En-ROADS to Afforestation
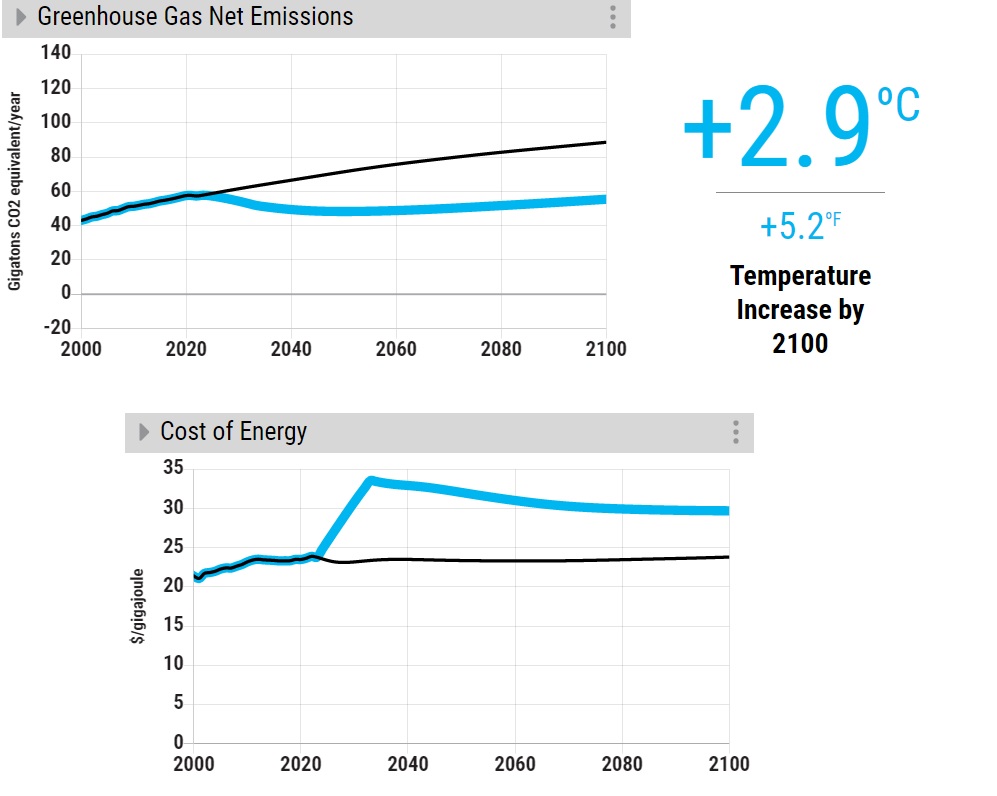
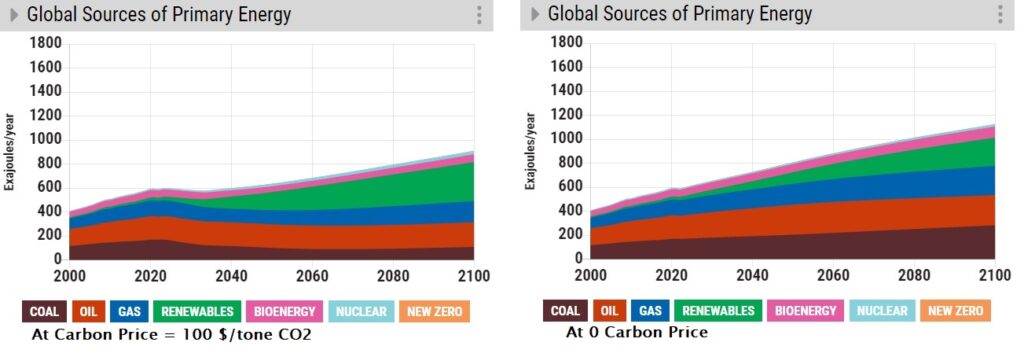
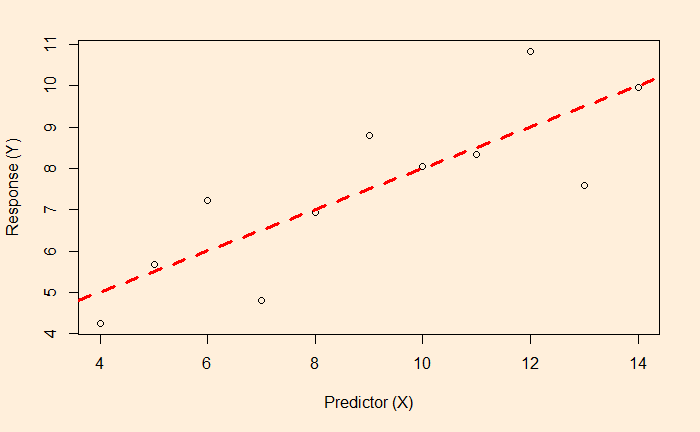
Let’s run another popular choice for CO2 removal – aforestation or planting trees. In this scenario,100% of the available land is used for afforestation.
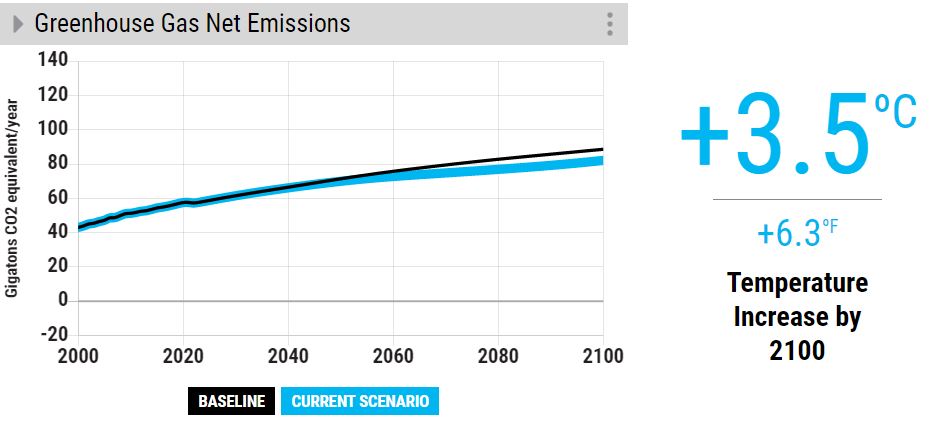
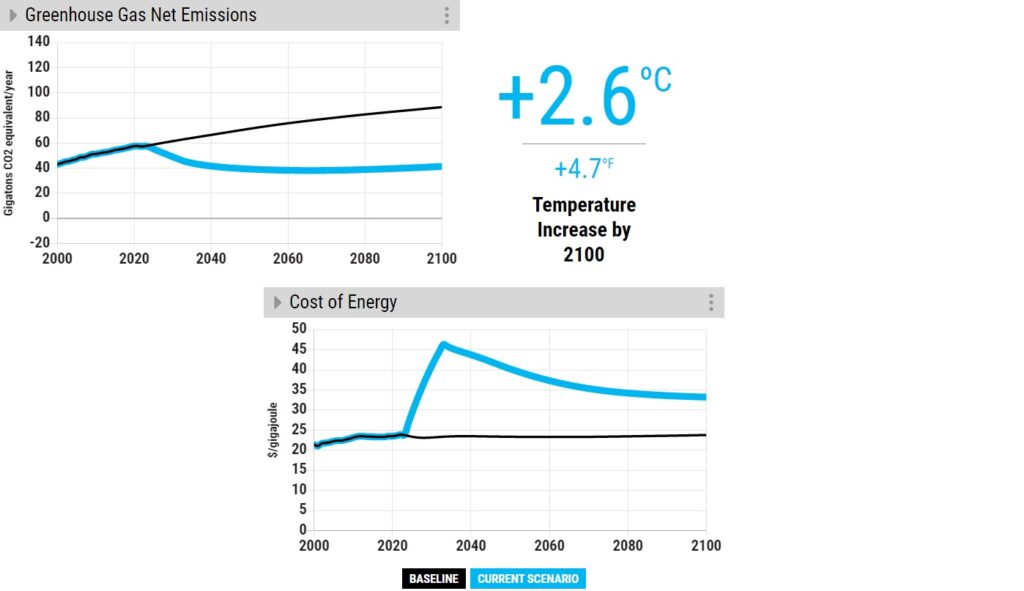
Now, compare that with a highly reduced rate of deforestation.

The outcome is the same – a very marginal reduction of temperature rise.
It takes time for trees to grow
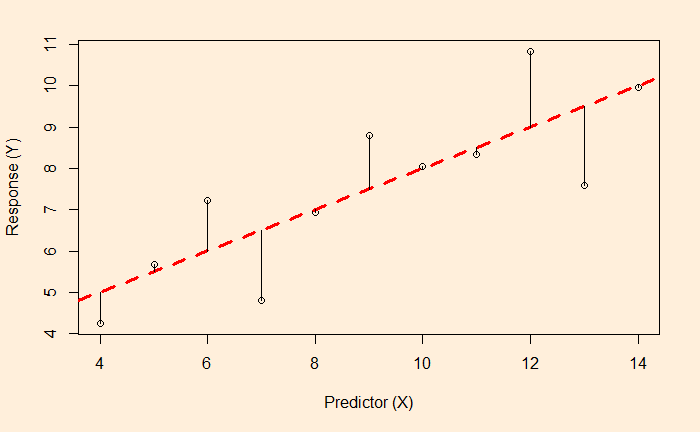
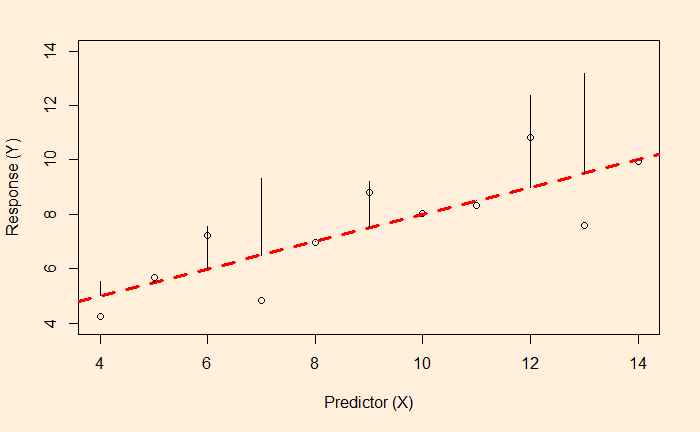
The key reason for the aforestation failure is the time it takes for the trees to grow. The time till 2100 is less than 80 years, and an 80-year-old tree is still young!
References
The Paris Agreement: UNFCCC
EN-ROADS: Climate Interactive
En-ROADS to Afforestation Read More »