School, Grades and the Collider
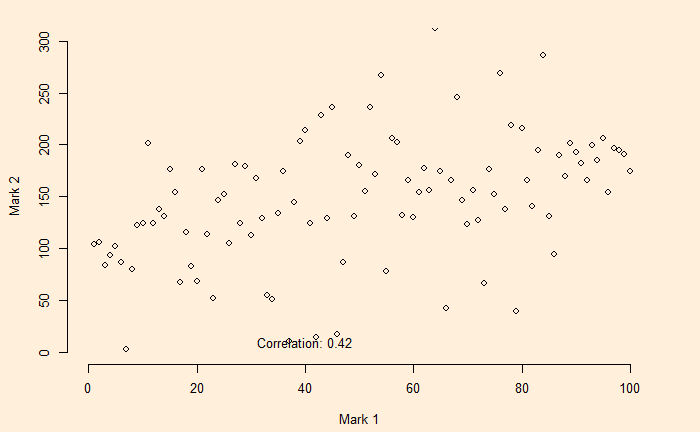
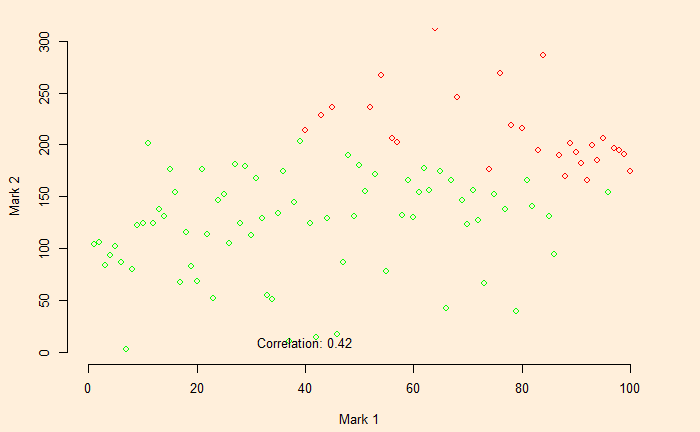
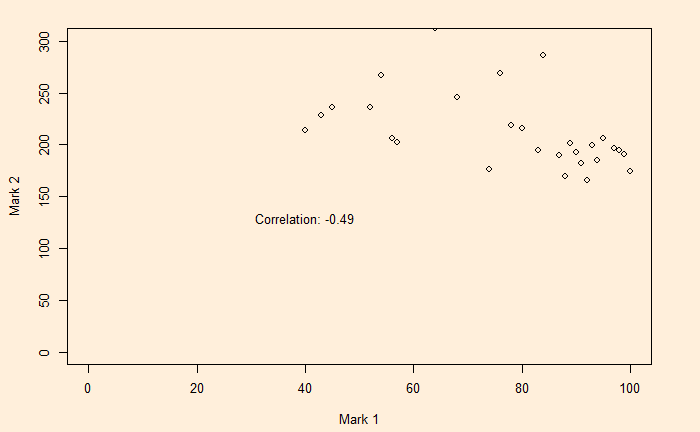
Another example of Berkson’s paradox, a collider bias, is the observed relationship, in surveys, between attending classes and grades. Here we illustrate the various possibilities and the results. Here, we explain the math using the following example.
| Attend | Attend | Do Not Attend | Do Not Attend |
| Good Grade | Poor Grade | Good Grade | Poor Grade |
| 300 | 200 | 200 | 300 |
And this leads to the following conclusions:
- Probability of getting good grades, given the person attends classes, P(G|A) = # good grades and attend / total attend = 300/(300 + 200)= 0.6
- Probability of getting poor grades, given the person attends, P(P|A) = 1 -P(G|A) = 0.4
- Probability of getting good grades, given the person doesn’t attend, P(G|N) = 200/(200 + 300) = 0.4
- Probability of getting good grades, given the person doesn’t attend, P(P|N) = 1 – P(G|N) = 0.6
Attending classes helps! But this information is never known outside. And it is where the survey gets interesting.
Imagine the survey captured the following proportions for each category.
| Attend | Attend | Do Not Attend | Do Not Attend |
| Good Grade | Poor Grade | Good Grade | Poor Grade |
| 0.9 | 0.5 | 0.5 | 0.1 |
Leading to the following Survey table.
| Attend | Attend | Do Not Attend | Do Not Attend |
| Good Grade | Poor Grade | Good Grade | Poor Grade |
| 270 | 100 | 100 | 30 |
Now, calculate the probability tables, and compare with the actual.
| Survey | Actual | |
| P(G|A) | 0.73 (270/370) | 0.6 |
| P(P|A) | 0.27 | 0.4 |
| P(G|N) | 0.77 (100/130) | 0.4 |
| P(P|N) | 0.23 | 0.6 |
The survey tends to conclude the advantages of not attending classes!
School, Grades and the Collider Read More »