The weatherman is Always Wrong
It is easy to prove your weatherman is wrong. Easier if you are short-term memory and are oblivious to probability.
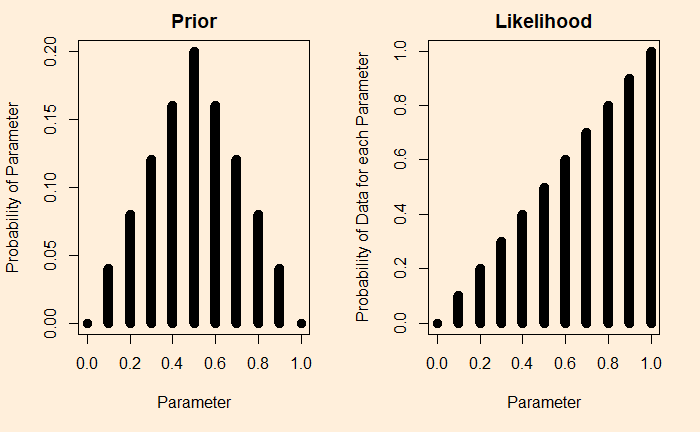
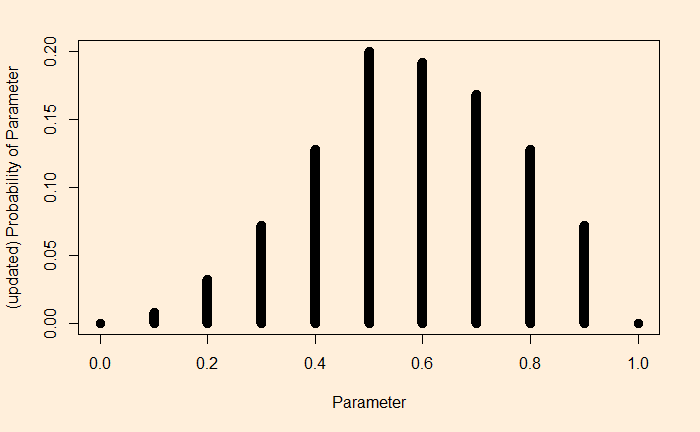
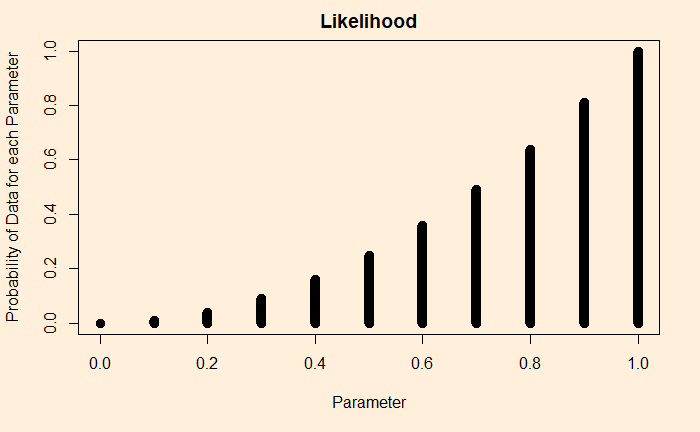
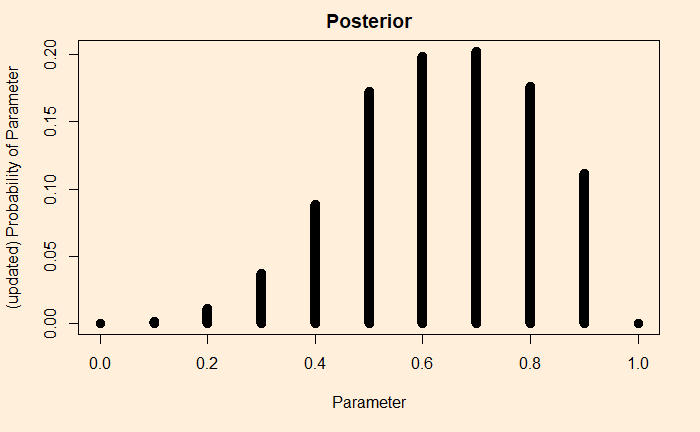
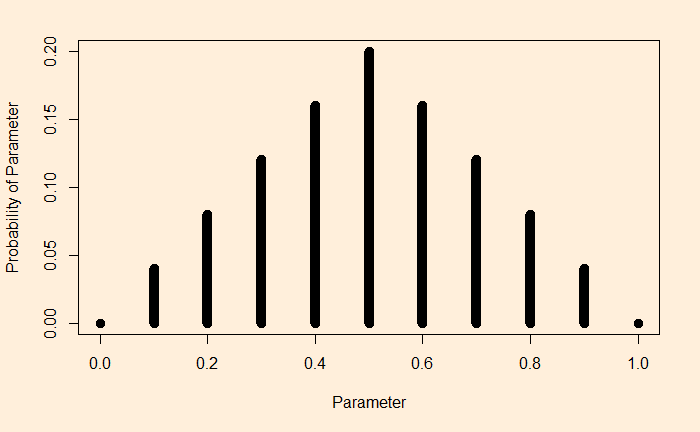
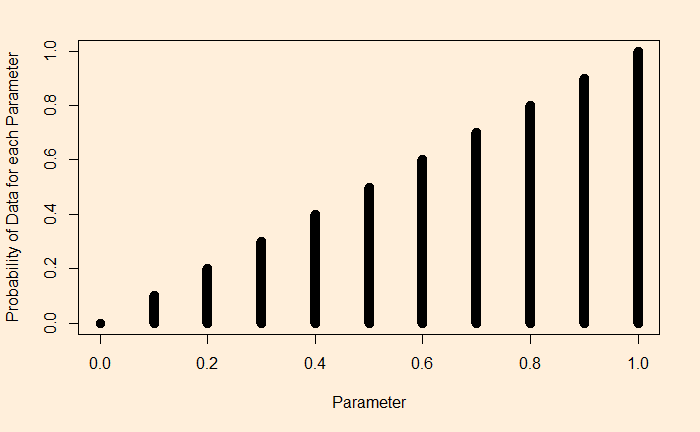
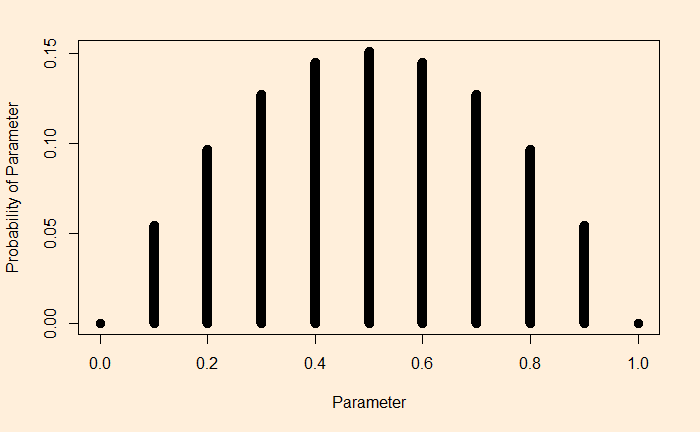
Imagine you tune into your favourite weather program; the prediction was: a 10% chance of rain today. You know what it means: almost a dry day ahead. The same advice continued for the next ten days. What is the chance there was rain on at least one of those days? The answer is not one in ten, but two in three!
You can’t get the answer by guessing or using common sense. You must know how to evaluate the binomial probability. For instance, to calculate the chance of getting at least one rain in the next ten days, you use the formula and subtract it from one.
Decision making
All these are nice, but how does this forecast affect my decision-making? The decision (take a rain cover or an umbrella) depends on the threats and alternate choices. On a day with a 10% chance of rain predicted, I will need a reason to take an umbrella, whereas, on a day of 90%, I need a stronger one not to take precautions.
Why the weatherman is wrong
Well, she is not wrong with her predictions. But the issue lies with us. Out of those tens days, we may remember only the day it rained because it contradicted her forecast of 10%. And the story will spread.
The weatherman is Always Wrong Read More »