Trading and Pareto Efficiency – Continued
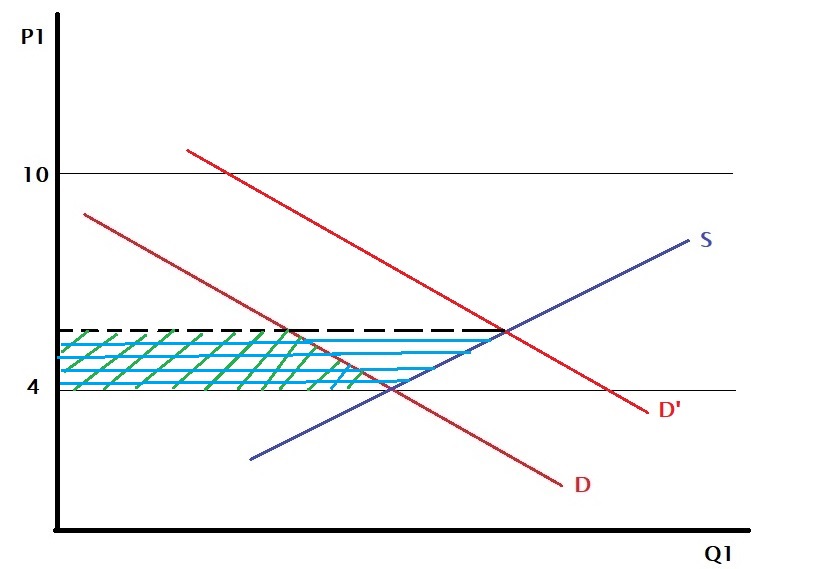
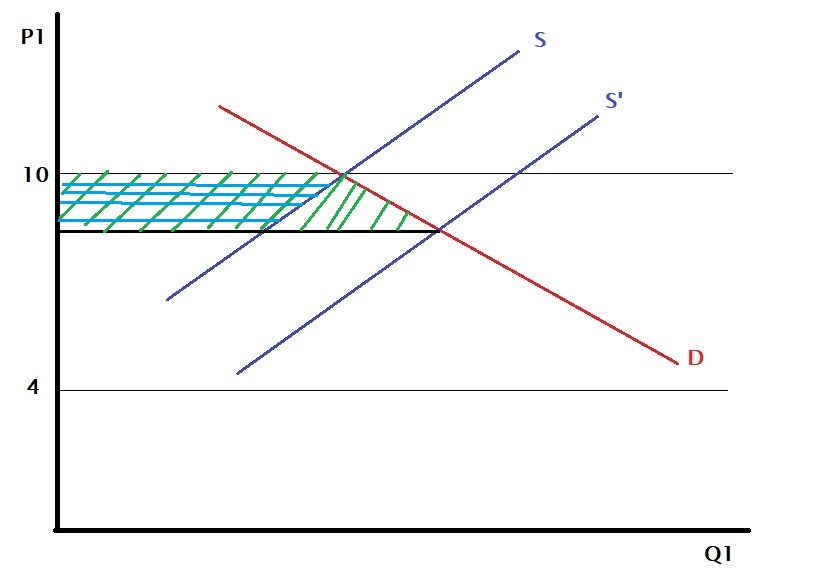
Last time we concluded that international trade was Pareto inefficient even though it made both countries richer (i.e. GDP) because it creates winners and losers within the country. But the effect can be reversed if the government shares the gains with the loser.
But this is easier said than done. Experience has shown that governments are typically slow to compensate than permitting trade.
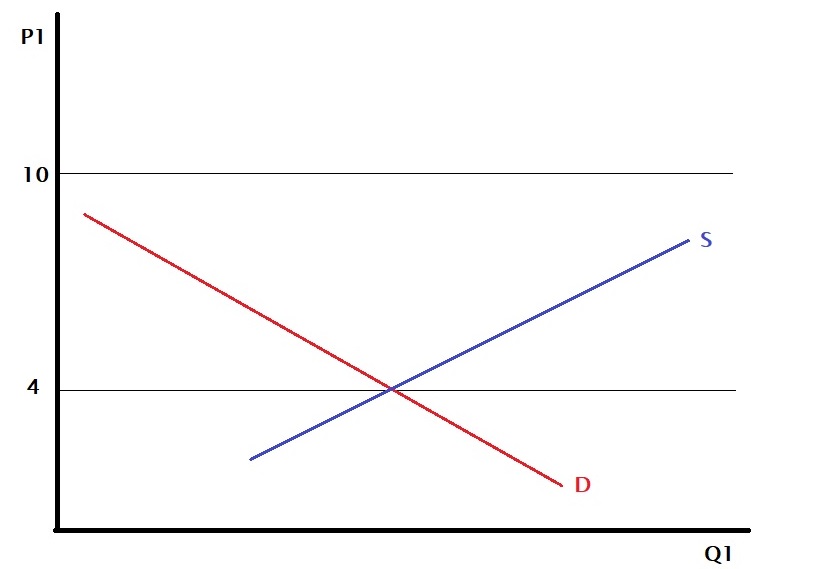
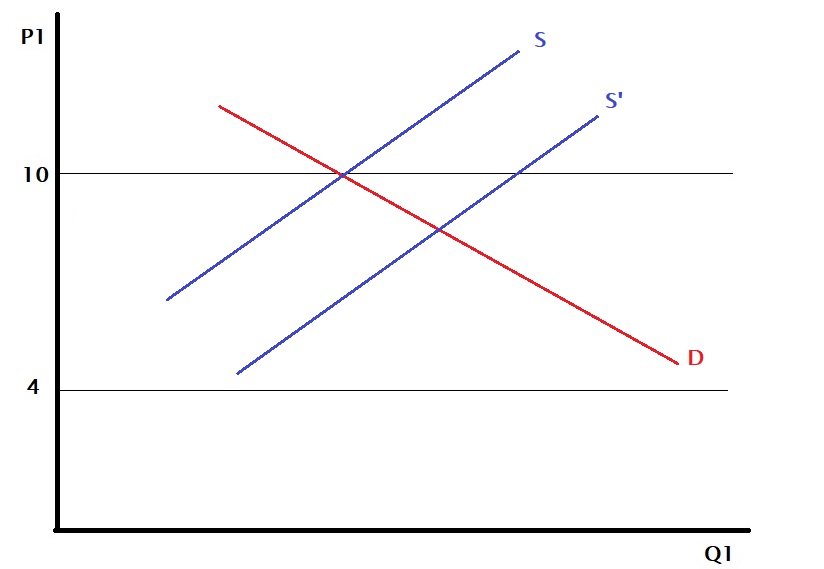
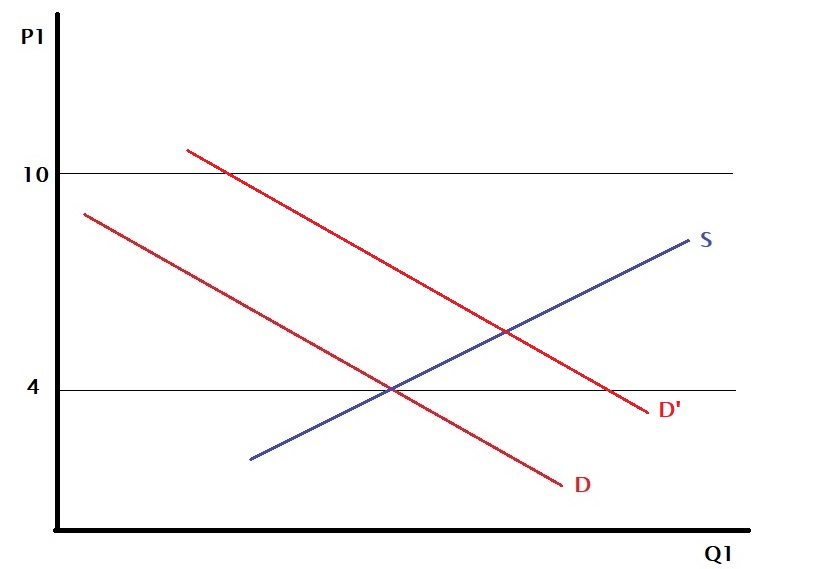
But where is this benefit coming from? It happens because the price differential exists between two countries. One reason could be that technology makes the production of the same goods in one country cheaper than the other. The second may be the preference for different countries – country A values item 1 over item 2, whereas country B likes the opposite.
The advantage doesn’t need to be absolute; it only needs to be relative. Consider this example: there is a job that pays $100, which involves two activities. Amy can do activity 1 in 20 hrs and activity 2 in 10 hrs. Betty can perform activity 1 in 100 hrs and activity 2 in 300 hrs. Amy has an advantage in both jobs. What maximises the reward for Amy – do the job herself or partner with Betty?
Let’s analyse the following four situations:
| Case | Job 1 Hrs A | Job 2 Hrs A | Job 1 Hrs B | Job 1 Hrs B | Gain A ($/hr) | Gain B ($/hr) |
| A job 1 A job 2 | 20 | 10 | – | – | 100/30 = 3.33 | 0 |
| B job 1 B job 2 | – | – | 100 | 300 | 0 | 100/400 = 0.25 |
| A job 1 B job 2 | 20 | – | – | 300 | 50/20 = 2.5 | 50/300 = 0.16 |
| B job 1 A job 2 | – | 10 | 100 | – | 50/10 = 5 | 50/100 = 0.5 |
Interestingly, partnering made both parties better off. This is trade 101.
Inspired by the lecture notes of David Autor, MIT department of economics.
Trading and Pareto Efficiency – Continued Read More »