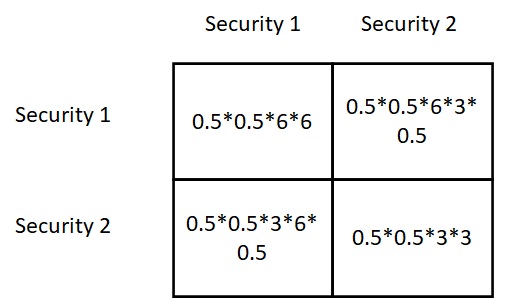
Geometric Distribution
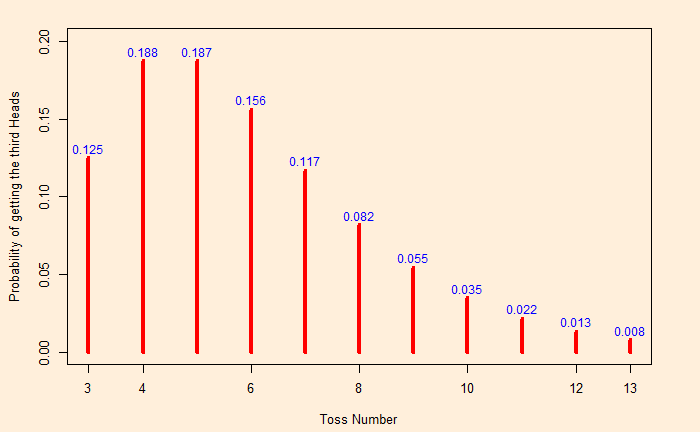
One in five cars in the city is green. What is the probability that the fifth car is the first green car?
We already know we can solve this problem using the negative binomial distribution function. But there is a special one for these types – where the arrival time of the first in question. That is the geometric distribution. The formal expression of the probability that the first occurrence of success requires k independent trials, each with success probability p is

To answer the question in the beginning, we substitute p = 0.20 (one in fifth), car number = 5; the required probability is (0.2)*(1-0.2)4 = 0.08192
The R code for the same calculation is
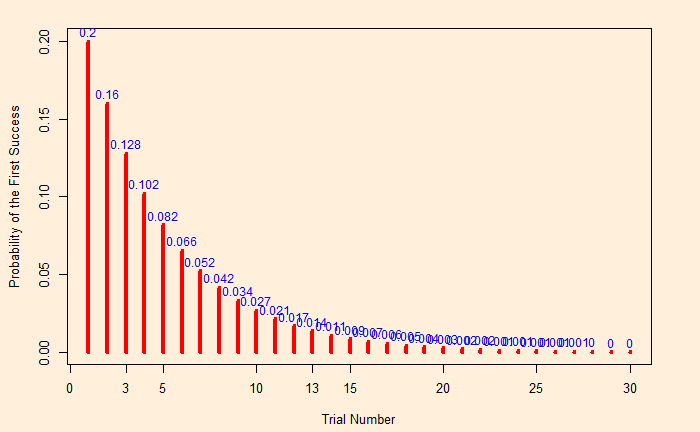
dgeom(4, prob = 0.2, log = FALSE)The below geometric distribution chart shows the probability of seeing the first green car in precisely 1, 2, 3, etc. rolls, up to 30.
Geometric Distribution Read More »