Let P(A1) be the probability of getting the first face = 1 P(A2|A1) be the probability of getting a different face from die 1 = (5/6) P(A3|A1A2) be the probability of getting a different face from die 1 and die 2 = (4/6) etc.
We must find the joint probability of A1, A2, A3, A4, A5, and A6.
Frequentist way
For the first roll, there are six choices. Once the first slot is taken, there are five choices for the second roll. Therefore, 6 x 5 for the first and second choices together. If you extend the logic for all the six rolls, you get 6 x 5 x 4 x 3 x 2 x 1 or 6!
Possibilities for the required event = 6! = 720 Total possibilities of rolling six dice = 66 = 46656 P(for the required event) = 720/46656 = 1.5%
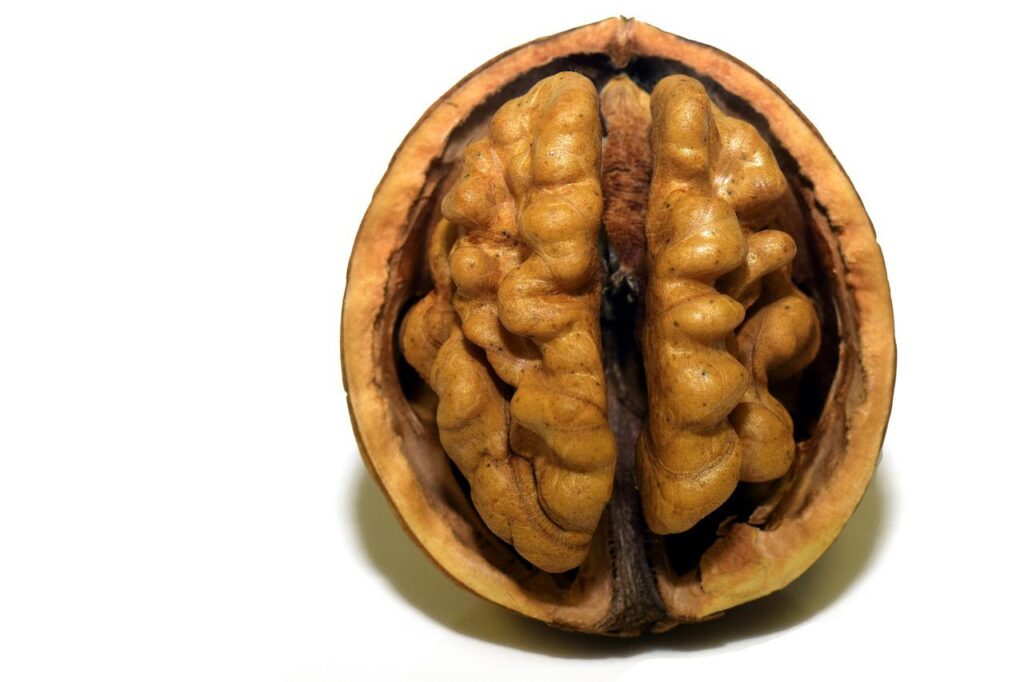
Take a carrot, cut a slice, and look closely. Does it resemble your eyes? See what I meant; it provides the nutrient that is good for the eyes. Have you ever wondered why the tomatoes cut through the middle appear like your heart? Do you know that the polyunsaturated fats of walnut boost your brain? Don’t you know kidney beans are the best thing for your kidney?
The seed for the brain
Start with Mr Walnut. Here is what it looks like:
So naturally, it should be related to the brain. Isn’t it? Well, let me search: yes, it has polyunsaturated fats that are good for the brain! Well, that can also be good for the heart. But that is not the point. And it does not resemble my heart. What about sunflower seeds, flax seeds or flax oil, and fish, such as salmon, mackerel, herring, albacore tuna, trout, corn oil, soybean oil, and safflower oil. They all can give you similar nutrients. But they don’t look like a brain. So, let walnut be the brand ambassador of my brain. Why not? By the way, Cahoon et al. searched the literature but could not find any strong association between walnut and cognitive power. Maybe, they did not search deep enough!
Carrot for your eyes
Cut a carrot and see if it appears like your eyes.
No? If not, cut it until you see some part that resembles your eyes. Come on; you can do it. But what about these: tomatoes, red bell pepper, cantaloupe, mango, beef liver, and fish oils. They, too, contain vitamin A. So what?
Vitamin A is not going to give you night vision. But it should be part of your diet as it helps manage your health, including eye health. Also, carrot doesn’t come packed with vitamin A. But it contains its precursor beta carotene.
Kidney beans
What is the difference between kidney beans and other lentils? Or between blueberries, seabass, egg white, garlic, olive oil, bell peppers, and onions? Well, the key difference is that except for kidney beans, none of the others resembles my kidneys. So, even if they are better food for kidneys than these beans, I am not interested in them.
What about eating jelly beans? Something to research on.
Where do these come from?
Human beings are masters of finding patterns around them and making up stories to support their imagination. The doctrine of signature, too, belongs to that category. It is also a favourite for the creationist folks. Why else is that food created with the shape of your organ? There must be a purpose.
Walnut intake, cognitive outcomes and risk factors: a systematic review and meta-analysis: Pubmed
Cooking Legumes: A Way for Their Inclusion in the Renal Patient Diet: Pubmed
We have seen an explanation of the Monty Hall problem of “Let’s make a deal”, using a 100 door-approach. Let’s imagine a 26-door version. You select one, and the host opens 24 doors that do not have the car. Will you switch your choice to the last door standing? The answer is an overwhelming yes.
Now, switch to another game, namely the deal or no deal. The show contains 26 briefcases containing cash values from 0.01 to 1,000,000 dollars. The player selects one box and keeps it aside. Cases are randomly selected and opened to show the cash inside. Periodically, the dealer offers some money to the player to take and quit the game. If the player refuses all offers and reaches the end, she will have to take whatever is in the originally-chosen case.
Monty’s deal or no deal!
Imagine there are just two boxes left – the one you have selected and the one remaining. The remaining cash values are one and one million. Enter Mr Monty Hall and offers a switch. Will you do it? After all, the original recommendation for the case described in the first paragraph was to switch! But here, there is no need to swap, as you have a 50:50 chance of winning a million from your box. Why is that?
Bayes to the rescue
Before I explain the difference, let’s work out the two probabilities using Bayes’ theorem. First, the original one (Let’s make a deal): Let A be the situation wherein your chosen door has the car behind and B the one where 24 gates did not have it.
Substitute the values, P(A) = (1/26), P(A’) = 25/26 and P(B|A) = 1 (the chance of 24 doors have no car given the car is behind your chosen door. Now think carefully, what is P(B|A’), the probability of having no cars behind those 24 doors, given yours does not have a car? The answer is: it remains one because it was the host who opened the door with full knowledge; it was not a random choice!
So, switching increases your chances to 1 – (1/26) = 25/26.
Second, the new one (Deal or no deal version)
As before, P(A) = (1/26), P(A’) = 25/26 and P(B|A) = 1. Here is the twist, P(B|A’) is not 1 because the situation of 24 cases did not produce a million came at random and was not due to your host. The probability of that happening, given your case doesn’t contain the prize, is 1 in 25. So P(B|A’) = (1/25).
Amazing, isn’t it?
Reference
The Monty Hall Problem: The Remarkable Story of Math’s Most Contentious Brain Teaser: Jason Rosenhouse
It’s time to do one Bayes’ theorem exercise. The problem is known as the Bertrand box paradox and may remind us of the boy or girl paradox.
Imagine there are three boxes. One contains two gold coins, the second two silver, and the third has one gold and one silver. Now you randomly pick a box and take out one coin. If that turned out to be silver, what is the probability that the other coin in that box is also silver?
Intuition suggests that the other coin could either be silver or gold. And therefore, it would be tempting to answer 50%. But that is not true. Let’s apply Bayes’s theorem straightaway. The required probability is mathematically equivalent to the chance of getting two silver (SS), given that one coin is already silver (S) or P(SS|S).
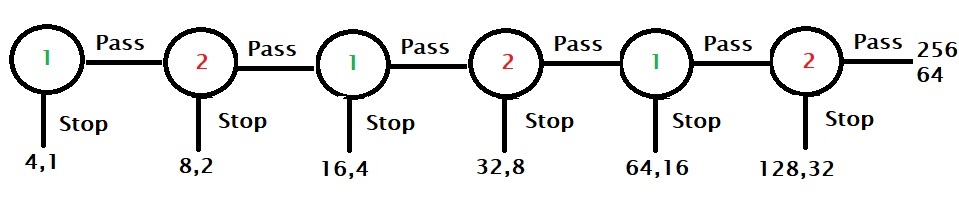
Here is a game played between two players, player 1 and player 2. There are two piles of cash, 4 and 1, on the table. Player 1 starts the game and has a chance to stop the game by taking four or the pass to the next player. In the next round, before player 2 starts, each stack of money is doubled, i.e. they become 8 and 2. Player 2 now has the chance to take a pile and stop or pass it back to player 1. The game continues for a maximum of six rounds.
Best strategy
To find the best strategy, we need to start from the end and move backwards. As you can see, the last chance is with player 2, and she has the option to end the game by taking 128 or else the other player will get 256, leaving 64 for her to take.
Since player 1 knows that player 2 will stop the game in the sixth round, he would like to end in round five, taking 64 and avoiding the 32 if the game moved to another.
Player 2, who understands that there is an incentive to be the player who stops the game, can decide to stop earlier at fourth, and so on. So by applying backward induction, the rational player comes to the Nash equilibrium and controls the game in the first round, pocketing 4!
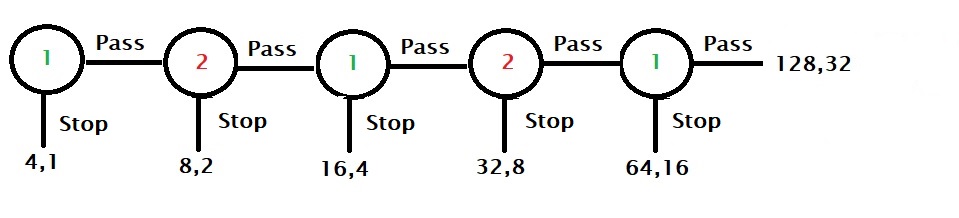
Irrationals earn more
On the other hand, player 1 passes the first round, signalling cooperation to the other player. Player 2 may interpret the call and let the game to the second round, trusting to bag the ultimate prize of 265. Here onwards, even if one of them decides to end the game, which is a bit of a letdown to the other, both players are better off than the original Nash equilibrium of 4.
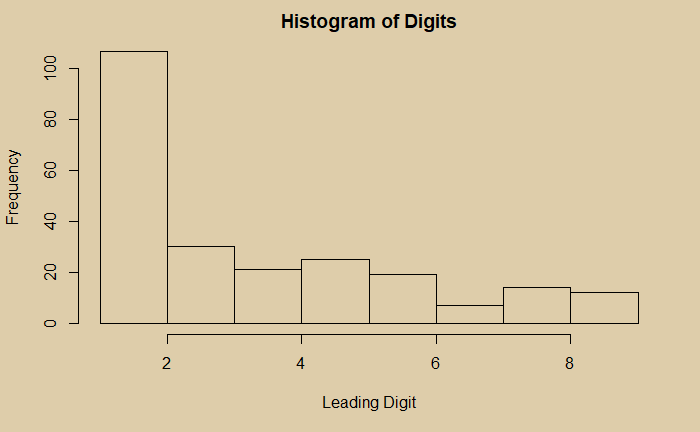
Benford’s law forms from the observation that in real-life datasets, the leading digits or set of digits follow a distribution in a successively decreasing manner, with number 1 having the highest frequency. As an example, take the population of all countries. The data is collected from a Kaggle location, and leading integers are pulled out as follows:
We have discussed the Monty Hall problem already a couple of times. One reason why people make this mistake is that they forget the role of the host in reducing the uncertainty of the car’s location. In other words, when the host eliminates one wrong door, he doubles the chances for the participant.
100 doors
Imagine a modified game in which there are 100 doors. You pick one. There can not be two opinions here that the chances of guessing the right door (having a car behind it) is one in one hundred. The host then opens all but one opening and shows you 98 goats. Will you switch this time? Or do you still think your original choice has a 50% probability of finding the car?
We have built the definitions of data scatter (noise) and bias based on a group of data points in the previous post. This time, we estimate the mean squared errors of the data.
Noise
Here is a collection of data:
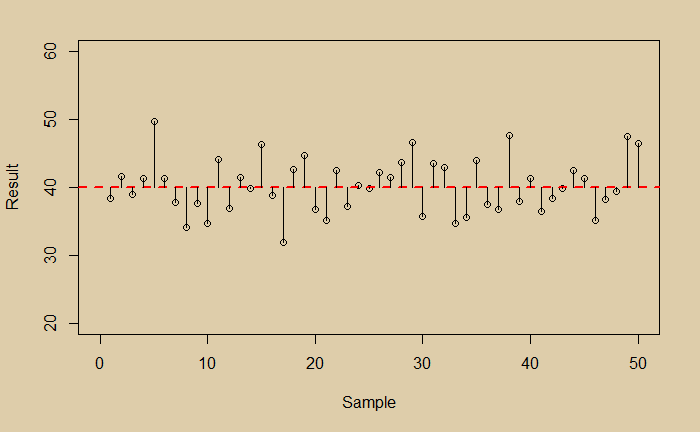
If you are not aware of the bias in the data, you would have calculated the error in the following way. Estimate the mean, calculate deviations for each of the points from the mean, square them and calculate the mean of the squares.
Note that this is also called the variance. For our data, the mean is 40, and the mean square ‘error’ is 15.75.
Somehow, you learned that the data was biased, and the true value was 45 instead of 40. Now you can estimate the mean square error as given below.
The value of this quantity is 39, which is the combined effect of the error due to noise and bias.
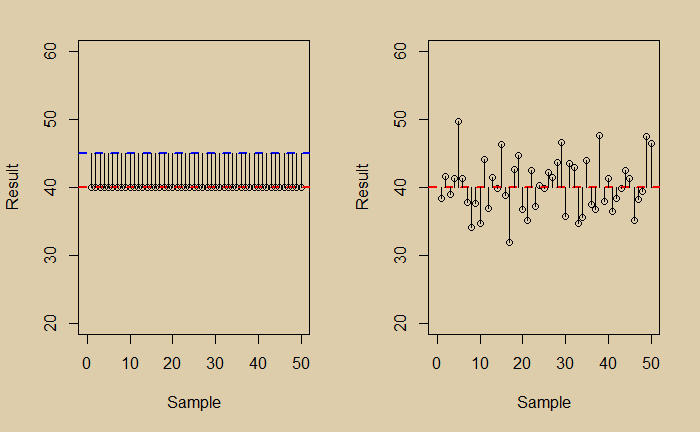
One way of understanding the total error is to combine the error at zero scatter and the error at zero bias. They are represented in the two plots below.
The mean squared error (MSE) in the zero-scatter (left) is 25 (square of the bias), and the zero bias is 15.75. And the sum is 40.75; not far from the total (39) estimated before.
Why MSE and not ME?
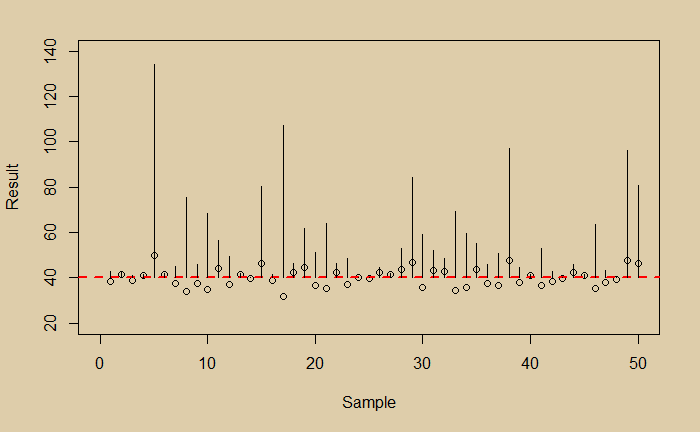
While you may question why the differences are squared, before averaging, it is apparent that in the absence of squaring, the scattered data around the mean, the plusses and minuses, can cancel each other and give a false image of an impressive data collection. On the other hand, the critics will naturally express their displeasure at seeing an exaggerated plot like the one below!
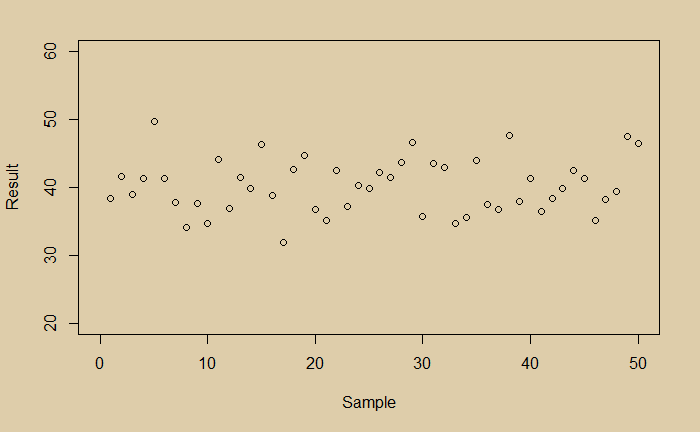
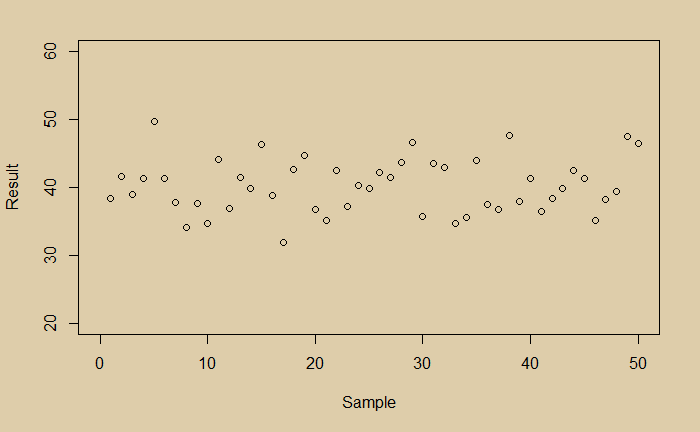
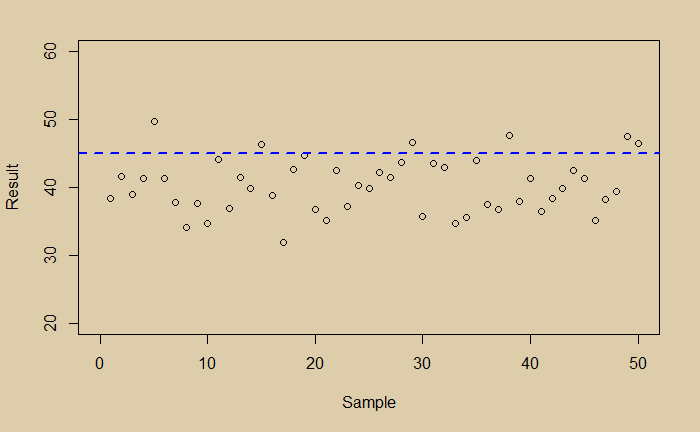
Imagine you did a measurement and collected the following 50 data points.
What would you conclude? You see a little noisy data. You do a regression and get the following average line.
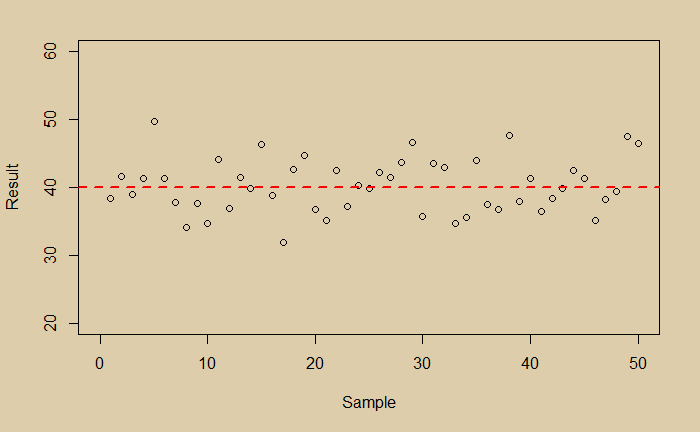
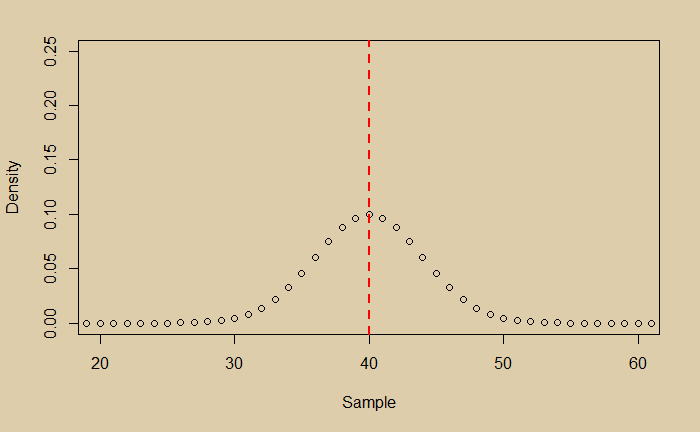
Now you are happy that you managed the random scatter of the data; you got the expected value of the experiment. And it is 40. You then plot the distribution of your data and find it is perfectly normal.
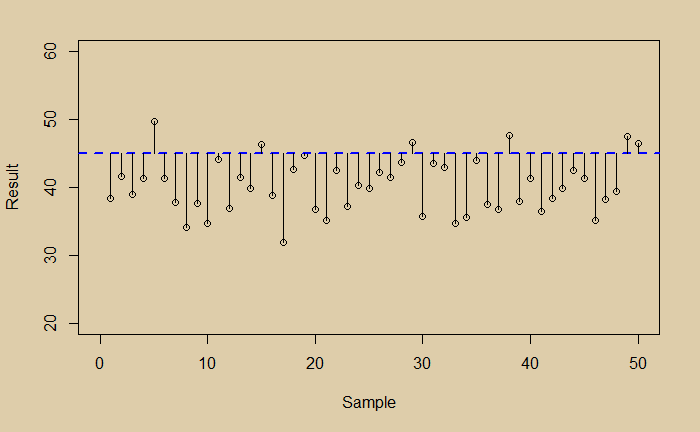
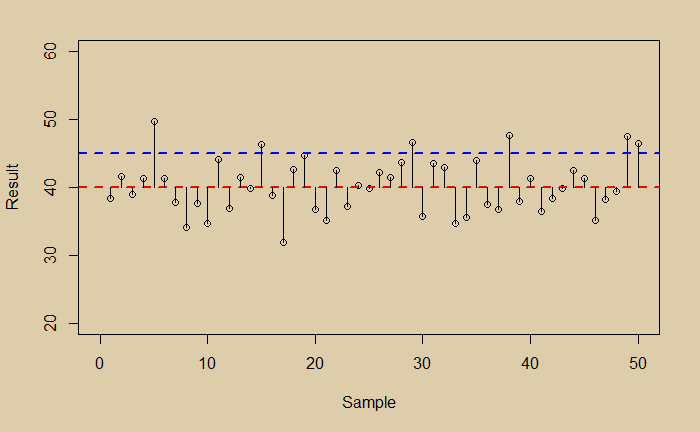
Imagine your true value is 45, and your experiment had a bias.
Suddenly you have two problems, scatter (noise) and bias. Which one is a bigger problem to address?
We know what the mean for the distribution of random variables is; it is called the expected value. You can calculate it by multiplying outcomes by their respective probabilities and sum over all those outcomes.
If the variables are discrete and all the probabilities are equal (equal weightage), add them up and divide by the number of variables.
Variance
The spread of values around the mean is variance. It is calculated by calculating the mean of (expected value of) square of sample values after subtracting the mean.
Like in the earlier case, for an equally likely case (all p(Xi) are equal), variance can be calculated by adding all the squares and dividing by the total number.
Bias
So far, we have assumed unbiased samples (e.g. fair coin, fair dice etc.) in our discussions. In such cases, the true values equalled the expected values. It is not the case in real life, where biases do occur. Bias is the difference between the average value and true value. In other words, you get the true value after subtracting bias from the average of the estimators.
Variances and biases are two causes of error in data. How they are related or not related is the topic of another discussion.











![E[X] = \sum\limits_{i=1}^n (p(X_i)*X_i) = \mu](https://thoughtfulexaminations.com/wp-content/ql-cache/quicklatex.com-2191667149e73a5a70bcd5be91f5082a_l3.png "Rendered by QuickLaTeX.com")

![E[(X - \mu)^2] = \sum\limits_{i=1}^n [p(X_i)*(X_i - \mu)^2]](https://thoughtfulexaminations.com/wp-content/ql-cache/quicklatex.com-ce1c77bd3a11180592641fdedeeec698_l3.png "Rendered by QuickLaTeX.com")
![Var(X) = E[(X - \mu)^2] = \frac{1}{n}\sum\limits_{i=1}^n [(X_i - \mu)^2]](https://thoughtfulexaminations.com/wp-content/ql-cache/quicklatex.com-7c752dd9fe0a11137d1a9d40a4ae3fbf_l3.png "Rendered by QuickLaTeX.com")
![Bias(\hat\theta) = E[\hat\theta] - \theta](https://thoughtfulexaminations.com/wp-content/ql-cache/quicklatex.com-35ead78c1378aea3e5f654e7e916a817_l3.png "Rendered by QuickLaTeX.com")