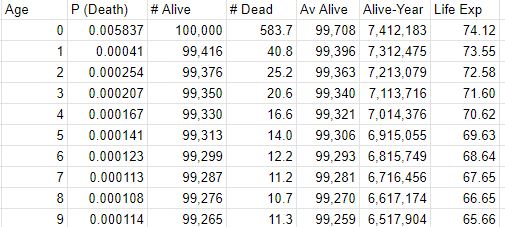
Dieing to Fill Glasses
Here is a game: There are six empty glasses – numbered 1 through six. You roll a die and fill an empty glass that matches the die roll. If the number on the die matches with an already-filled glass, it will be emptied. How many rolls are required to fill all six glasses?
Suppose there are five filled glasses, the number of die rolls required before the game ends is denoted by E(5). Based on this definition, E(0) must be the number of die rolls to finish the game starting with 0 filled glasses, equivalent to the original question.
E(5) = (1/6)[1] + (5/6)[1 + E(4) ]
E(4) must be in the following form to extend the logic.
E(4) = (2/6)[1 + E(5)] + (4/6)[1 + E(3) ]
E(3) = (3/6)[1 + E(4)] + (3/6)[1 + E(2) ]
E(2) = (4/6)[1 + E(3)] + (2/6)[1 + E(1) ]
E(1) = (5/6)[1 + E(2)] + (1/6)[1 + E(0) ]
E(0) = (6/6)[1 + E(1)]
Solving the five equations with five unknowns,
E(0) = 83.2
Reference
Can You Solve The Dice Rolling Drinking Game?: MindYourDecisions
Dieing to Fill Glasses Read More »