Gambler’s Trouble Continues
We will continue the gambler’s trouble; through probability and binomial trials. The probability of making exactly one dollar after playing three even-money bets (payoff 1 to 1) of an American Roulette is given by the following binomial relationship:
nCs x ps x q(n-s) = 3C2 x (18/38)2 x (20/38)(3-2)
What we did here was to calculate the chance of winning two games and losing one (out of three) to win one dollar. But that is not a reasonable estimate. What is more realistic is to estimate the probability of winning at least one dollar in three games.
3C2 x (18/38)2 x (20/38)(3-2) + 3C3 x (18/38)3 x (20/38)(3-3)
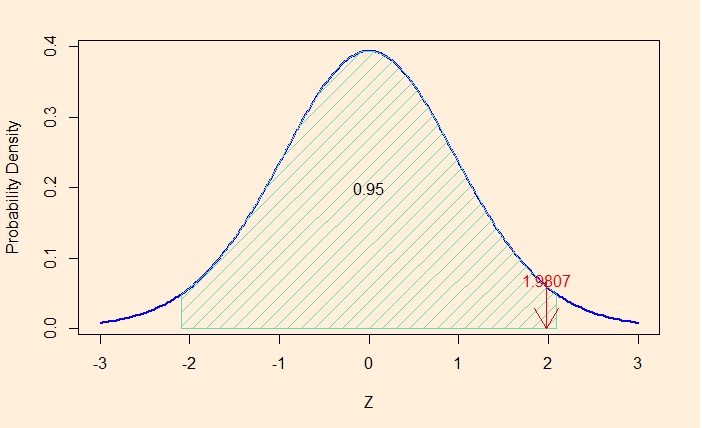
Another way of estimating the same is to use the cumulative density function (CDF). In R, we know how to estimate it.
sim_p = 18/38
1 - pbinom(1, 3, prob = sim_p)pbinom function calculates the total probability starting from the smallest value of zero winning. pbinom(1, 3) is the cumulative probability density of up to win, i.e., chance of zero wins out of three + one win out of three. But what we require is: at least two wins, which is (1 minus up to 1 win). By the way, it is 0.46 (46%).
In the same way, what is the probability of making at least one dollar profit if you bet 100 games at one dollar each?
sim_p = 18/38
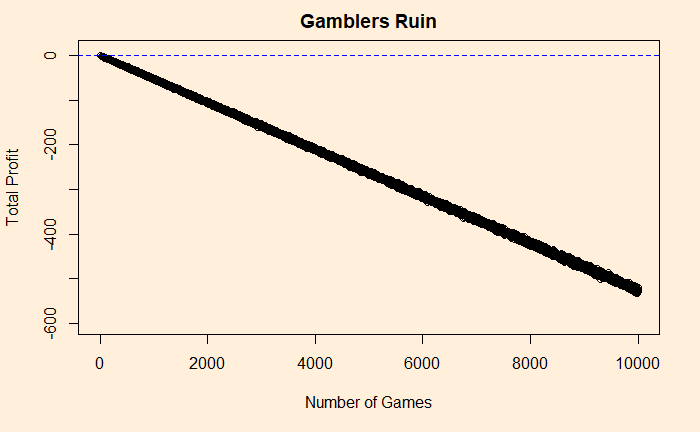
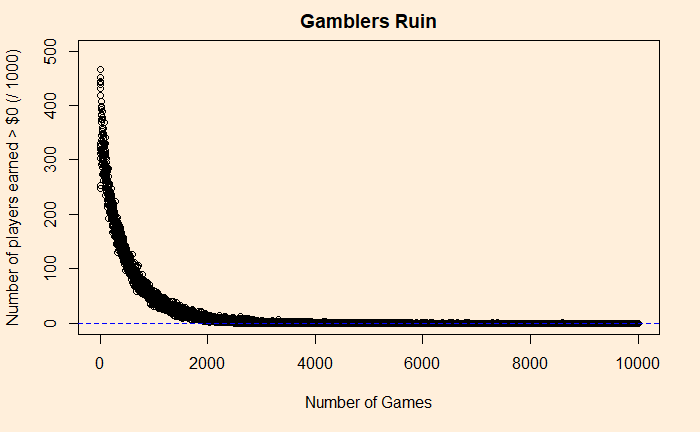
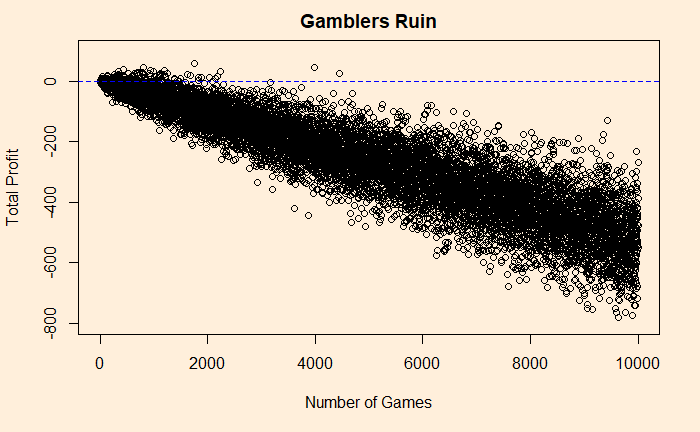
1 - pbinom(50, 100, prob = sim_p)The answer is about 27%. If you go for 1000 games, the probability falls to 4.5%. Play for 10000, and you will never win a dollar (p = 0.00000006567867)
Gambler’s Trouble Continues Read More »