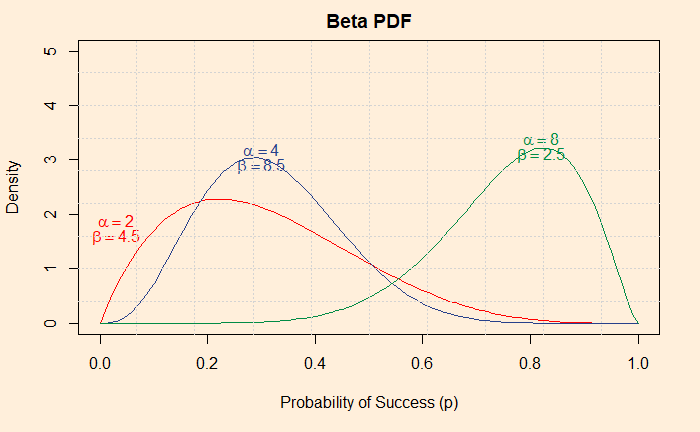
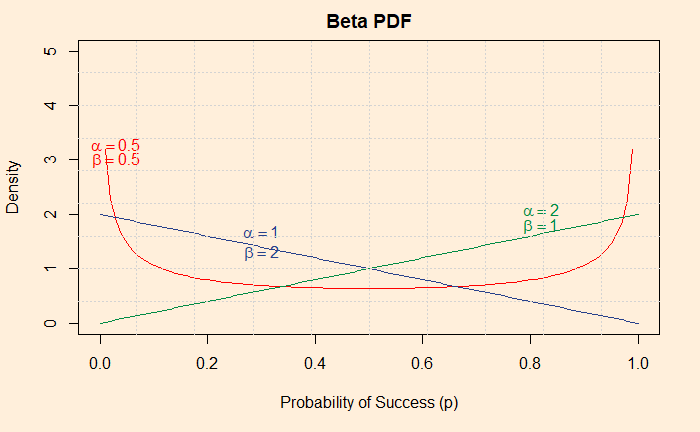
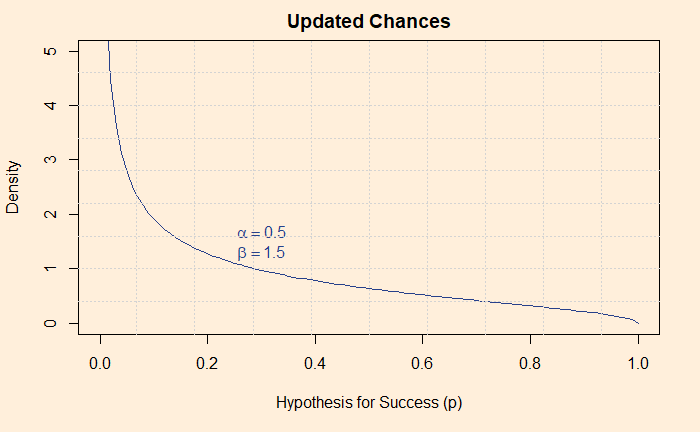
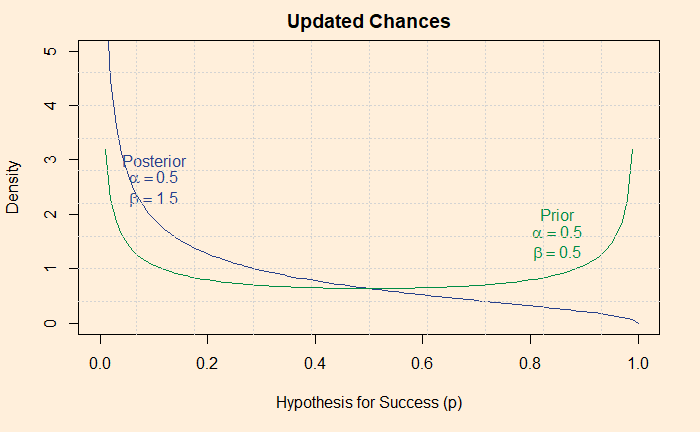
Expert’s Curse 1: Base Rate Fallacy
The first one on the list is the base rate fallacy or base rate neglect. We have seen it before, and it is easier to understand the concept with the help of Bayes’ theorem.
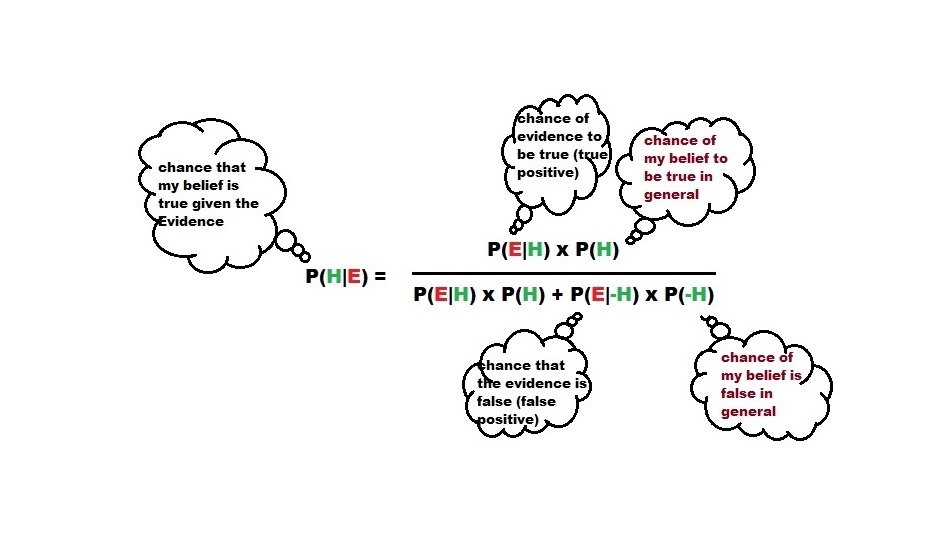
P(H) in the above equation, the prior probability of my hypothesis on the event is the base rate. For the case study of doctors in the previous post, the problem starts when the patient presents a set of symptoms. Take the example of the case of UTI from the questionnaire:
Mr. Williams, a 65-year-old man, comes to the office for follow up of his osteoarthritis. He has noted foul-smelling urine and no pain or difficulty with urination. A urine dipstick shows trace blood. He has no particular preference for testing and wants your advice.
eAppendix 1.: Morgan DJ, Pineles L, Owczarzak, et al. Accuracy of Practitioner Estimates of Probability of Diagnosis Before and After Testing. Published online April 5, 2021. JAMA Internal Medicine. doi:10.1001/jamainternmed.2021.0269
The median estimate from the practitioners suggested that they guessed a one-in-four probability of UTI (ranging from 10% to 60%). In reality, based on historical data, such symptoms lead to less than one in a hundred!
Was it only the base rate?
I want to argue that the medical professionals made more than one error, i.e., base rate neglect. As evident from the answer to the last question, it could be a combination of two possible suspects—anchoring and the prosecutor’s fallacy. First, let’s look at the questions and answers.
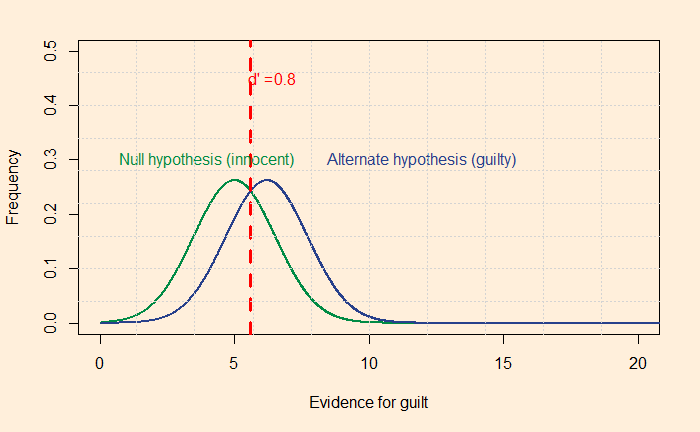
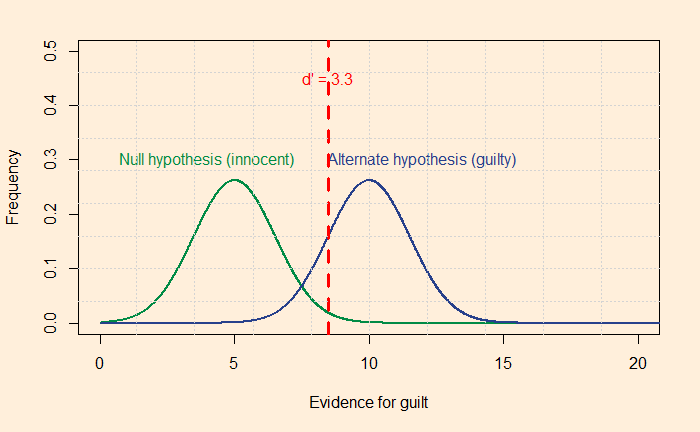
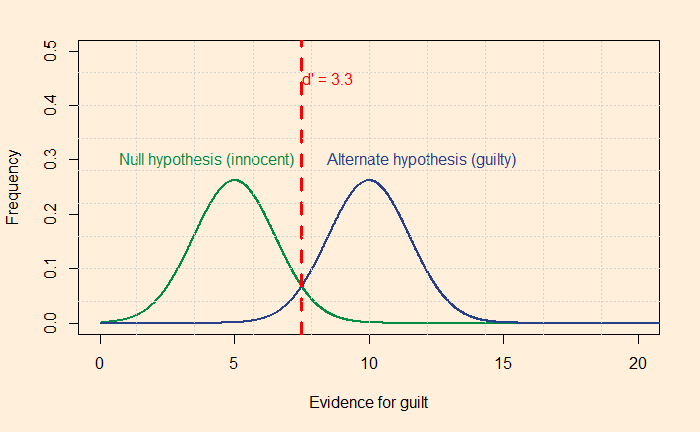
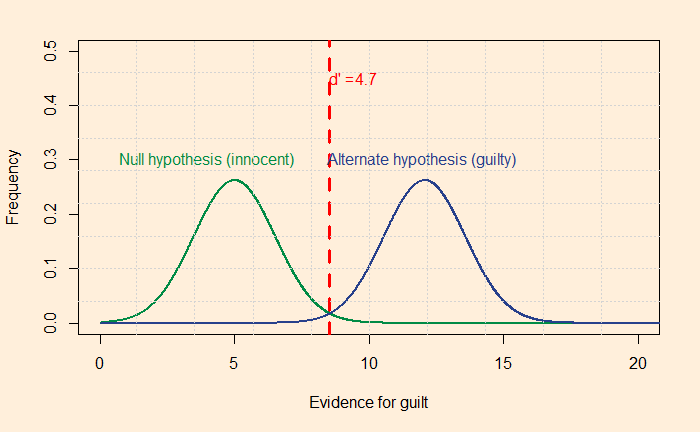
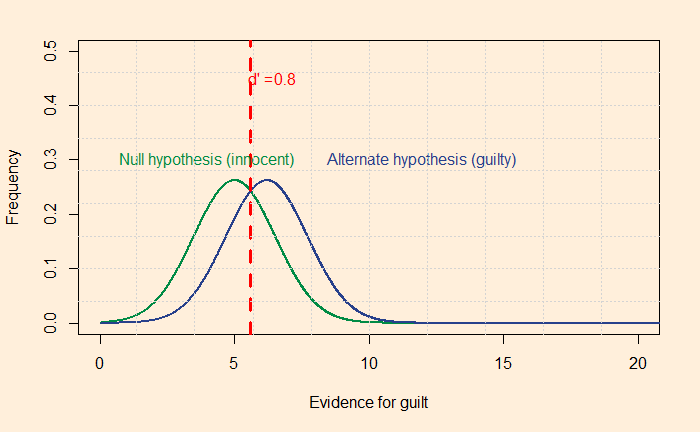
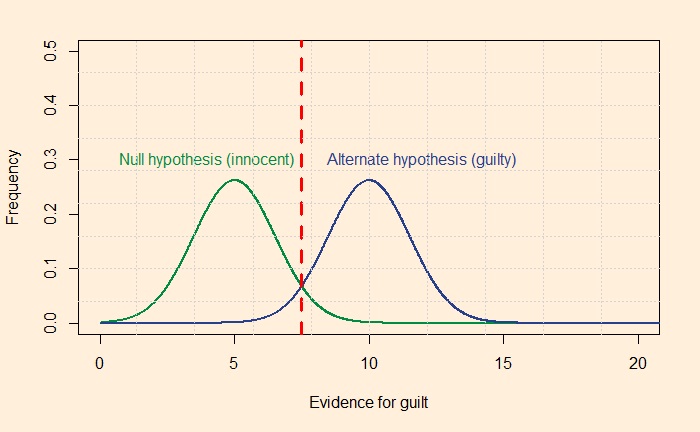
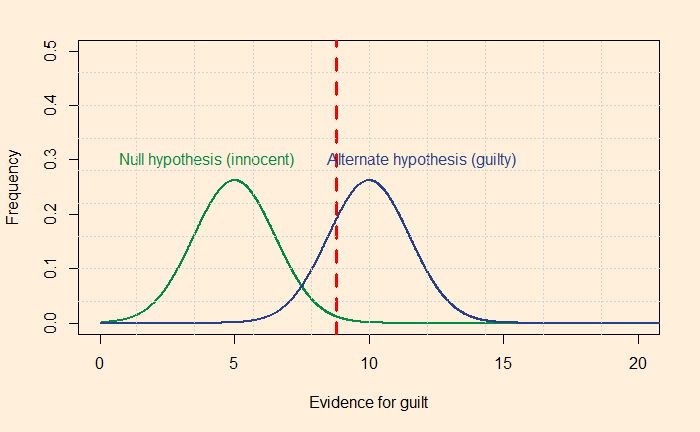
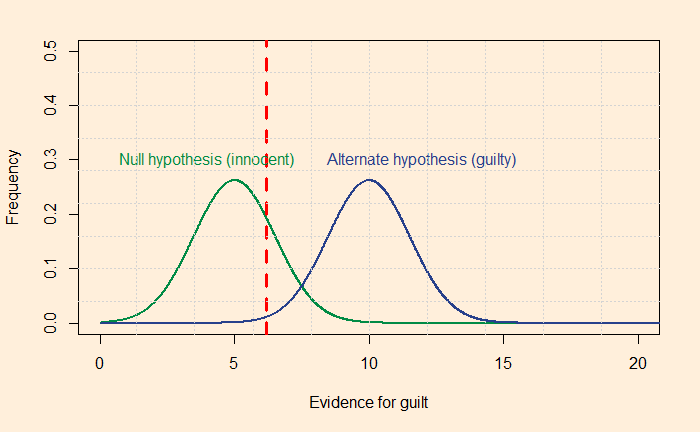
A test to detect a disease for which prevalence is 1 out of 1000 has a sensitivity of 100% and specificity of 95%.
The median survey response was 95% post-test probability (in reality, 2%!) for a positive and 2% (in reality, 0) for a negative.
The prosecutor’s fallacy arises from the confusion between P(H|E) and P(E|H). In the present context, P(E|H), also called the sensitivity, was 100%, but the answers got anchored to 95% representing specificity. To understand what I just meant, look at the Bayes’ rule in a different form:

So it is not a classical prosecutor’s case but more like getting hooked to 95%, irrespective of what it meant—it is more of a case of anchoring.
Expert’s Curse 1: Base Rate Fallacy Read More »