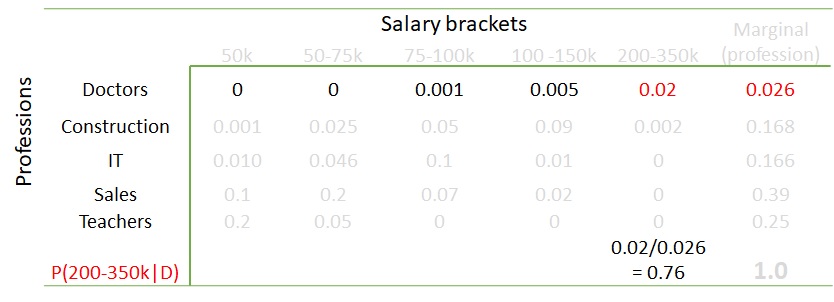
Infinite Prisoner’s Dilemma
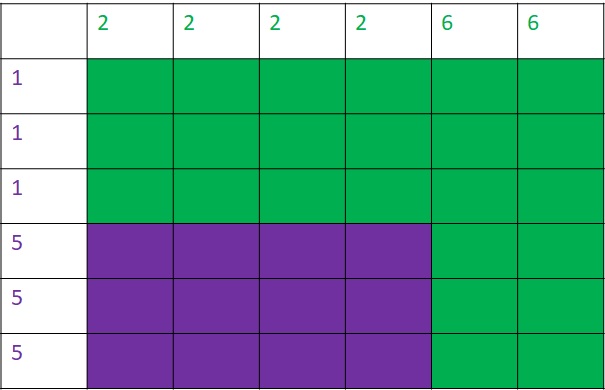
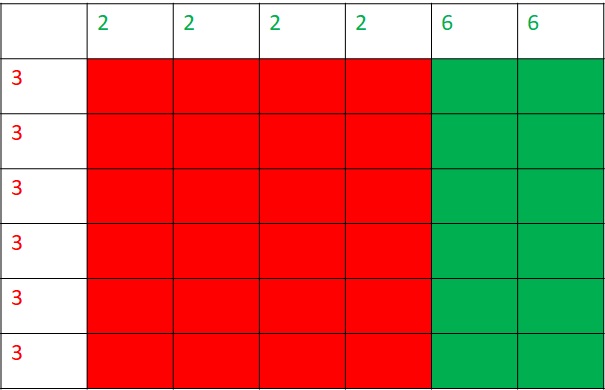
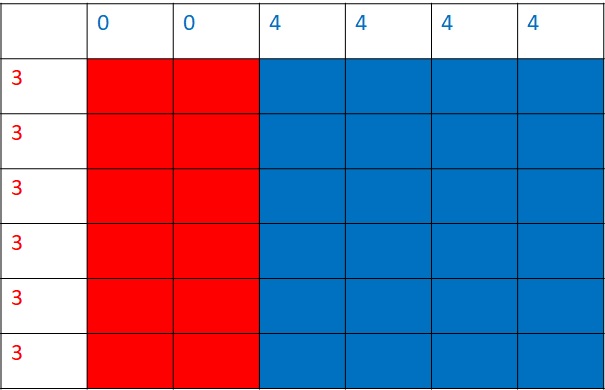
You know what a prisoner’s dilemma is. Here, each prisoner optimises the incentive (minimises the downside) by betraying the other. And the payoffs matrix is,
| B Cooperates | B Defects | |
| A Cooperates | (3,3) | (0,5) |
| A defects | (5,0) | (1,1) |
But what happens when the choices are repeated? Then it becomes an infinite prisoner’s dilemma.
Infinite game
Unlike the once-off, the player in the infinite game must think in terms of the impact of her decision in round one on the action of the other in round two etc. The new situation, therefore, fosters the language of cooperation.
Cooperation
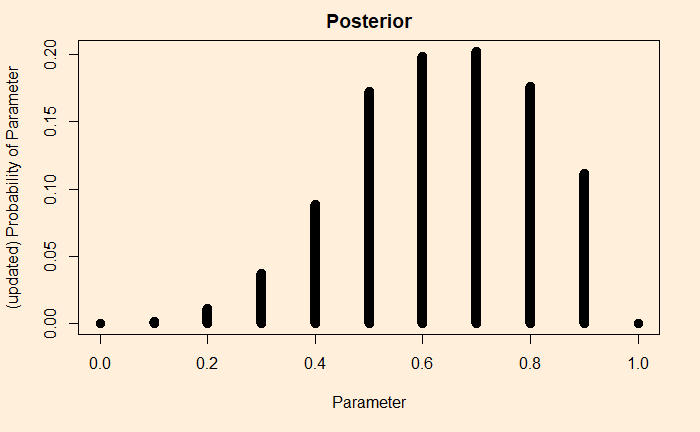
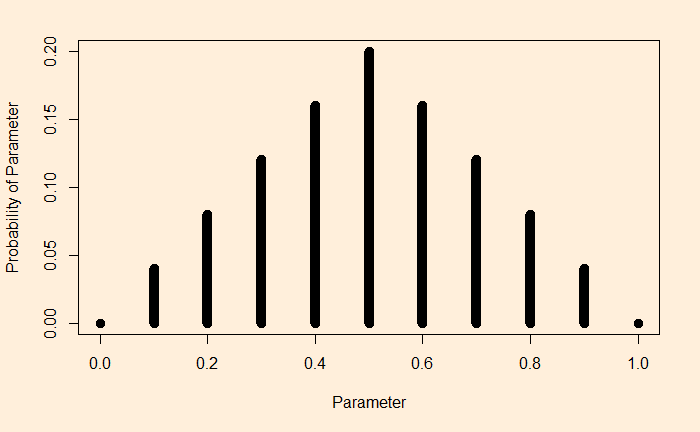
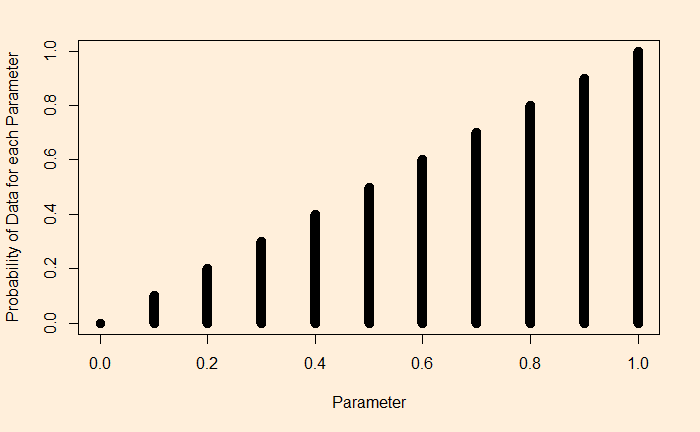
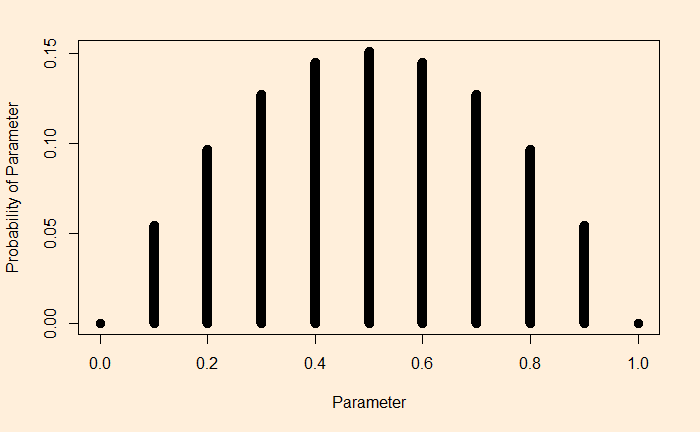
The question is: how many games do the players need to realise the need for cooperation?
Concept of discounting
Let’s start the game. In the found round, as rational players, players A and B will play defect, leading to a mediocre, but still better than the worst possible, outcome.
Infinite Prisoner’s Dilemma Read More »