Screen Time and Happiness
The effect of screen time on mental and social well-being is a subject of great concern in child development studies. The common knowledge in the field revolves around the “dispalcement hypothesis”, which says that the harm is directly proportional to the exposure.
Przybylski and Weinstein published a study on this topic in Psychological Science in 2017. The research analysed data collected from 120,115 English adolescents. Mental well-being (the dependent variable) was estimated using the Warwick-Edinburgh Mental Well-Being Scale (WEMWBS ). The WEMWBS is a 14-item scale, each answered on a 1 to 5 scale, ranging from “none of the time” to “all the time.” The fourteen items in WEMWBS are:
| 1 | I’ve been feeling optimistic about the future |
| 2 | I’ve been feeling useful |
| 3 | I’ve been feeling relaxed |
| 4 | I’ve been feeling interested in other people |
| 5 | I’ve had energy to spare |
| 6 | I’ve been dealing with problems |
| 7 | I’ve been thinking clearly |
| 8 | I’ve been feeling good about myself |
| 9 | I’ve been feeling close to other people |
| 10 | I’ve been feeling confident |
| 11 | I’ve been able to make up my own mind about things |
| 12 | I’ve been feeling love |
| 13 | I’ve been interested in new things |
| 14 | I’ve been feeling cheerful |
The study results
I must say, the authors were not alarmists in their conclusions. The study showed a non-linear relationship between screen time and mental well-being. Well-being increased a bit with screen time but later declined. Yet, the plots were in the following form (see the original paper in the reference for the exact graph).
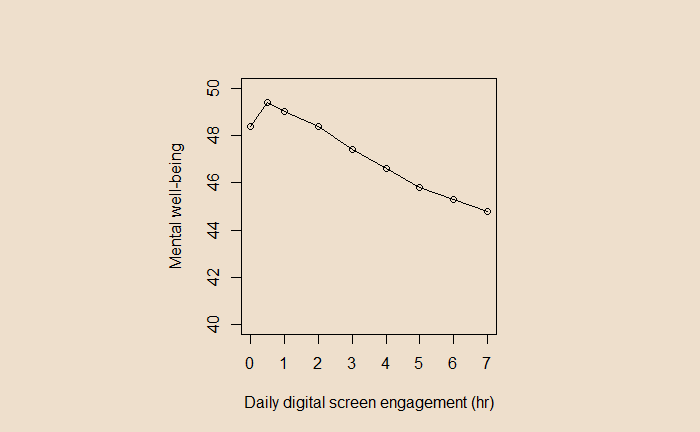
A casual look at the graph shows a steady decline in mental well-being as the screen time increases from 2 hours onwards. Until you notice the scale of the Y-axis!
In a 14-item survey with a 1-5 range in scale, the overall score must range from 14 (min) to 70 (max). Instead, In the present plot, the scale was from 40 to 50, thus visually exaggerating the impact. Had it been plotted following the (unwritten) rules of visualisation, it would have looked like this:

To conclude
Screen time impacts the mental well-being of adolescents. It increases a bit, followed by a decline. The magnitude of the decrease (from 0 screen time to 7 hr) is about 3 points on a 14-70 point scale.
References
Andrew K. Przybylski and Netta Weinstein, A Large-Scale Test of the Goldilocks Hypothesis: Quantifying the Relations between Digital-Screen Use and the Mental Well-Being of Adolescents, Psychological Science, 2017, Vol. 28(2) 204–215.
Joshua Marmara, Daniel Zarate, Jeremy Vassallo, Rhiannon Patten, and Vasileios Stavropoulos, Warwick Edinburgh Mental Well-Being Scale (WEMWBS): measurement invariance across genders and item response theory examination, BMC Psychol. 2022; 10: 31.
Screen Time and Happiness Read More »