We all know this: “a bird in the hand is worth two in the bush”. It is a timeless proverb that cautioned generations against taking risks and, just as every other proverb, is a monument of simplicity and avoids every rational scrutiny of the present. Whether people believe in this saying or not, there exists a gap in us while estimating the time value of money.
That was what Prof. Shane Frederick found out in the famous Cognitive Reflection Tests (CRT) that he carried out while at MIT. One of his questions was whether the individual goes for $3400 this month versus $3800 next month. The majority of the subjects preferred 3400, leaving the option of getting more than 11% growth in a month. Now compare that with the 2% rate that the world’s best investor could give you!
The results say something about patience and appreciation about rewards at a future date. In that way, it is not so different from the Marshmallow kids!
While my focus was to highlight our attitude towards risk and deferred gratification, I can’t end this piece without quoting the famous 3-item cognitive reflection test. The questions are:
1) If a bat and ball together cost $1.10 in total. The bat costs $1.0 more than the ball. What is the cost of the ball? 2) If it takes 5 machines 5 minutes to make 5 widgets, how long would it take 100 machines to make 100 widgets? 3) In a lake, there is a patch of lily pads. Every day, the patch doubles its size. If it takes 48 days for the patch to cover the entire lake, how long would it take to cover half?
Linda is 31 years old, single, outspoken, and very bright. She majored in philosophy. As a student, she was deeply concerned with issues of discrimination and social justice, and also participated in anti-nuclear demonstrations.
Tversky and Kahneman, Psycological Review (1983)
As part of their study, Tversky and Kahneman gave this problem to 142 UBC undergrads to determine which of the two alternative options was more probable.
Linda is a bank teller.
Linda is a bank teller and is active in the feminist movement.
What is your answer?
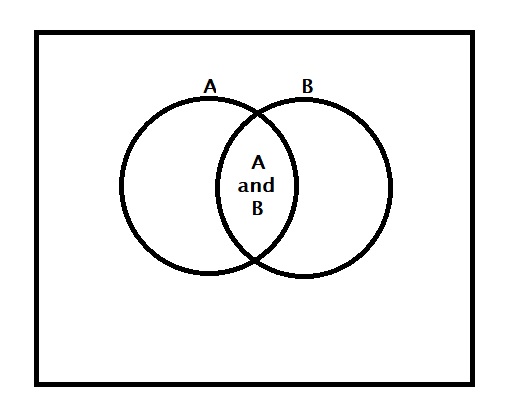
The AND rule
Remember the AND rule? You did not need my post to know the rule; we have accepted it happily at school. 1) it appeared logical. 2) since the probability values are always less than or equal to 1, a product of P(A) and some other probability can never be more than P(A) because that other shall always be one or less. 3) Our teacher explained it graphically using Venn diagrams.
None of us had issues with any of these.
Judgements rooted deep
Yet, 85% of the students selected the second option as the more probable!
Resemblance wins over Extensional
The scientists went to another group of students and asked to choose one statement from the following (far more explicit) options.
Argument 1 Linda is more likely to be a bank teller than a feminist bank teller as every feminist bank teller is a bank teller and some bank tellers are not feminists.
Argument 2 Linda is more likely to be a feminist bank teller than a bank teller because she resembles an active feminist more than she resembles a bank teller.
The students chose the second (65%) in the majority!
There are more examples of conjunction fallacy in our day-to-day lives. Who knows better to exploit this vulnerability of mind than your insurance agent, who can sell you the life insurance that covers deaths from terrorist attacks when you didn’t want to buy the normal one?
Interestingly, this fallacy is not restricted to stories that use rare but appealing words that trigger our imagination. Students were asked to bet on one of three sequences if a six-sided die, with four green faces and two red faces, is rolled 20 times. 1) RGRRR 2) GRGRRR 3) GRRRRR Students overwhelmingly chose option 2, forgetting that option 1 is a subset of option 2!
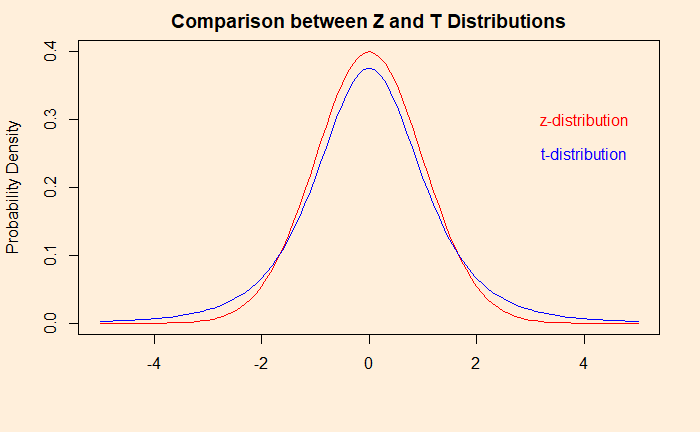
T-test closely resembles Z-test; both follow normal distributions. The t-test is relevant when the population standard deviation is unknown; instead, the sample standard deviation is used. After finding the test statistic, the t-test refers to the t-distribution for significance and p-values instead of the standard normal distribution.
T-distribution, unlike standard normal, is dependent on the sample size and is more spread for smaller values. A key term to remember is the degrees of freedom (df) = sample size – 1. A comparison between the two for a sample size of 5 (df = 4) is below.
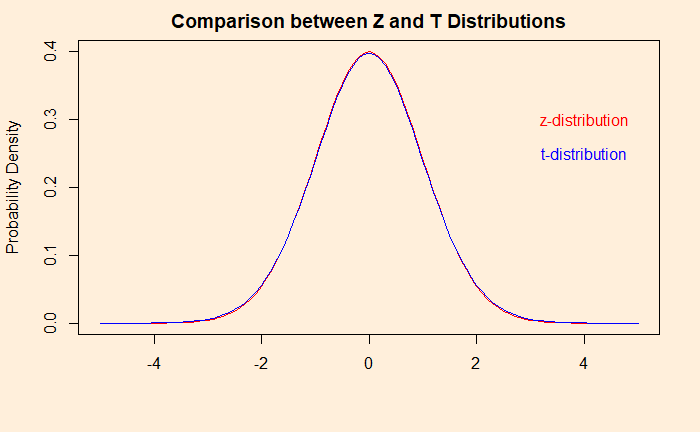
The difference soon disappears as the number of samples goes beyond a few. The plot below compares a sample size of 50.
Coffee Drinking
A researcher studies the coffee drinking habits of people and found that in her city, people drink 14 ml of extra coffee on Mondays (standard deviation of 8.5 ml). Can her results reject the existing average of 10 ml more on Mondays at a 5% significance level?
Let’s set up the null hypothesis: The average extra coffee consumed on Mondays is less than or equal to 10 ml. The alternative hypothesis is: The average extra coffee consumed on Mondays is more than 10 ml. No standard deviation is known for the population; therefore, we take sample standard deviation and t-statistic. t = (14-10)/(8.5 x sqrt(50)) = 3.327. The critical value for 0.05 significance level in a t-distribution with degrees of freedom (df) = 49 is 1.68 [qt(0.95,49) in R]. Since the t-statistic value (3.327) is greater than the t-critical value (1.68), we reject the null hypothesis. The p-value is 0.000838 [pt(3.327, 49, lower.tail = FALSE) in R].
The claim on weight reduction
T-tests can be used to validate claims of interventions by taking statistical differences of the same population between two conditions or time points. Company X claim success for its weight loss drug by showing the following data. You’ll test whether there’s any statistical evidence for the claim (at a 5% significance level).
Before
After
120
114
94
95
86
80
111
116
99
93
78
83
78
74
96
91
132
136
108
109
94
90
88
91
101
100
93
90
121
120
115
110
102
103
94
93
82
81
84
80
The steps are: 1) start with a null hypothesis: the average weight change (after medicine – before medicine) is zero. 2) calculate the weight difference by subtracting before from after (for 20 samples) 3) estimate the mean and standard deviation of the differences 4) population mean (for the null hypothesis) for weight difference is 0. 5) apply the formula for t-statistic 6) compare with critical t-value = -1.72 for 5% significance level 7) estimate the p-value
Difference = After – Before
-6
1
-6
5
-6
5
-4
-5
4
1
-4
3
-1
-3
-1
-5
1
-1
-1
-4
Mean = -1.35, standard deviation = 3.7, t-value = -1.63, critical t = -1.73 (for 5%), p-value = 0.0597 > 0.05
The test shows no evidence to prove the effectiveness, and therefore, the null hypothesis is not rejected. The above treatment is called a paired t-test.
We have seen sample and population statistics in an earlier post. We continue developing from there, but this time using the concepts for hypothesis testing. Suppose we have an established population mean and standard deviation. To that, a new sampling statistic is introduced. The task is to test if the understanding (a.k.a. the null hypothesis) needs an update.
By the way, the resemblance of the equation with the story of constructing the confidence interval is not coincidental. They are both related.
Take an example: A farmer shows sample results (mean = 58 g. from a sample of 40 eggs) and claims eggs from her farm weigh more than the national average. The national average is 54 g. and has a standard deviation of 10 g. How do you test her claim?
First, create the null hypothesis: the farmer’s eggs are within the national average. The alternative hypothesis is that they are heavier than the national. We set a 5% significance level.
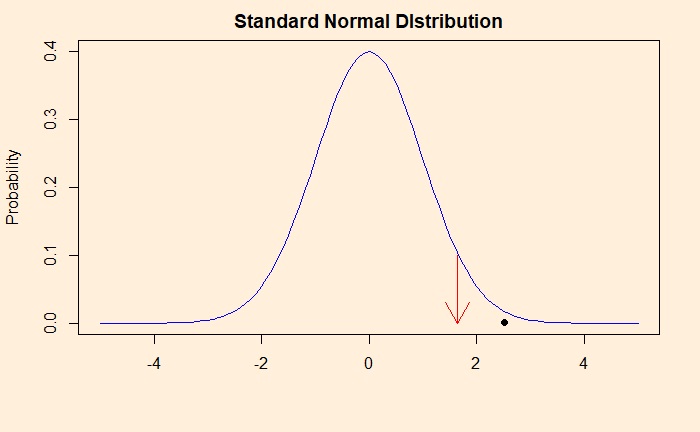
As per the formula, Z = (58-54)/(10 x sqrt(40))= 2.53. Now compare the position of 2.53 in a standard normal distribution, the assumption we made for the Z-statistic. The location of 2.53 is marked as a black dot in the plot below, and the start of the critical region (> 95% or <5%), by the red arrow.
So what is the p-value here? The probability that we observe a z-statistic 2.53 and above, given the null hypothesis. In other words, p is the area under the curve above the value 2.53. You can get that using the R function, pnorm (The function pnorm returns the integral from -infinity to q of the normal distribution where q is a Z-score.) and subtracting it from 1 (the total integral from -infy to +infy). The value of p is 1 – pnorm(2.53) = 1 – 0.9943 = 0.0057.
Farmer’s data has only a 0.57% chance to stand with the null hypothesis. So we reject the null hypothesis and accept the notion that the farmer’s eggs are heavier than the national average.
The concept of p-value is one complicated setting in statistics. As per the renowned writer, cognitive psychologist, and intellectual Steven Pinker, 90% of psychology professors get it wrong! Where did he get this 90%? Well, my default position (the null hypothesis) is that Steven Pinker is a no-nonsense writer. So, I confidently take 90% as my prior. I also find it super confusing (how is it relevant in a statistical setting?).
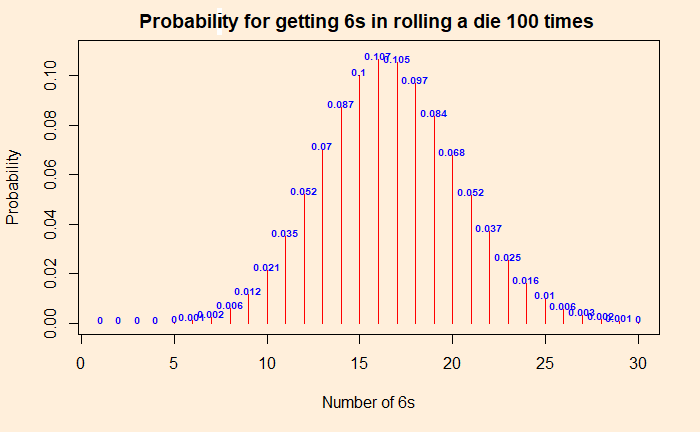
Two people are playing a game of rolling dice. One person suspects that the die was faulty, and the other (as always!) is getting too many 6s. To test the assumption, they decide to roll it 100 times. The result was 22 sixes. Since the probability of getting a six is (1/6), and the number of rolls was 100, she argues, the expected number of sizes was 16.6. Since they got 22 sixes, the die is defective.
By now, we know that the above argument was wrong. It is not how probability and randomness work. The experiment is equivalent to independent Bernoulli trials with the following distribution of chances for each number of sixes. Let the force of “dbinom” be with you and get the probability distribution. Probabilities for the “dbinom” are (1/6) for success and (5/6) for failure (not a 6).
The probability of getting precisely 22 sixes is 4%, but 22 or more is ca. 11%.
The proper way
You got to start with a hypothesis. Since statisticians are statisticians and wanted to maintain a scientific temper, they created a concept called the null hypothesis as the default. Here the null hypothesis is: that the die is fair and will follow the binomial distribution as shown in the plot above. If you want to prove the die is defective, you need to demonstrate the null hypothesis to be invalid and reject it.
Proving beyond doubt
We have to prove that getting 22 sixes is within 5% of the most extreme values the dice can give in 100 rolls. Why 5%? It is just a convention and is called the significance level. We define the p-value and have to prove that it is smaller than or equal to the significance level to reject the null hypothesis (or prove your point). Else accept the null hypothesis (and acknowledge that you are unsuccessful).
Enter p-value
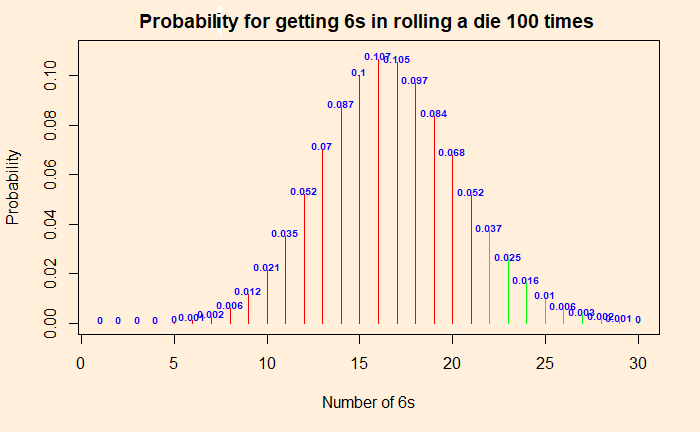
The p-value is the probability of getting numbers at least as extreme as 22. At least as extreme as 22 means: chance of getting 22 + chances of getting anything more extreme than 22! So it is the sum of 0.037 + 0.025 + 0.016 + 0.01 + 0.006 + 0.003 + 0.002 + 0.001 = 0.1 = 10%. The p-value is 10%. This is more than the significance level of 5%, and therefore we can’t reject the null hypothesis that the die is good. No evidence. To repeat, if you do the same experiment 100 times over and over, you may get 22 or more 6s one out of 10 times. To prove the die is faulty, it must reduce to one in 20 (or lower).
P for Posterior
The significance test through p has a twisted logic. p is the probability for my data given the (null) hypothesis. In other words, while you intend to prove your point, the world (or science) wants to compare it with its default, null hypothesis. The smaller the chance, you win, and the prior gives way to the posterior. My theory wins because the data collected was unlikely if the null hypothesis is true.
Tailpiece
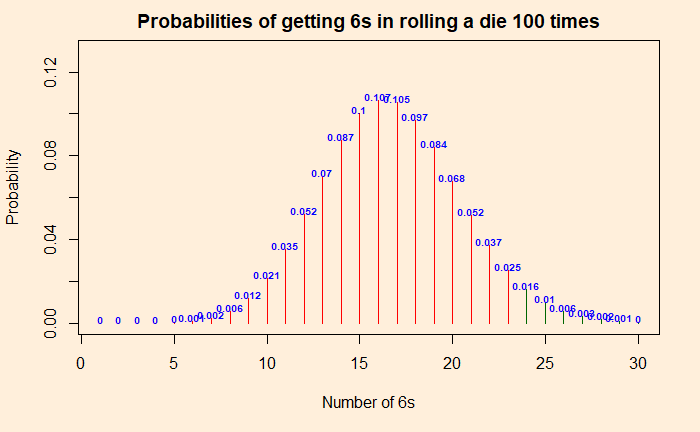
Going to more extreme values, you will see that the probability of getting 24 or more times 6 is less than 5%. So if you throw 6s 24 or more times, you are in the critical region, and you can prove the die is faulty.
The critical region is in dark green
Typically, a p-value below 0.01 signifies strong evidence, 0.05 – 0.01 is moderate, and 0.05 – 0.1 is weak evidence against the null hypothesis in favour of the alternative. p greater than 0.1 is considered as no evidence against the null hypothesis.
Steven Pinker: Rationality: What It Is, Why It Seems Scarce, Why It Matters
Was the Challenger disaster an avoidable incident, or it’s just a hindsight bias?
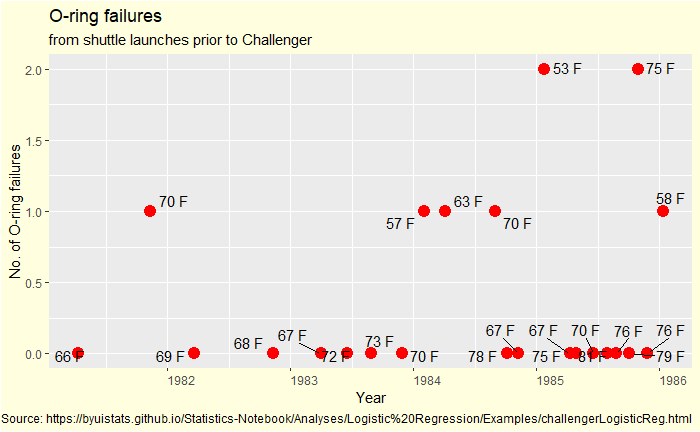
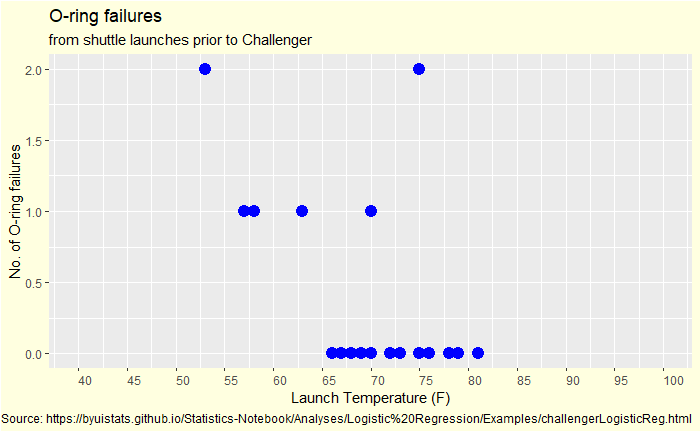
On January 28, 1986, seven crew members of the United States space shuttle Challenger were killed when O-rings responsible for sealing the joints of the rocket booster failed and caused a catastrophic explosion.
Machine Learning with R by Brett Lantz
First, look at what data would have been available to the project.
A few scattered points spread over five years, covering 23 previous examples. You don’t need to search for many patterns in this plot; check for any long-term improvements in incident rate (learning over the years). I see none; therefore, the data from 1981 was not outdated for 1986!
Now we plot it differently – failed O-rings vs outside temperature.
Outside-the-box problem
First observation: no data is available below 50 oF, and the outside temperature at the time of launch tomorrow is 30 oF. You have seen up to 2 out of 6 O-ring failures in the past. How do you know if everything will be alright if you operate so far outside the data limits?
But, how do I know?
A material scientist may have predicted increased brittleness (for the elastomer) with the drop in outside temperature. I would not call it hindsight wisdom as it was science and they have field data (from previous launches) to support it.
A statistician may guess it using Bayesian thinking by choosing the data from the nearest temperature as the prior. That data is at 53 oF, which resulted in 2 O-ring failures.
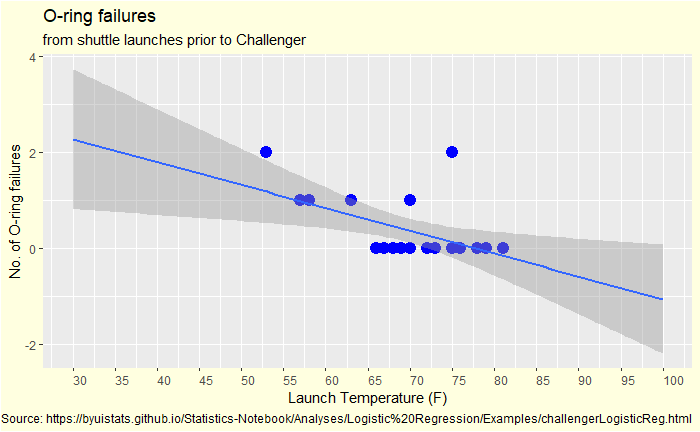
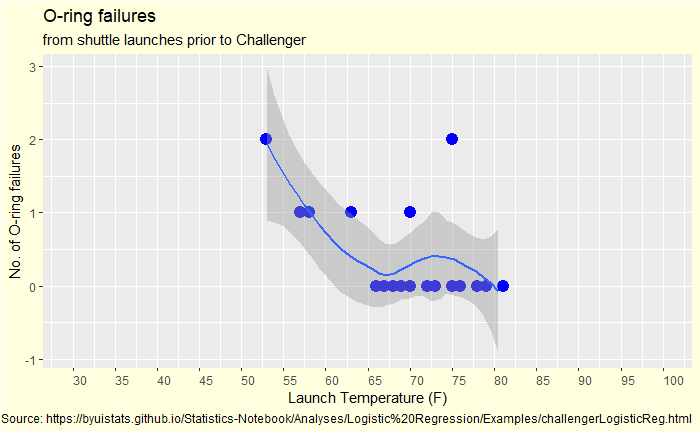
A data analyst would have done an extrapolation starting with a linear fit. And how would that look?
A line that went northwest as the temperature decreased. Or another type of data fit.
What was the real issue?
The Challenger incident was not about data analysis but quality assurance and decision-making. The project leaders had all the necessary information to make the decision and stop the launch, still went ahead and blasted (literally!) the space shuttle, killing all the crew members. It was irrationality of mind. Irrationality fuelled the emotional forces of pride, stubbornness, close-mindedness, and bravado.
Walter Mischel’s marshmallow test was a milestone experiment in understanding the cognitive mechanisms of willpower. It goes in two parts – the initial experiments he and his team carried out in the late sixties and early seventies. The second part was establishing correlations of those test results with the test subject’s long term success in life. We will not go into the second part as, I suspect, it had a lot of subjective or potentially confounding effects, which is outside the simple realm of data analytics.
The paper published in 1972 in the Journal of Personality and Social Psychology, which follows up from his 1970 paper in the same journal, is the subject in today’s post. The objective of the test was to find out how young children (preschool kids, aged between 3.5 to 5.5 years) managed to delay the gratification of eating their favourite sweets under various experimental conditions. The neatness of the paper is that it doesn’t theorise a lot about cognitive abilities but rather gives data on how average children postponed their urge to eat (marshmallow or pretzel) under various distraction conditions.
There were three experiments in total; the first had five batches of children (total 50), the second (32) and the third (16) had three each.
The Task
Except for the last batch of three experiments, sweets were placed in front of the children. They had the option to eat their favourite sweet by calling the experimenter or win the second sweet (reward) if they had delayed gratification and waited until the experimenter came back. The experimenter recorded the time taken by each child before yielding to temptation. As the main variable, different distraction opportunities were given to the children. These are:
Group
Objective
Distraction technique
Mean waiting time
1
Wait for contingent reward (visible)
Toy
9 min
2
Wait for contingent reward (visible)
Think Fun
12 min
3
Wait for contingent reward (visible)
None (control)
< 1 min
4
No contingent reward
Toy (control)
2 min
5
No contingent reward
Think Fun (control)
1 min
6
Wait for contingent reward (visible)
Think Fun
13 min
7
Wait for contingent reward (visible)
Think Sad
5 min
8
Wait for contingent reward (visible)
Think Rewards
4 min
9
Wait for contingent reward (hidden)
No Ideation
13 min
10
Wait for contingent reward (hidden)
Think Fun
14 min
11
Wait for contingent reward (hidden)
Think rewards
1 min
Summary
One startling finding was that children were willing to wait for a longer time when they were immersed in happy feelings, irrespective of whether the rewards were visible to them or not. Thinking about sweets and sad feelings were both unsuccessful in building willpower. The torture of thinking about the prize was no different from any other sad feelings!
This post follows from an article titled “Keep on trucking”, published in The Economist.
Zero-sum games are templates hard-wired to our brains. We have seen a possible reason for this your-win-is-my-loss syndrome. The cognitive bias towards zero-sum thinking is sometimes called the fixed pie fallacy. Examples are everywhere – immigration, retirement ages, computerisation, outsourcing, the list is endless!!
Take, for example, the argument against the increase of retirement age. Part of the society, the younger lot, genuinely feel either their progress will stall or new opportunities will dry out due to the older generation keeping their jobs for longer.
The lump-of-labour fallacy, so it is known, is very appealing to everybody. But the data suggest something else. In developed economies, the higher employment rate of the old (55-64) is often positively correlated to a higher rate for the young (15-24). Reports of ILO can tell similar stories on migration – correlation between increased prosperity of the economy and the presence of migrant workers.
This fallacy appeals to most due to the simplistic picture it presents – a fixed amount of wealth that can only be exchanged between people, a form of the law of conservation of wealth. They conveniently forget human history. Wealth creation is the story of the modern world. Imaginative and innovative economies grew faster than inward-looking ones. Think about the cost to society when a person is retired. She no longer contributes but withdraws from public (pension) funds. In other words, part of the money from the younger lot goes out from the funds, built on bonds or equities, which could otherwise get more time to circulate and compound. On the other hand, if older people are still in the workforce, they spend, and money comes back to the economy, creating more (diverse types of) jobs that employ more, and the cycle continues.
The economies that kick part of their people out to employ the next batch are doing so either due to ignorance or because their economies are genuine candidates for zero-sum. Such economies are unlikely to prosper due to the same reason – the lack of imagination and growth mindset. We have ample examples to support from the last 300 years of human history.
We continue the topic of zero-sum games and rock paper scissors. Winnie and Lucy have now decided to embark on a million-round game of rock paper scissors. They have done their preparations very meticulously, and they are ready. Let’s start following them with the simulations of their expected game and scores.
W: 33.3; L: 33.3. If they both follow a random strategy, giving equal weightage to each of the three options, the expected results are a third for each outcome (win, loss, tie).
After about 1000 games, Lucy notices that Winnie have a slight bias towards the rock. Since she counted hands, Lucy thinks it is around (1.2/3). Note that it did not affect the overall results, which is still at W: 33.3 L: 33.3
Lucy sees the opportunity and adjusts her game. She increases the paper to 1.2 in 3 and starts to see the results in the next 1000 games. W: 33.0 L: 34.0
She also reduced the proportion of scissors from her kitty and found that her winning margin increased slightly. W:32.7 L: 34.0
Lucy now knows that providing the paper with a higher chance (1.5/3) could fetch an even better margin, she, however, doesn’t attempt for it, suspecting Winnie would figure it out.
Lucy did not know that Winnie used to be the junior champion in her college days. Winnie was testing Lucy by giving the bait to change her from a random strategy to having a bias. Noting Lucy has changed to a more-paper-strategy, Winnie changes to a scissor biased game (1.2/3). W: 34.0 L: 33.3
Lucy noticed it after about 1000 games. Now Lucy knows Winnie knows Lucy knows. Or strategy is getting common knowledge. She has only one way out. Go back to random. The outcome is back at 33.3% for both, irrespective of what Winnie did.
In Summary
The best strategy to win a game of rock paper scissors is that there are no strategies unless the opponent gives one. Otherwise, you stick to random choices and leave the results to randomness in the short run, or if you are on a day-long game, a likely stalemate.
Zero-sum game. We use a rock-paper-scissors game to explain a zero-sum game. The game is played between two players, in which the players simultaneously show a rock, paper or scissors, using hand gestures. The rule is: rock breaks scissors, scissors cut paper and paper covers rock. The winner gets one point, and the loser loses 1. If both show the same gesture, they get nothing. Let’s write down the payoff matrix (refer to game theory).
Winnie
Rock
Paper
Scissors
Rock
L = 0, W = 0
L = -1, W = 1
L = 1, W = -1
Lucy
Paper
L = 1, W = -1
L = 0, W = 0
L = -1, W = 1
Scissors
L = -1, W = 1
L = 1, W = -1
L = 0, W = 0
So, Winnie’s loss can only come from Lucy’s win or vice versa. If they both show the same hand, the game offers no points. In other words, if you sum each of the cells in the table, you get zero. It is a zero-sum game.
Several games follow this pattern – grand slam tennis matches, football (soccer) games in the knockout stages, NBA, to name a few. Irrespective of how much or how little zero-sum games represent our real life, the notion is hard-wired in the brain thanks to popular culture (the good at the expense of the bad) or high profile presidential elections (Republicans’ loss is Democrats gain).
Sometimes, playing for a tie in the league phase of a football tournament can be a strategy for a team (or both teams) to advance to a playoff / knockout round. Similarly, coalition governments are real possibilities in several countries. These are all examples of win-win situations.