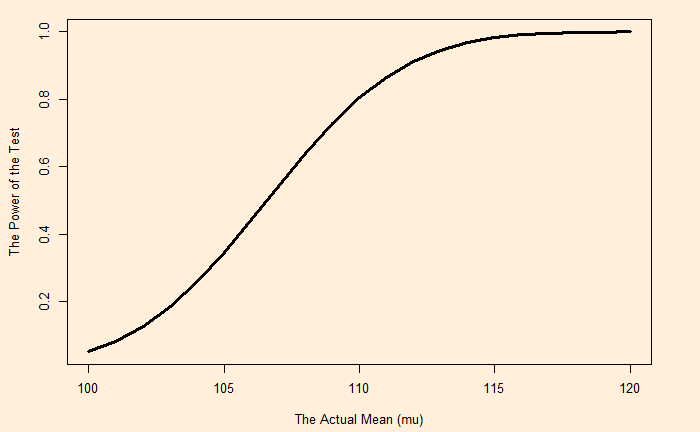
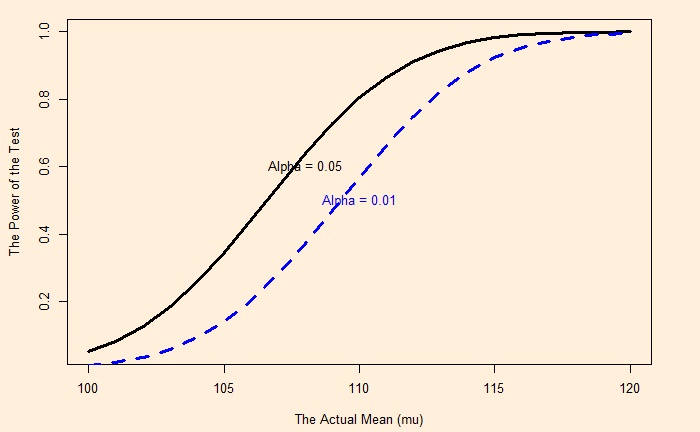
Amy’s Job
Amy got short-listed for three job interviews. The total number of candidates appearing for the three jobs are 5, 3 and 4. Assuming all the candidates are equally competent, what is Amy’s chance of getting at least one job?
Step 1: Assume probabilities are independent.
Step 2: Estimate the probabilities of getting rejected in each job. i.e., 1 – 1/5 = 4/5, 1 – 1/3 = 2/3, and 1 – 1/4 = 3/4.
Step 3: Calculate the joint probability of getting left in all jobs. (4/5)x(2/3)x(3/4) = 0.4
Step 4: Probability of getting at least one job = 1 – probability of getting rejected from all jobs, i.e., 1- 0.4 = 0.6