Guys Finish Last
Do you remember the last time you were in a queue that reached the counter ahead of others who joined at similar times as you did? It could be a bit of a struggle to recollect, but I’m sure you remember the time you finished the last! Let’s analyse what must be happening with you.
Clue 1: Selective memory
The simplest explanation for your troubles is selective memory. Don’t you remember that day you wanted to write down a number in a phone call and found the pen was not working? You know it was not the first telephone you attended in life where you had to write something down. And you had a pen that worked, but you took it for granted – after all, the purpose of that device is to write.
You are more likely to recollect the days you finished last than you did first. And that is human nature. Biologists speculate this is part of an evolutionary defence mechanism that you remember the past incidents that led you to trouble, perhaps as a trigger not to repeat them.
Clue 2: Probability
We have seen several examples already. You are entering a billing section of a store that has ten lines. If you pick a random queue, what is the probability that you end up in the fastest? The answer is 1/10. To state it differently, what is the chance that you are not the fastest? Nine out of ten. Then you argue that it was not accidental and that you selected the shortest. There are two possible responses to that feeling.
First, all the others in the hall also (think they) selected the shortest, and your selection, regardless of how you felt, was still random. The second explanation concerns the specific information about your choice that you lacked and the others had. It was short as there was something in that queue – a slower attendant or people with items that required more time for the check-in. And you just took that. Once you are in the line and start measuring the average time taken by the others, you get into what is known as the inspection paradox.
Clue 3: WAITING-TIME PARADOX
We have seen it before in the name of the inspection paradox and waiting time paradox. We proved mathematically that the actual waiting time is longer than the theoretical average calculated based on the frequency of occurrences.
In short
Next time the feeling occurs on why it happened only to you and not anyone else, think again. It is more likely that the others, too, feel the same; after all, the “you” I chose in the description is just an arbitrary choice.
Reference
The formula for choosing the fastest queue: The conversation
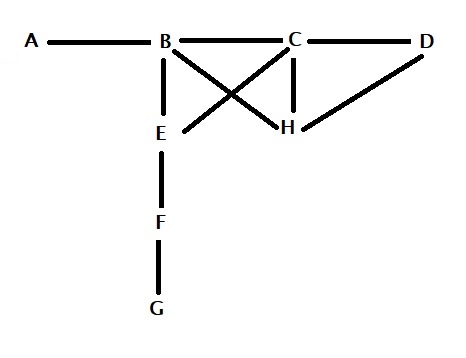




![\\ \text{the average number of friends of friends = } \\\\ \frac{d_A*d_A + d_B*d_B + d_C*d_C + d_D*d_D + d_E*d_E + d_F*d_F + d_G*d_G + d_H*d_H}{d_A + d_B + d_C + d_D + d_E + d_F + d_G + d_H} \\ \\ = \frac{d_A^2 + d_B^2 + d_C^2 + d_D^2 + d_E^2 + d_F^2 + d_G^2 + d_H^2}{d_A + d_B + d_C + d_D + d_E + d_F + d_G + d_H} \\ \\ = \frac{\Sigma{x_i^2}}{\Sigma{x_i}} \\ \\ \text{divide the numerator and the denominator by n} \\ \\ = \frac{\Sigma{x_i^2}/n}{\Sigma{x_i}/n} \\ \\ \text{add and subtract } (\Sigma{x_i})^2/n^2 \text { at the numerator} \\ \\ = \frac{[\Sigma{x_i^2}/n + (\Sigma{x_i})^2/n^2 - (\Sigma{x_i})^2/n^2]}{\Sigma{x_i}/n} \\ \\ = \frac{[\Sigma{x_i^2}/n - (\Sigma{x_i})^2/n^2]}{\Sigma{x_i}/n} + \frac{[(\Sigma{x_i})/n]^2}{\Sigma{x_i}/n} \\ \\ = \frac{[\Sigma{x_i^2}/n - (\Sigma{x_i})^2/n^2]}{\Sigma{x_i}/n} + {\Sigma{x_i}/n}](https://thoughtfulexaminations.com/wp-content/ql-cache/quicklatex.com-786ce585899542d9a42a1b8449675861_l3.png "Rendered by QuickLaTeX.com")