In life, your win is not my loss. This is contrary to what used to happen when we were hunter-gatherers, fighting for a limited quantity of meat or in the sporting world, where there is only one crown at the end of a competition. And changing this hard-wired ‘wisdom of zero-sum’ requires conscious training.
The Double ‘Thank You’ Moment
In his essay, The Double ‘Thank You’ Moment, John Stossel uses the example of buying a coffee. After paying a dollar, the clerk says, “Thank you,” and you also respond with a “thank you.” Why? “Because you want the coffee more than the buck, and the store wants the buck more than the coffee. Both of you win.” Except under coercion, transactions lead to positive-sum games; otherwise, the loser wouldn’t have traded.
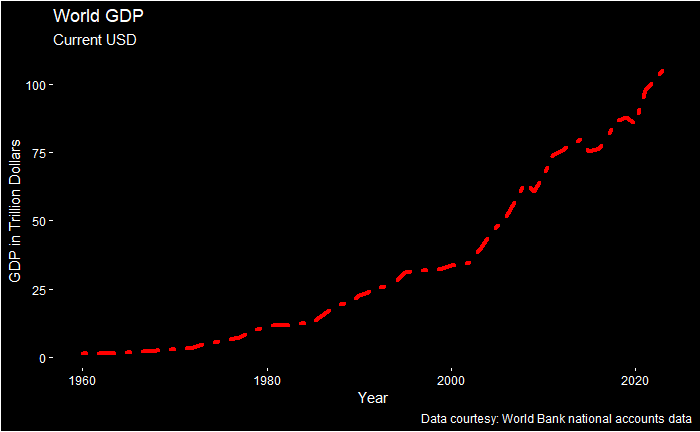
A great example of our world of millions of double thank-you moments is apparent from how the global GDP has changed over the years.
Notice that the shape of the curve is not flat but is exploding lately due to the exponential growth in transactions between people, countries and entities.
Inequality rises; poverty declines
One great tragedy that extends from the zero-sum fallacy is the confusion of wealth inequality with poverty. In a zero-sum world, one imagines that the rich getting richer must be at the expense of the poor! In reality, what matters is whether people are coming out of poverty or not.
A popular flawed argument among fearmongers. It’s an argument of connected occurrences of events leading to a disastrous end state.
The schematic view of the slippery slope fallacy is as follows. 1. If A, then B 2. If B, then C 3. If C, then D 4. not-D Therefore, non-A
Let’s substitute for the steps using a simple example. If you miss this homework (A), you will fail (B) If you fail (B), you miss getting admission to college (C) If you don’t attend a good college (C), you will not get a job (D) If you do not have a job (D), you will be poor and homeless (E) Therefore, you must do the homework.
The proponents of the slippery slope fallacy assign certainty for each step. They consider the impact like a domino, where the fall of one guarantees the collapse of the next. This is far from true in real-life situations where there are probabilities. In the above example, even if the chance for each event to happen is high, say 80%, the overall probability of becoming homeless is less than 50% (0.84).
A notorious example from history for this domino theory is the US involvement in the Vietnam War. The argument of President Eisenhower in 1954 was that if Vietnam were allowed to become a communist state, the neighbouring countries and neighbouring regions would become communists, leading to “incalculable consequences to the free world.”
A fallacy is a bad argument mistaken for a good one. A famous example of a fallacy is: 1. Computers are products of intelligent design. 2. The human brain is a computer. Therefore, the human brain is a product of intelligent design.
It is easy to confuse the above argument with the following valid argument. 1. All A’s are B 2. x is an A Therefore, x is B
So what is wrong with the brain-computer argument, which was right for the A-B? In the A-B statement, A and B must mean the same thing in both arguments. But in the brain-computer case, the term computer has different meanings in two premises. In the second premise (“the human brain is a computer”), the word computer is used broadly – as a system that performs computations.
It is equivocation, i.e., employing two different things by the same name. In the brain-computer argument, we equivocated the word computer to represent two different things that are broadly similar in two premises. In the first premise, the word computer means specifically artificial computers humans built. However, in the second premise, the word was used broadly as an information processing system.
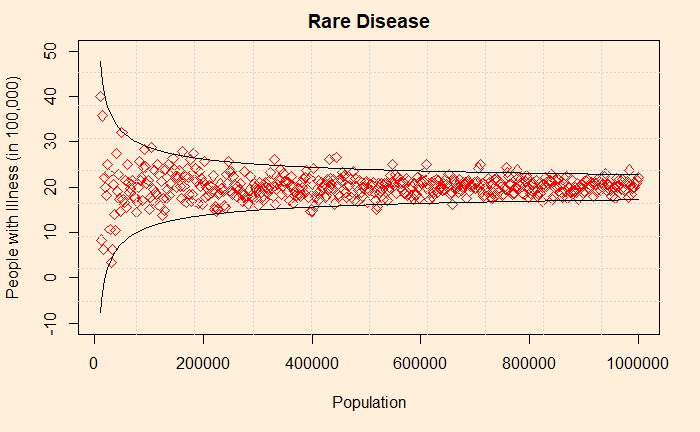
You may remember an older post titled “Life in a Funnel“. It discussed the wired (i.e., extreme) variation of averages (of the rate of certain illnesses, income levels, etc.) arising from groups and places with smaller populations. An often-quoted example is the prevalence of the lowest rates of kidney cancer in the US. These are regions of often rural, sparsely populated, traditionally Republican states. People who come across this data would rationalise this to cleaner air, healthier lifestyles or fresh foods. But when it comes to regions with the highest prevalence of the same disease, they also belong to mostly rural, less populated, Republican!
The incidence of disease is enclosed in a 95% confidence interval.
The plot shows the variability of observed averages simulated from precisely the same incident rate. As the sample size decreases, the sample average goes up or down dramatically, creating an illusion that forces the public to believe something real. This is known as the small sample fallacy. It’s a mistake where one attaches a causal explanation to a statistical artefact due to a smaller sample size.
A simple illustration is to imagine a bowl containing several marbles – 50% red and 50% green. If you take only four samples out of it to check the proportion, there is a 12.5% chance of getting either all green or all red. Work out this binomial probability with p = 0.5, n = 4 and x = 4. P(X=4 red) = 4C4 0.54 0.50 = 0.0625 P(X=4 green) = 4C4 0.54 0.50 = 0.0625 P(all red or all green) = 0.0625 + 0.0625 = 0.125 or 12.5%.
There is a 12.5% chance of seeing an extreme sample average from an otherwise perfectly balanced population. In other words, 12 investigators out of 100 will see a distorted value!
Now, increase the samples to 10, the probability of observing all red or all green reduces dramatically to, P(all red or all green) = 10C10 0.5100.50 + 10C10 0.5100.50 P(all red or all green) = 0.00098 + 0.00098 = 0.00196 or just 0.2%.
Professor Hugo F. Sonnenschein of the University of Chicago explains the famous prisoner’s dilemma differently.
There are two players, A and B, and a moderator. The moderator hands A and B a dollar each and an envelope. Players can keep the dollar in their pocket or leave it inside the envelope. Players then return the envelope to the moderator; the moderator can’t see what each has done. The moderator then looks at the envelopes and doubles the amount she sees inside them. In other words, if she sees a dollar inside the envelope, she makes it two; she doesn’t add anything if she sees nothing.
The moderator then switches the envelopes (envelope A to B and B to A) and gives them back to the players. What is the best strategy for the players to do in the first place—keep the dollar inside the envelope or hold it with them?
Player A can do two things with four possible outcomes; one guarantees a profit.
Keep the dollar in the pocket and return an empty envelope. This guarantees $1 if the other player does the same, or A gets two more dollars if player B is magnanimous (returning her envelope with a dollar in it).
The second option for player A is to return the envelope with one dollar in it. Again, there are two possible outcomes: A gets nothing if player B follows A’s first strategy (keeping a dollar in her pocket) or two if the other returns with a dollar in the envelope.
If you want to be formal with the payoff matrix, here it is.
While it is perfectly understandable that corporation (by each putting their dollars inside the envelope) brings prosperity to both (2 dollars each), the game theory doesn’t work that way. It will give you a strategy that guarantees you a profit irrespective of what the other person would do. In other words, the rational approach is to be selfish.
Let’s try out the Viterbi Algorithm using the example given in theritvikmath channel using R. It is about parts of speech tagging of a sentence, “The Fans Watch The Race”.
The transition and emission probabilities are given in matrix forms.
A doctor wants to diagnose whether a patient has a fever or is healthy. The patient can explain the conditions in three options: “Normal,” “Cold,” or “Dizzy.” The doctor has statistical data on health and how patients feel. If a patient comes to the doctor and reports “normal” on the first day, “cold” on the second, and “dizzy” on the third, how is the diagnosis done?
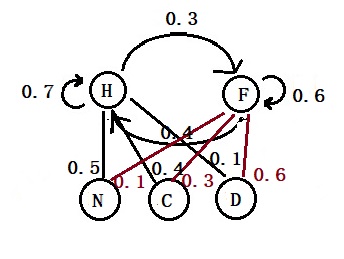
The probability of H today, given it was H the previous day = 0.7 The probability of F today, given it was H the previous day = 0.3 The probability of F today, given it was F the previous day = 0.6 The probability of H today, given it was F the previous day = 0.4 The probability of appearing N, given H, P(N|H) = 0.5 The probability of appearing C, given H, P(C|H) = 0.4 The probability of appearing D, given H, P(D|H) = 0.1 The probability of appearing N, given F, P(N|F) = 0.1 The probability of appearing C, given F, P(C|F) = 0.3 The probability of appearing D, given F, P(D|F) = 0.6
The Viterbi steps are: 1) Estimate prior probabilities of being healthy (H) or fever (F). 2) Calculate the posterior (the numerator) of day 1 using Bayes. 3) Compare the posteriors of the two posteriors (H vs F) and find out the most likely conditions. 4) Use it as the prior for the next day and repeat steps 2 and 3.
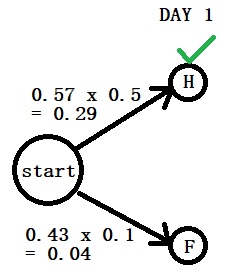
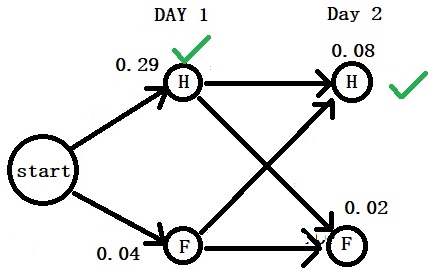
Day 1: “Normal”
Step 2: Calculate the posterior (the numerator) of day 1 using Bayes. P(H|N) = P(N|H) x P(H) = 0.57 x 0.5 P(F|N) = P(N|F) x P(F) = 0.43 x 0.1 You can see the pattern already. The first comes from the transition probabilities (0.57) and the second from the emission (0.5).
Step 3: Compare the posteriors P(H|N) > P(F|N)
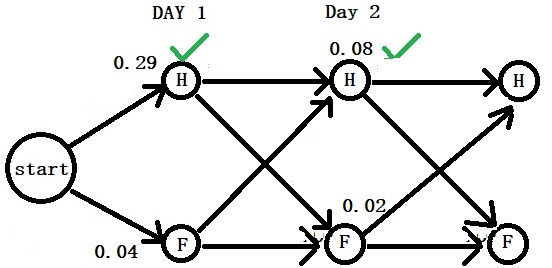
Day 2: “Cold”
Now, we move to the next. Note that we can’t remove the branch that was lower on the first day as it can contribute to the next day.
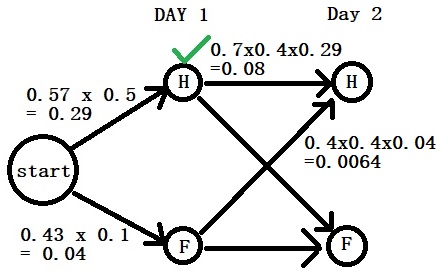
Part 1: We start with Healthy (day 1) – Healthy (day 2) by multiplying the transition probability (0.7) with the emission probability (0.4), and the contribution comes from the earlier step (0.29). 0.7 x 0.4 x 0.29 = 0.08. That is not the only way to arrive at “Healthy”. It can also come from the “Fever” of the previous day. Do the same math: 0.4 x 0.4 x 0.04 = 0.0064
So, there are two ways to arrive at H on the second day. One has a probability of 0.08 (start – H – H), and the other has 0.0064 ((start – C – H)). The first is greater than the second; retain Start-H-H.
0.08 is the maximum probability we carry now for H to fight against F on day 2.
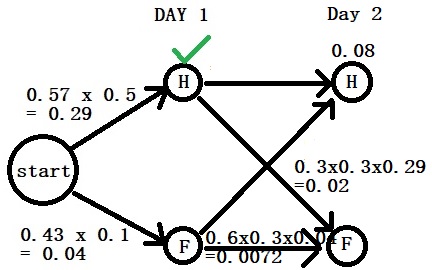
Part 2: Do the same analysis for the maximum probability for F on day 2. Two arrows lead to “Fever”. The first gives a probability of 0.6 x 0.3 x 0.04 = 0.0072, and the second, 0.3 x 0.3 x 0.29 = 0.02. Retain 0.02 as the probability for “Fever” as it is higher than 0.0072.
Final Part: Compete H vs F. 0.08 > 0.02. So H is on day 2 as well.
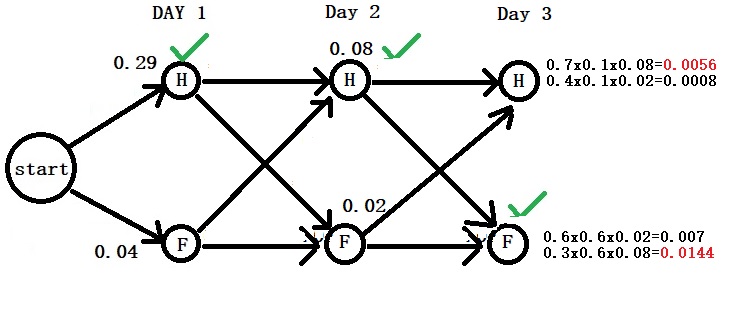
Day 3: “Dizzy”
H-H: 0.7 x 0.1 x 0.08 = 0.0056 F-H: 0.4 x 0.1 x 0.02 = 0.0008 F-F: 0.6 x 0.6 x 0.02 = 0.0072 H-F: 0.3 x 0.6 x 0.08 = 0.0144
Given the patient’s feedback, the assessment would have resulted in Healthy on days 1 and 2 but Fever on day 3.
A doctor wants to diagnose whether a patient has a fever or is healthy. The patient can explain the conditions in three options: “Normal,” “Cold,” or “Dizzy.” The doctor has statistical data on health and how patients feel. If a patient comes to the doctor and reports “normal” on the first day, “cold” on the second, and “dizzy” on the third, how is the diagnosis done?
Before we get to the solution, let’s recognise this as a hidden Markov process. The hidden (latent) variables are “Fever” and “Healthy.” They have translation probabilities. The observed variables are: “Normal,” “Cold,” and “Dizzy.” They have emission probabilities.
The Viterbi algorithm finds the recursive solution of the most likely state sequence using the maximum a posteriori probability. As the earlier post shows, the Bayes equation may estimate the posterior priority. As the objective is to find the maximum a posteriori, we require only its numerator in Viterbi. In our case,
P(H|N) = P(N|H) x P(H)
H represents “Healthy”, and N denotes “Normal”.
The steps are: 1) Estimate prior probabilities of being healthy (H) or fever (F). 2) Calculate the posterior (the numerator) of day 1 using Bayes. 3) Compare the posteriors of the two posteriors (H vs F) and find out the most likely conditions. 4) Use it as the prior for the next day and repeat steps 2 and 3.
Here is the hidden Markov tree, and we will see the calculations next.
Having seen people’s behaviour—whether wearing a raincoat or not—here is the question: Given that you have seen someone wearing a normal coat, what is the probability that it will be a sunny day? For reference, here is the hidden Markov tree.
In the usual math shorthand, we need to find P(S|NC). We can use the Bayes theorem here. P(S|NC) = P(NC|S) x P(S) /[P(NC|S) x P(S) + P(NC|R) x P(R)]
P(NC|S) = probability of wearing a normal coat given it’s sunny. We know it is 0.9 P(NC|R) = probability of wearing a normal coat given it’s rainy. It is 0.4 P(S) = prior probability of today being sunny, i.e., without any clues from the dressing. P(R) = 1 – P(S)
The probability of today being sunny
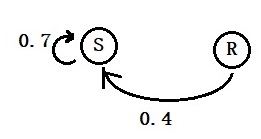
That can be estimated from the transition probabilities as follows. Here is the sunny part of the tree.
S = 0.7 S + 0.4 R
On the other hand,
R = 0.6 R + 0.3 S
To solve the equations, we need one more: S + R = 1. They lead to,