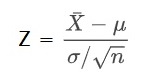The horses A, B and C have the following amounts on bets:
Horse 1
$10000
Horse 2
$15000
Horse 3
$25000
How much should the track pay a bettor for winning on a $2 bet? Note the track will take 10% as their profit.
The first thing is to determine the odds. A Bayesian is not so worried about coming up with one. The simplest method is to go for the gut feeling. Another way is to estimate the win probability based on the bet amount (individual/total) and then determine the odds as, (1 – probability) / probability
Horse
Bet Amount
Probability
Odds
Horse 1
$10000
10000 / 50000 = 0.2
4 to 1
Horse 2
$15000
15000 / 50000 = 0.3
2.3 to 1
Horse 3
$25000
25000 / 50000 = 0.5
1 to 1
For a $2 bet on horse 1, the payout will be 2 x 4 – 0.1 x 2 x 4 = $7.2
Introduction to Mathematical Statistics: PennState
The studies on the correlation between income and happiness have a bit of history. In 2010, a study led by Daniel Kahneman found that the happiness of individuals increases with (log) income until about $75,000 per year and then flattens out. However, the work of Killingsworth (2021) showed contradictory results where happiness just followed a linear trend with the log (income).
Join forces!
The original study of Kahneman and Deaton had survey responses from about 450,000 US residents that captured answers on their well-being.
Killingsworth’s work, on the other hand, had 1,725,994 reports of well-being from 33,391 employed adults (ages 18 to 65) living in the US. It found happiness advancing linearly even beyond $200,000 per year.
The conflict prompted an ‘adversarial collaboration‘ with Barbara Mellers as the facilitator.
The hypothesis
They started with a hypothesis for the test: 1) There is an unhappy minority whose unhappiness reduces with income up to a threshold, then shows no further progress. 2) A happier majority whose happiness continues to rise with income.
The ‘joint team’ stratified Killingsworth’s data into percentiles and here is what they found:
Percentile of happiness
Slope up to $100k
Slope above $100k
5% (least happy)
2.34
0.25
10%
1.75
0.52
15%
1.90
0.34
20%
1.84
0.62
25%
1.52
1.12
30%
1.33
1.21
35%
1.26
1.21
References
Matthew Killingsworth; Daniel Kahneman; Barbara Mellers, “Income and emotional well-being: A conflict resolved”, PNAS, 2023, 120(10).
Daniel Kahneman; Angus Deaton, “High income improves evaluation of life but not emotional well-being”, PNAS, 2010, 107(38).
Matthew Killingsworth, “Experienced well-being rises with income, even above $75,000 per year”, PNAS, 2021, 118(4).
The fallacy of hindsight – the feeling that the fact was evident after the outcome is known – is a significant factor that undermines the truth of probability and risk in decision-making. The occurrences of hindsight bias, or the ‘I knew it’ moments, are prominent when the results are adverse. As per scientists Neal Roese and Kathleen Vohs, there are three bias levels. They are:
Memory distortion (not remembering the earlier opinion)
Inevitability (the event was inevitable)
Foreseeability (the conviction that the person knew it beforehand)
When hindsight bias is all about dismissing the past decision-making process after a negative result, the ‘fear of missing out’ (FOMO) is the intrinsic motivation to act due to (the memories) positive outcomes of the past. Although the term FOMO was initially introduced (in 2004) to describe people’s compulsive behaviour on social networking sites, it is pervasive in several walks of life, including decision-making, investing, and trading, to name a few.
Issues of hindsight bias
The biggest concern is that it discounts the role of probabilities and trade-offs in decision-making, leading to labelling the initial decision-makers as a joke. If you recall the expected value theory, it is almost like forgetting about the probability of failure of the equation. It is more dangerous than just finger-pointing. Hindsight bias causes overconfidence in individuals and decreases rational thinking while navigating complex problems. ‘Always feeling wise’ also reduces one’s ability to learn from mistakes.
And the FOMO
FOMO is just the opposite of what a value investor may want to do. Typically, FOMO leads to chasing stocks during a bull run of the market, or perhaps the very reason for the bull market! While a few lucky ones may be able to cash during the market run, most people with ‘buying high’ end up losing on the crash. FOMO can create collective anxiety in organisations about missing investment opportunities, especially with speculations about the possibilities of ‘things’ happening elsewhere.
After a break, we are back with a Bayesian problem. It is taken from the Penn State site and combines the Bayes rule with Poisson probabilities.
Amy thinks the average number of cars passing an intersection is 3 in a given period, whereas Becky thinks it’s 5. On a random day of data collection, they observed seven cars. What are the probabilities for each of their hypotheses?
Let’s give equal prior probabilities for both (P(lambda = 3) P(lambda = 5) = 0.5). P(X = 7 | lambda = 3) is given by the Poisson probability density function:
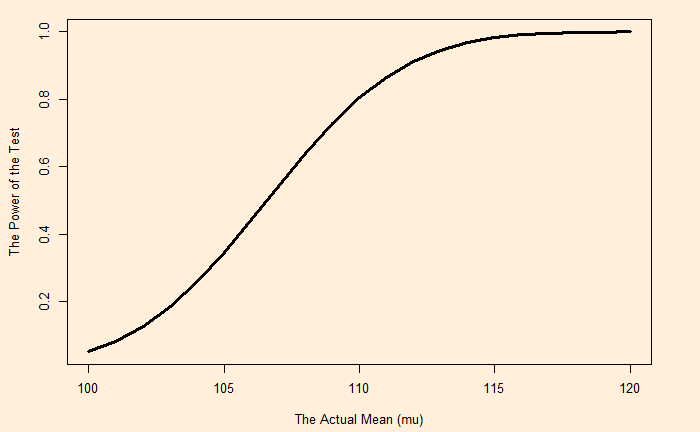
In the last post, we have seen the power of the hypothesis test for a mean, which is away from the null hypothesis. What happens if the true mean is further away, say 110 instead of 108? Let’s run the following code and you get it.
You see, the power is increased from 0.64 to 0.8. The whole spectrum of power values from the null hypothesis mean (100) all the way to 120 is shown below.
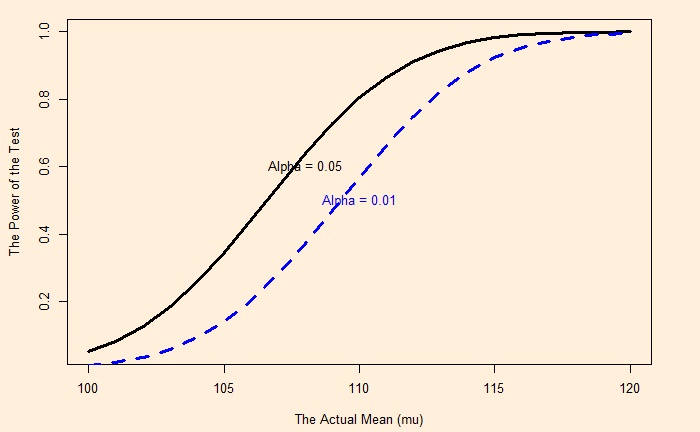
When alpha is reduced, the power is also reduced (type II error increases).
Let’s assume the IQ of a population is normally distributed with a standard deviation of 16. A hypothesis test collected 16 samples for the null hypothesis of mean IQ = 100 for a significance level of 5%. What is the power of the hypothesis test if the true population mean is 108?
Definition: The power of a test is the probability that it will correctly reject the null hypothesis when the null hypothesis is false.
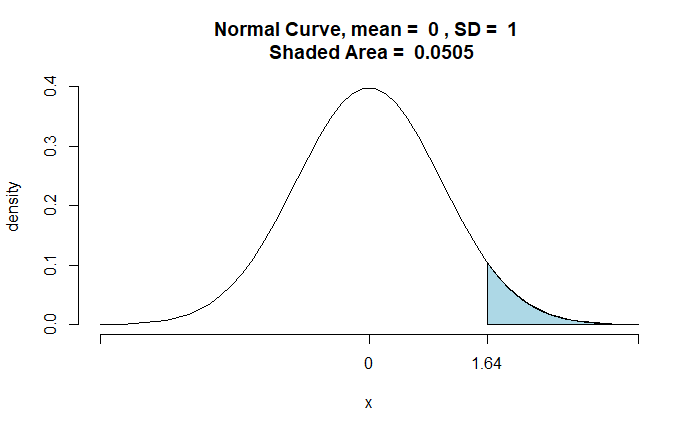
Step 1: Estimate the Z-score for the alpha (significance level)
qnorm(0.05, 0, 1, lower.tail = FALSE)
1.645
Step 2: Estimate IQ corresponds to Z = 1.645
1.645 * 16 / sqrt(16) + 100 = 106.58
Above the IQ average of 106.58, the Null hypothesis (that the mean = 100) will be rejected.
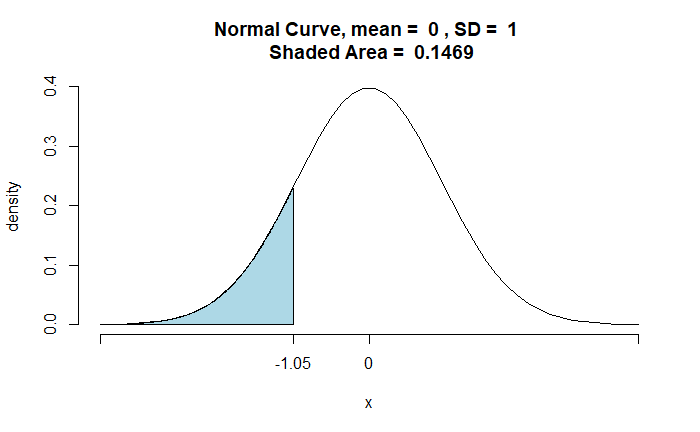
Step 3: Estimate Z-score at X = 106.58 for mean = 108
The entire area above Z = -0.355 is included in the power region (the area below Z = -0.355 will be the false negative part as the null hypothesis will not be rejected).
Step 4: Estimate the cumulative probability > Z = -0.355
Alan knows the average fuel bill of families in his town last year was $260, which followed a normal distribution with a standard deviation of $50. He estimated this year’s value to be $278.3 by sampling 20 people. He then rejected last year’s average (the null hypothesis) in favour of an alternate of average > $260.
1. What is the probability that he wrongly rejected the Null hypothesis?
The probability is estimated by transforming the normal distribution with mean = 260 and standard deviation = 50 to a standard normal distribution (Z):
The ‘pnormGC’ function of the ‘tigerstats’ package makes it easy to depict the distribution and the region of importance.
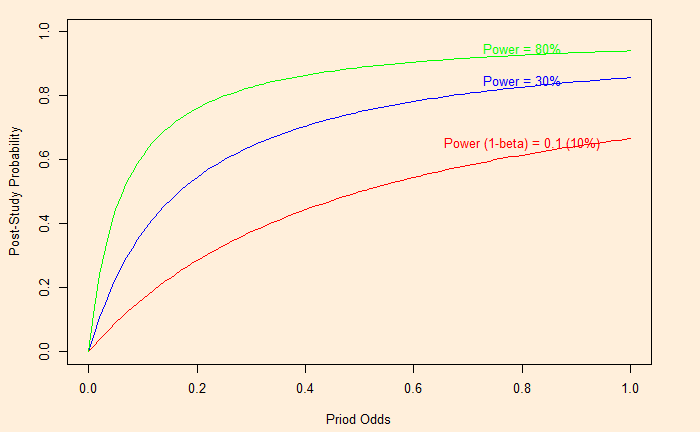
The relationship between the Positive Predictive Value (PPV) and the Power of the study ( 1 – beta) is related via the significance value (alpha) and the prior odds:
If I were to define science in one phrase, it would be ‘hypothesis testing’. In the report published in 2019, the committee appointed by the Science Foundation (NSF) defined two fundamental terms connected to scientific research (and hypothesis testing): reproducibility and replicability.
Reproducibility
Reproducibility is about computation. It is about consistent calculation output from the same input data, computational steps, methods, codes, etc.
Replicability
Replicability involves new data collection using methods similar to those employed by previous studies.
References
National Academies of Sciences, Engineering, and Medicine 2019. “Reproducibility and Replicability in Science“. Washington, DC: The National Academies Press. https://doi.org/10.17226/25303.
In the previous post, we saw the problem of indiscriminately using the threshold p-value of 0.05 to test significance. Benjamin and Berger, in their 2019 publication in The American Statistician, urge the scientific community to be more transparent and make three recommendations to manage such situations.
Recommendation 1: Reduce alpha from 5% to 0.5%
It is probably a pragmatic solution for people using p-value-based null hypothesis testing. We know 0.005 corresponds to a Bayes Factor of ca. 25, which can produce good posterior odds for prior odds as low as 1:10. But what happens if the prior odds are lower than 1:10 (say, 1:100 or 1:1000)?
Recommendation 2: Report Bayes Factor
Bayes factor gives a different perspective on the validity of the alternative hypothesis (finding) against the null hypothesis (default). Once it is reported, the readers will have a feel of the strength of the discovery.
Bayes Factor (BF10)
Interpretation
> 100
Decisive evidence for H1
10 – 100
Strong evidence for H1
3.2 – 10
Substantial evidence for H1
1 – 3.2
No real evidence for H1
Recommendation 3: Report Prior and Posterior Odds
The best service to the community is when researchers estimate (and report) the prior odds for the discovery and how the evidence has transformed them to the posterior.
Reference
[1] Benjamin, D. J.; Berger, J. O., “Three Recommendations for Improving the Use of p-Values”, The American Statistician, 73:sup1, 186-191, DOI: 10.1080/00031305.2018.1543135
[2] Kass, R. E.; Raftery, A. E., Bayes Factors, Journal of the American Statistical Association, 1995, 90(43), 773