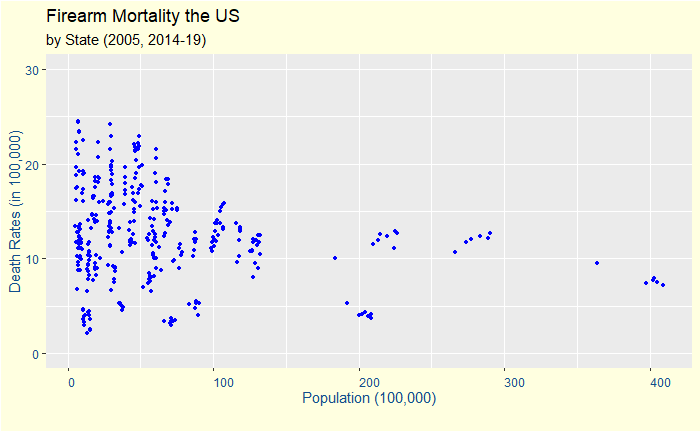
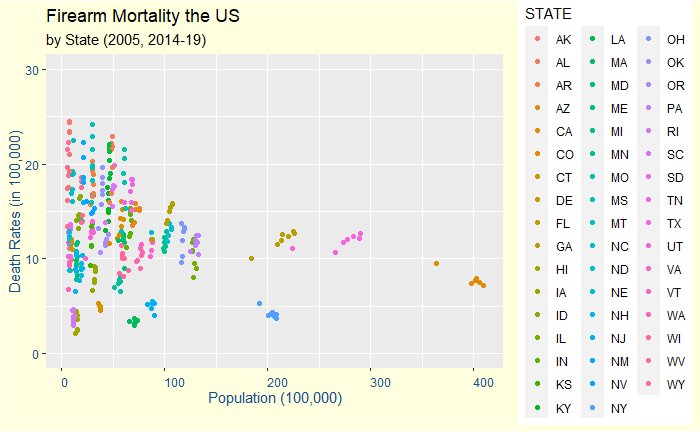
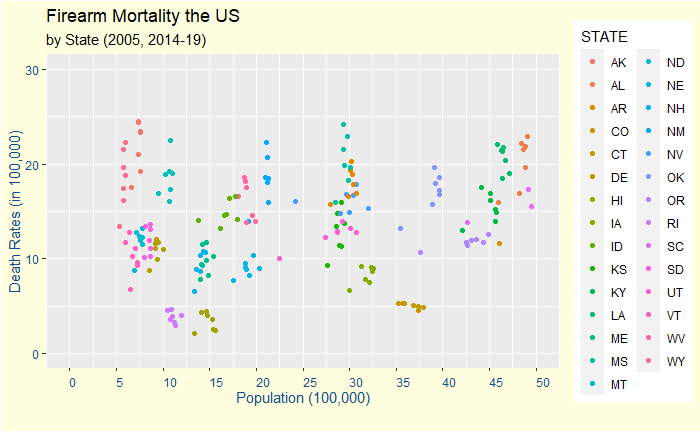
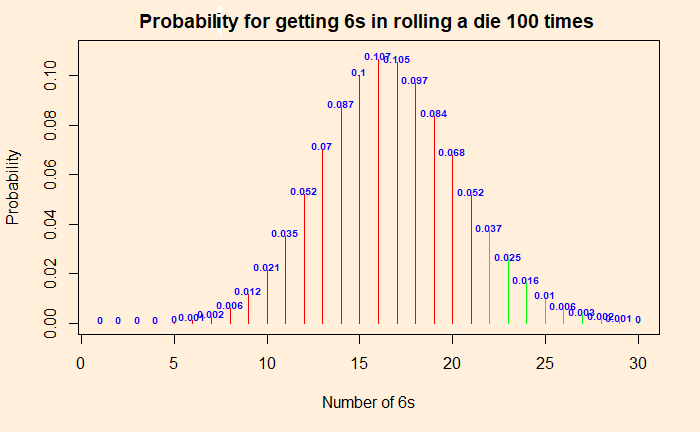
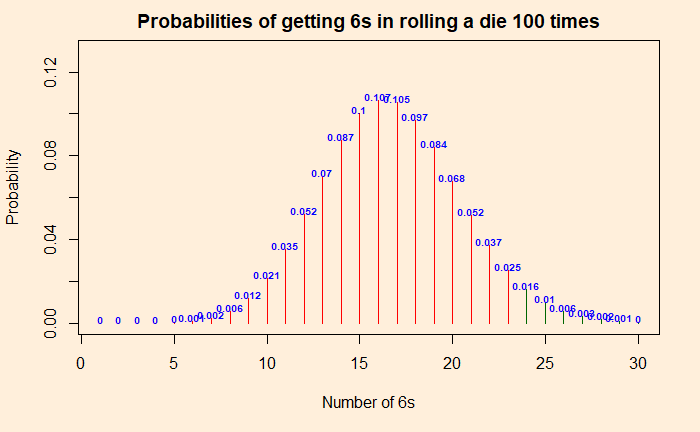
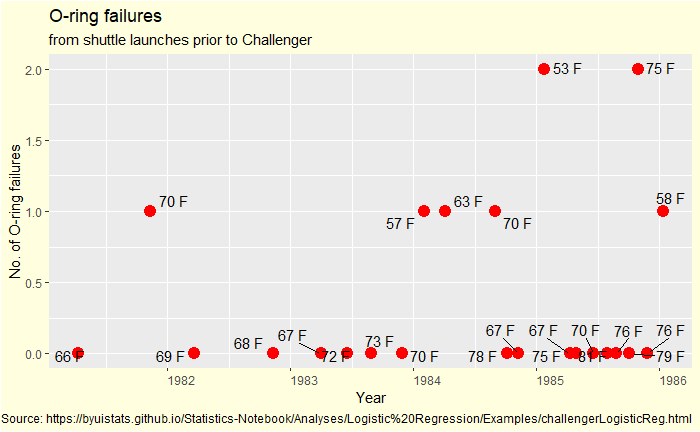
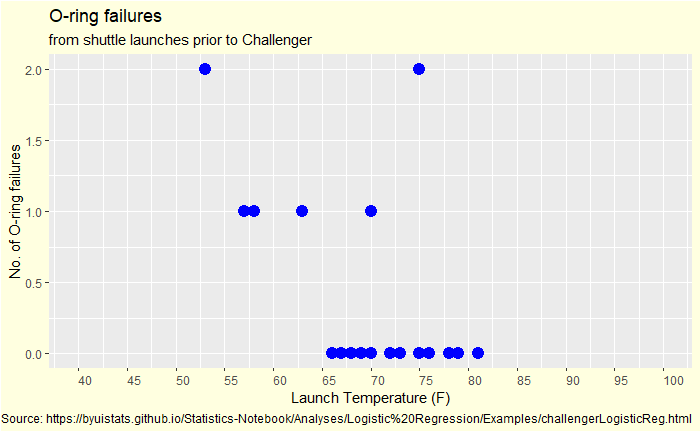
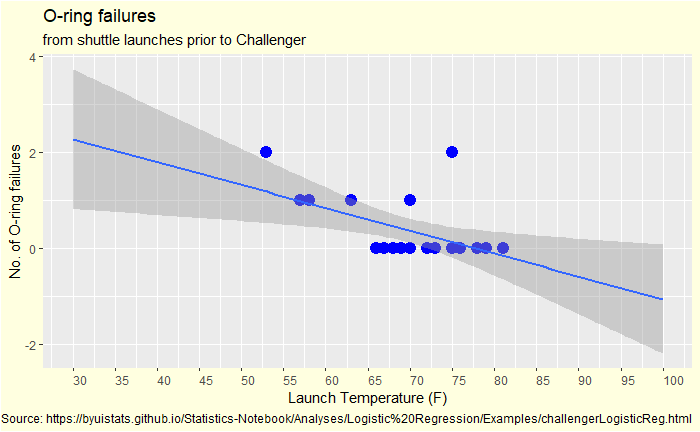
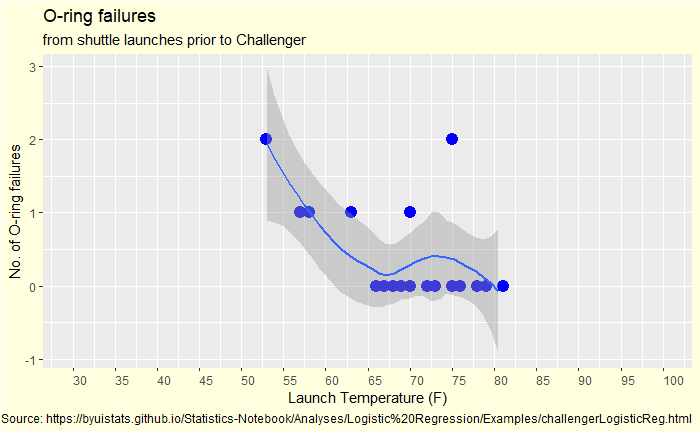
The Vos Savant Problem
In my opinion, the Monte Hall problem was not about probability. It was about prejudices.
The trouble with reasoning
Logical reasoning has enjoyed an upper hand over experimentation due to historical reasons. Reasoners and philosophers commanded respect in society from very early history. It was understandable, and science, the way we see it today, was in its infancy. Experimentation and computation techniques did not exist. But we continued that habit even when our ability to experiment – physical or computational – has improved exponentially.
I have recently read an article on the Monty Hall problem, and in the end, the author remarked that the topic was still in debate. I wonder who on earth is still wasting their time on something so easy to find experimentally or by performing simulations. Make a cutout, collect a few toys, call your child for help, do a few rounds and note down the outcome. There you are and the great philosophical debate.
Thought experiments are thoughts, not experiments!
Thought experiments, if you can do some, are decent starting points to frame actual experiments and not the end in itself. The trouble with logical reasoning as the primary mode of developing a concept is that it creates an unnecessary but inevitable divide between a minority who could understand and articulate the idea and a large group of others. Evidence that emerges from experiments, on the other hand, is far convincing to communicate to people. The debate then shifts to the validity and representativeness of the experimental conditions and the interpretation of results.
Monte Hall is relevant
The relevance of the Monty Hall problem is that it tells you the existing deep-rooted prejudices and sexism in society. The topic should be discussed but not as an example for budding logical reasoning or the eloquence of mathematical language. If someone doubts the results, which is very ‘logical’, the recommendation should be to conduct experiments or numerical simulations and collect data.
Philosophy, like psychology, has played its role in the grand arena of scientific splendour as the main protagonist. The time has come for them to take the grandpa roles and give the space for experimentation and computation.
The Vos Savant Problem Read More »