A doctor wants to diagnose whether a patient has a fever or is healthy. The patient can explain the conditions in three options: “Normal,” “Cold,” or “Dizzy.” The doctor has statistical data on health and how patients feel. If a patient comes to the doctor and reports “normal” on the first day, “cold” on the second, and “dizzy” on the third, how is the diagnosis done?
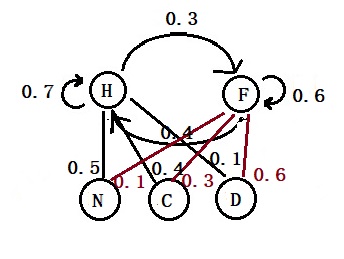
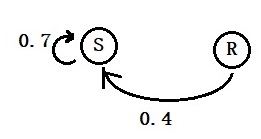
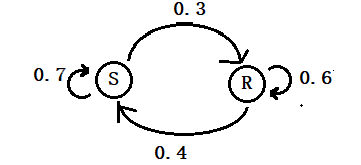
The probability of H today, given it was H the previous day = 0.7 The probability of F today, given it was H the previous day = 0.3 The probability of F today, given it was F the previous day = 0.6 The probability of H today, given it was F the previous day = 0.4 The probability of appearing N, given H, P(N|H) = 0.5 The probability of appearing C, given H, P(C|H) = 0.4 The probability of appearing D, given H, P(D|H) = 0.1 The probability of appearing N, given F, P(N|F) = 0.1 The probability of appearing C, given F, P(C|F) = 0.3 The probability of appearing D, given F, P(D|F) = 0.6
The Viterbi steps are: 1) Estimate prior probabilities of being healthy (H) or fever (F). 2) Calculate the posterior (the numerator) of day 1 using Bayes. 3) Compare the posteriors of the two posteriors (H vs F) and find out the most likely conditions. 4) Use it as the prior for the next day and repeat steps 2 and 3.
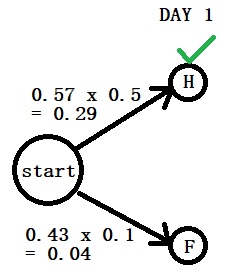
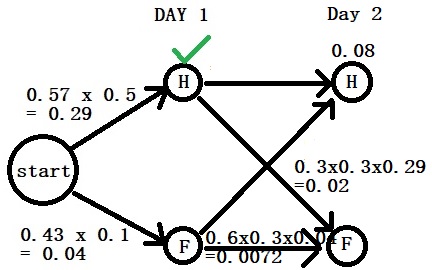
Day 1: “Normal”
Step 2: Calculate the posterior (the numerator) of day 1 using Bayes. P(H|N) = P(N|H) x P(H) = 0.57 x 0.5 P(F|N) = P(N|F) x P(F) = 0.43 x 0.1 You can see the pattern already. The first comes from the transition probabilities (0.57) and the second from the emission (0.5).
Step 3: Compare the posteriors P(H|N) > P(F|N)
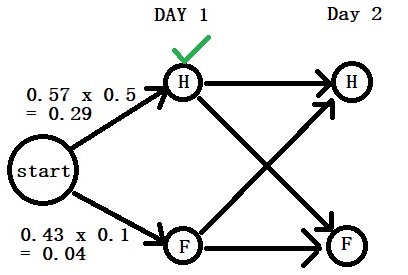
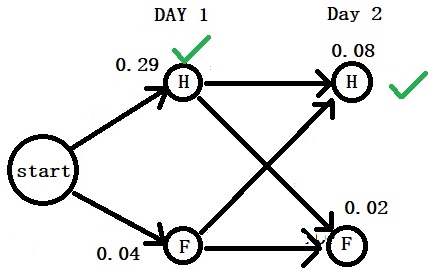
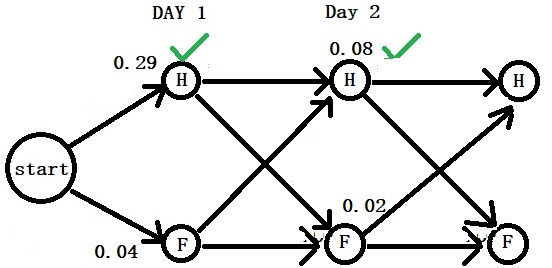
Day 2: “Cold”
Now, we move to the next. Note that we can’t remove the branch that was lower on the first day as it can contribute to the next day.
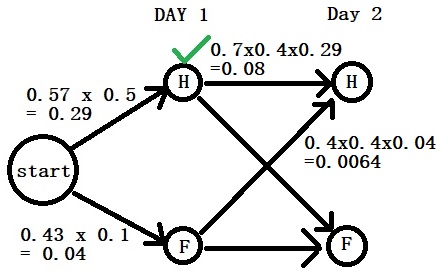
Part 1: We start with Healthy (day 1) – Healthy (day 2) by multiplying the transition probability (0.7) with the emission probability (0.4), and the contribution comes from the earlier step (0.29). 0.7 x 0.4 x 0.29 = 0.08. That is not the only way to arrive at “Healthy”. It can also come from the “Fever” of the previous day. Do the same math: 0.4 x 0.4 x 0.04 = 0.0064
So, there are two ways to arrive at H on the second day. One has a probability of 0.08 (start – H – H), and the other has 0.0064 ((start – C – H)). The first is greater than the second; retain Start-H-H.
0.08 is the maximum probability we carry now for H to fight against F on day 2.
Part 2: Do the same analysis for the maximum probability for F on day 2. Two arrows lead to “Fever”. The first gives a probability of 0.6 x 0.3 x 0.04 = 0.0072, and the second, 0.3 x 0.3 x 0.29 = 0.02. Retain 0.02 as the probability for “Fever” as it is higher than 0.0072.
Final Part: Compete H vs F. 0.08 > 0.02. So H is on day 2 as well.
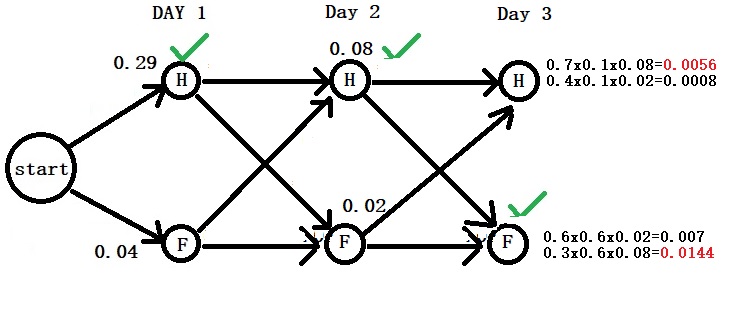
Day 3: “Dizzy”
H-H: 0.7 x 0.1 x 0.08 = 0.0056 F-H: 0.4 x 0.1 x 0.02 = 0.0008 F-F: 0.6 x 0.6 x 0.02 = 0.0072 H-F: 0.3 x 0.6 x 0.08 = 0.0144
Given the patient’s feedback, the assessment would have resulted in Healthy on days 1 and 2 but Fever on day 3.
A doctor wants to diagnose whether a patient has a fever or is healthy. The patient can explain the conditions in three options: “Normal,” “Cold,” or “Dizzy.” The doctor has statistical data on health and how patients feel. If a patient comes to the doctor and reports “normal” on the first day, “cold” on the second, and “dizzy” on the third, how is the diagnosis done?
Before we get to the solution, let’s recognise this as a hidden Markov process. The hidden (latent) variables are “Fever” and “Healthy.” They have translation probabilities. The observed variables are: “Normal,” “Cold,” and “Dizzy.” They have emission probabilities.
The Viterbi algorithm finds the recursive solution of the most likely state sequence using the maximum a posteriori probability. As the earlier post shows, the Bayes equation may estimate the posterior priority. As the objective is to find the maximum a posteriori, we require only its numerator in Viterbi. In our case,
P(H|N) = P(N|H) x P(H)
H represents “Healthy”, and N denotes “Normal”.
The steps are: 1) Estimate prior probabilities of being healthy (H) or fever (F). 2) Calculate the posterior (the numerator) of day 1 using Bayes. 3) Compare the posteriors of the two posteriors (H vs F) and find out the most likely conditions. 4) Use it as the prior for the next day and repeat steps 2 and 3.
Here is the hidden Markov tree, and we will see the calculations next.
Having seen people’s behaviour—whether wearing a raincoat or not—here is the question: Given that you have seen someone wearing a normal coat, what is the probability that it will be a sunny day? For reference, here is the hidden Markov tree.
In the usual math shorthand, we need to find P(S|NC). We can use the Bayes theorem here. P(S|NC) = P(NC|S) x P(S) /[P(NC|S) x P(S) + P(NC|R) x P(R)]
P(NC|S) = probability of wearing a normal coat given it’s sunny. We know it is 0.9 P(NC|R) = probability of wearing a normal coat given it’s rainy. It is 0.4 P(S) = prior probability of today being sunny, i.e., without any clues from the dressing. P(R) = 1 – P(S)
The probability of today being sunny
That can be estimated from the transition probabilities as follows. Here is the sunny part of the tree.
S = 0.7 S + 0.4 R
On the other hand,
R = 0.6 R + 0.3 S
To solve the equations, we need one more: S + R = 1. They lead to,
We have seen how states move from one to another and the translation probabilities. It models a sequence in which the probability of the following (n+1) event depends only on the state of the previous (n) event. That is normal, Markov, where we can see the states. Imagine we can’t directly observe the states but only observe some indications. That is hidden Markov.
An often-used example is observing people’s attire and estimating if it’s sunny or rainy.
If it rains today, there is a 60% chance it will rain the next day and a 40% chance it will be sunny. If it’s sunny today, there is a 70% chance it will be sunny tomorrow, and 30% will be rainy.
But you can’t observe that. All you see is people wearing a raincoat or normal clothes. If it rains, there is a 60% chance you will see people wearing raincoats and 40% normal clothes. If it’s sunny, there is a 90% chance you will see people wearing normal clothes and 10% rain clothes.
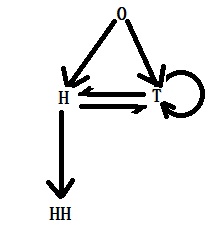
What is the average number of tosses required for a coin to give four consecutive heads?
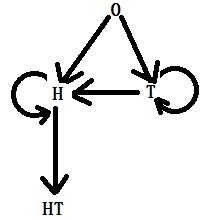
We will solve this as a Markov chain problem. We start with stage 0. At stage 0, two possibilities exist when flipping a coin – H or T. H is counted as one in the right direction, whereas T means you are back to stage 0. From an H, the next flip can lead to HH or 0 with equal probabilities. So, the transition matrix is:
Some time ago, we analytically estimated the expected waiting times of sequences HT and HH from coin-flipping games. Today, we calculate them using Markov chains.
Waiting time for HT
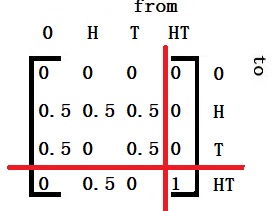
First, the notations, followed by the transition matrix:
Get Q, I – Q and its inverse
AA <- matrix(c(0.0, 0.5, 0.5,
0.0, 0.5, 0.0,
0.0, 0.5, 0.5), nrow = 3)
II <- matrix(c(1, 0, 0,
0, 1, 0,
0, 0, 1), nrow = 3)
BB <- II - AA
CC <- solve(BB)
NN <- c(1, 1, 1)
NN%*%CC
4 2 4
The average waiting time from 0 to HT is the first element in the vector, i.e., 4.
Waiting time for HH
AA <- matrix(c(0.0, 0.5, 0.5,
0.0, 0.0, 0.5,
0.0, 0.5, 0.5), nrow = 3)
II <- matrix(c(1, 0, 0,
0, 1, 0,
0, 0, 1), nrow = 3)
BB <- II - AA
CC <- solve(BB)
NN <- c(1, 1, 1)
NN%*%CC
We have seen two ways of solving the end-stage distribution of cities in the example of Amy’s random walk to her friends. Method #1 is to multiply the transition matrix with itself n times and finally multiply with the initial-state distribution. Method #2 is to solve the equation, P X* = X*.
There is a third method: find the first eigenvector of the transition matrix and normalise it (i.e., divide it with the sum of elements to make the total distribution 1). We will manage it using an R program that has an inbuilt function to calculate the higher vector.
Remember the cat-and-mouse game? We calculated the expected time for the mouse on door # 4 to reach the cat. As we know the Markovian technique, we will solve the problem using absorbing chains. Here is the situation with arrows representing the mouse’s stage-by-stage movement.
We follow the steps described in the previous post. Step 1: Construct the transition probability matrix Step 2: Isolate I and make Q Step 3: Subtract Q from the Identity matrix Step 4: Calculate the inverse of (I – Q)
In step 1, we re-arrange the columns and get the identity matrix cornered.
We have seen the concept of absorbing Markov chains. Here is a problem illustrating the idea.
A law firm has three types of employees: junior lawyers, senior lawyers, and partners. During a year There is a 0.15 probability that a junior will get promoted to a senior 0.05 probability a junior leaves the firm 0.20 probability that a senior will get promoted to a partner 0.1 probability a senior leaves the firm 0.05 probability that a partner leaves the firm
What is the average number of years a junior stays in the company?
Step 1: Construct the transition probability matrix
J stands for junior, S for senior, P for partner, L for leaving and PL for partner leaving
Step 2: Isolate I and make Q
If required, re-arrange the transition matrix and identify the unit matrix (corresponding to the absorbing).
After removing the columns and rows corresponding to the identity matrix, you are left with Q.
Add numbers corresponding to each category (column) to determine the average number of stages (years). For example, a junior to stay 5 + 2.5 + 10 = 17.5 years. A senior will remain at an average of 3.3 + 13.3 = 16.6, and Partners will persist an average of 20 years before leaving.