. A non-parametric test doesn’t assume any distribution for its sample (means).
The parametric tests for means include t-tests (1-sample, 2-sample, paired), ANOVA, etc. On the other hand, the sign test is an example of a non-parametric test. A sign test can test a population median against a hypothesised value.
A few advantages of non-parametric tests include:
- Assumptions about the population are not necessary.
- It is more intuitive and does not require much statistical knowledge.
- It can analyse ordinal data, ranked data, and outliers
- It can be used even for small samples.
- Ideal type, if the median is a better measure.
Following are the typical parametric tests and the analogous non-parametric ones.
| Parametric tests | Nonparametric tests | |
| One sample | One sample t | Sign test |
| Wilcoxon’s signed rank | ||
| Two sample | Paired t | Sign test |
| Wilcoxon’s signed rank | ||
| Unpaired t | Mann-Whitney test | |
| Kolmorogov-Smirnov test | ||
| K-sample | ANOVA | Kruskal-Wallis test |
| Jonckheer test | ||
| 2-way ANOVA | Friedman test |
References
Nonparametric Tests vs. Parametric Tests: Statistics By Jim
Non-parametric tests: zedstatistics
Nonparametric statistical tests for the continuous data: Korean J Anesthesiol
Parametric vs Non-Parametric Tests Read More »