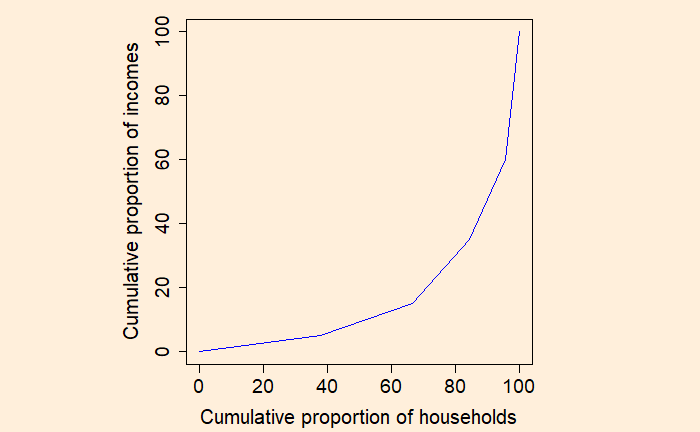
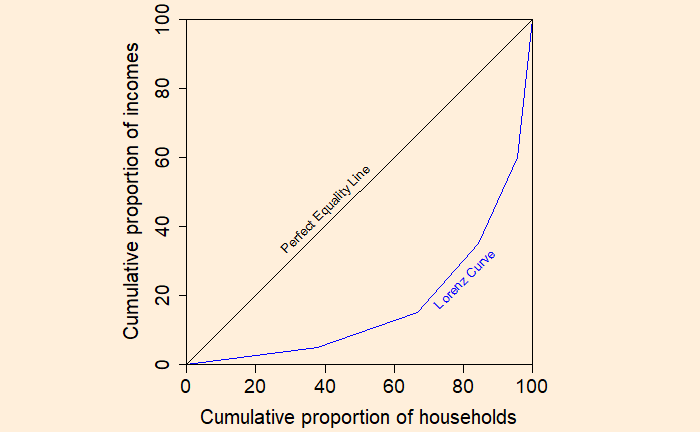
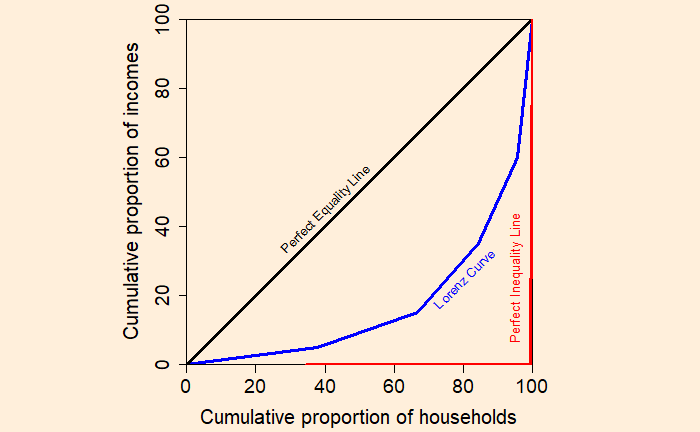
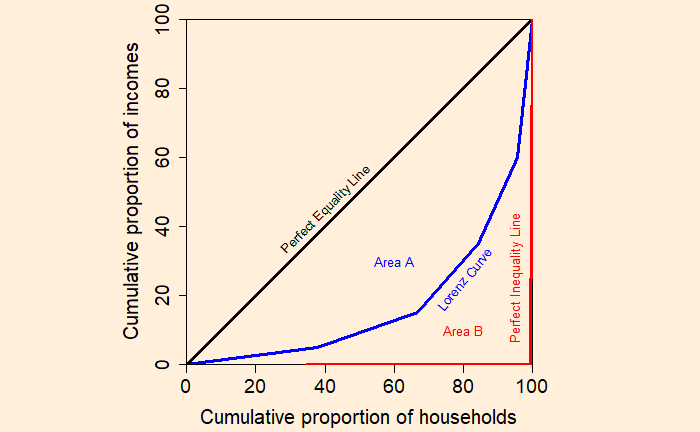
Came across one of the finest videos on YouTube about our past, present and future life, Yuval Noah Harari’s talk to youngsters and teachers, which triggered the idea of this post.
Turning the knob
Knowledge is like turning the knob. When it turns, you see things in a new light; until then, no matter how hard you try, you don’t get it out of ‘common knowledge’. Unfortunately, the common knowledge is almost always wrong!
The hyperpigmented on the equator
Take the favourite example of pigmentation of humans living in the equatorial region. For a moment, let’s ignore the people who believe that people of colour are of a separate species. We are dealing with more reasonable people here. If the narrative is that people in sunny regions have become dark-skinned because of heat and light, it’s an easier narrative to sell. It fits with the common knowledge – we all know what happens when we fry things; a little too much and it turns black.
Unfortunately, that’s not how things evolve. The theory of evolution switch needs to turn on. What about this: a group of people (perhaps dominated by the light-skinned) reach a sunny region. A few of them got skin cancer due to their lack of protective pigmentation and died maybe a few years earlier than their accidentally darker companions. That raised (by a small margin) the probability of darker parents, their children and their children having the advantage, and wow, after 10,000 years, there was a complete dominance of the dark. So, will that happen in Australia after 10,000 years? We’ll answer that in the end.
Humans of Flores
There used to be a pack of humans living in Flores, an island in Indonesia (until they were extinct about 50,000 years ago). They were humans as they shared the homo family. They were different humans because we are homo sapiens, and they were not. They were pretty short – about 1 m. tall – people. Not just them but the animals of that island as well. A simple convincing argument is that the animals got trapped on the island, became resource-constrained, and to survive, they had to consume less food. And they became smaller. It’s convincing because 1) it gives a feeling that one bunch of people after starvation has shrunk, or 2) they passed a genetic code to the children and made them shrink.
Turn the switch, and you get it: big humans reached the island. Once they got disconnected from the mainland due to sea level rise, the larger ones faced a more significant disadvantage due to food shortage, and the smaller ones survived better. In the next generation, there were disproportionally smaller kids from the surviving parents (the new group has larger ones too). Turn a few pages, centuries and generations: the island is full of smaller humans. This narrative is difficult to fathom without the switch as it is against the common knowledge. First, how can more miniature humans be fitter? That doesn’t conform very well with the stereotypes! Second, something forcing people (in one lifetime) to become smaller is easier to imagine than this chance game of smaller ones surviving (in a hundred lifetimes).
The future evolutions
That naturally begs the question. Will the Australians (the white Australians) turn back after 10,000 years? Even the broader question: What will be the next evolution of humans? The answer to the first question is a no, and the answer to the second question is impossible to predict.
The code lies in the knowledge paradox we are in. Australian whites won’t turn black because they know why it happens and what to do against death from skin cancer. It could be as simple as using sunscreen (or deciding not to venture out in the UV-intense part of the day). And this will translate to other things as well. If we know something gives us a disadvantage, we will engineer means to counter it. It has to be a disadvantage that gave the survivors the chance to survive, and we are closing those weaknesses!
Must watch video
Yuval Noah Harari Speaks to Young Readers & Teachers: Yuval Noah Harari