Confidence Interval vs Credible Interval
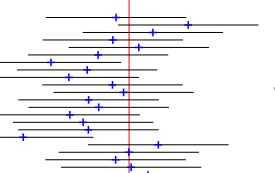
Confidence interval is a frequentist’s way of communicating the range of values within which the actual (population) parameter sits. A confidence interval of 90% implies that if you do 20 random samples from the same target population and with the same sample size, 18 of the confidence intervals cover the true population mean. This is the frequentist’s view, and the parameter is fixed.
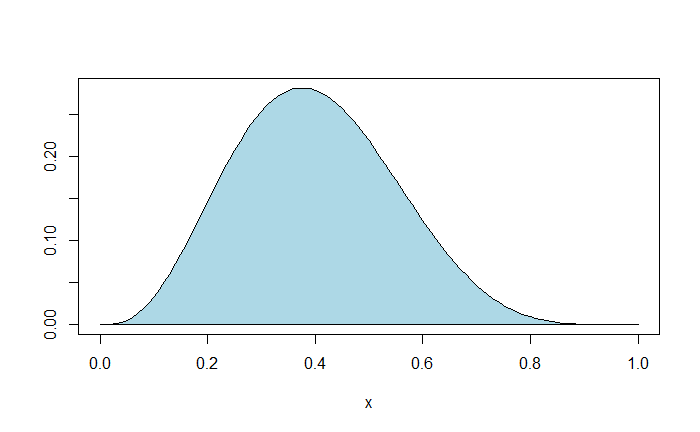
On the other hand, the Bayesian does not have a concept of a fixed parameter and is happy to accept it as an unknown quantity. Instead, she gives a probability distribution to the expected outcome. The range of values (the interval) of the probability distribution (plausibility) is the credibility interval. In a 90% credible interval, the portion of the (posterior) distributions between the two intervals will cover 90% of the area.
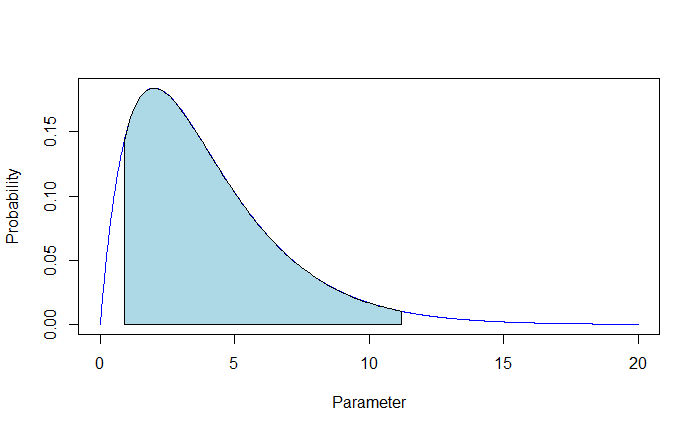
For example, in the following posterior distribution, there is a 90% plausibility that the parameter lies between 0.9 and 11.2; the shaded area = 0.9.
Confidence Interval vs Credible Interval Read More »