Cards from a Deck
If you draw cards from a well-shuffled deck of cards, what is the probability that you get an Ace of Hearts and a black card?
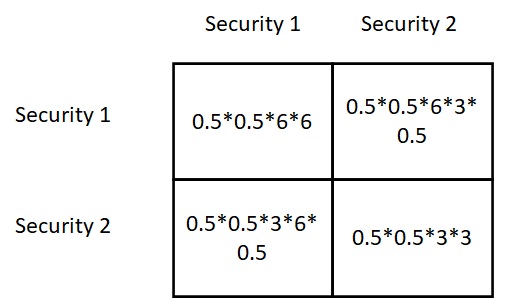
There are two different probabilities this can happen.
- An ace of hearts followed by a black card
- A black card followed by an ace of hearts
The probability for 1) is (1/52) x (26/51) and for 2) is (26/52) x (1/51). Add them up: (2 x 26)/(51 x 52) = 1/51
If you want to verify the results, you may shuffle the deck a million times and count:
suits <- c("Diamonds", "Spades", "Hearts", "Clubs")
face <- c("Jack", "Queen", "King")
numb <- c("Deuce", "Three", "Four", "Five", "Six", "Seven", "Eight", "Nine", "Ten")
face_card <- expand.grid(Face = face, Suit = suits)
face_card <- paste(face_card$Face, face_card$Suit)
numb_card <- expand.grid(Numb = numb, Suit = suits)
numb_card <- paste(numb_card$Numb, numb_card$Suit)
Aces <- paste("Ace", suits)
deck <- c(Aces, numb_card, face_card)itr <- 1000000
shuff <- replicate(itr, {
draw <- sample(deck, 2, replace = FALSE, prob = rep(1/52, 52))
dr <- "Ace Hearts" %in% draw & (any(str_detect(draw, "Spades|Clubs")))
if(dr == TRUE){
counter <- 1
}else{
counter <- 0
}
})
mean(shuff)