Predicted R-Squared
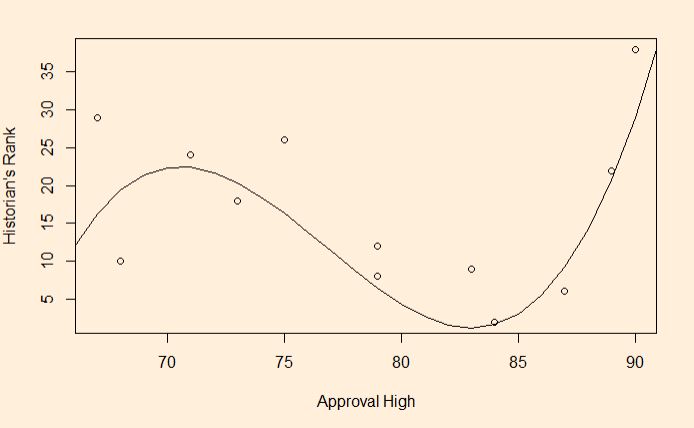
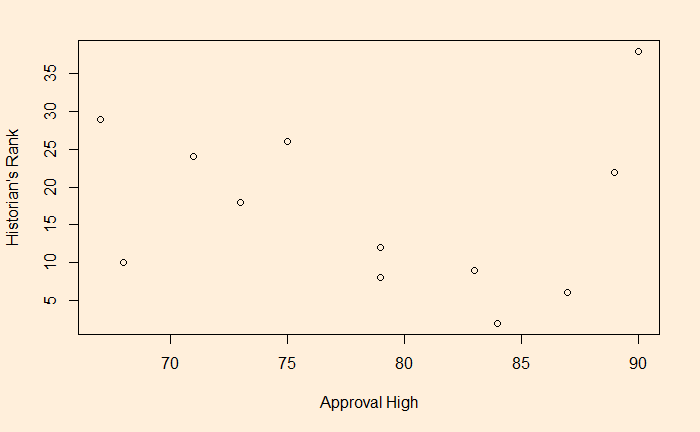
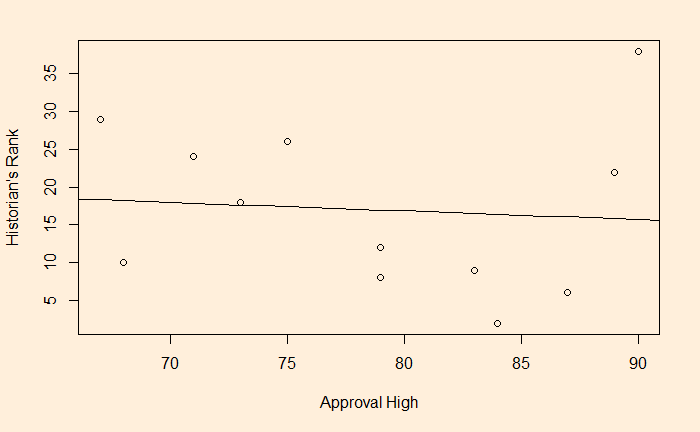
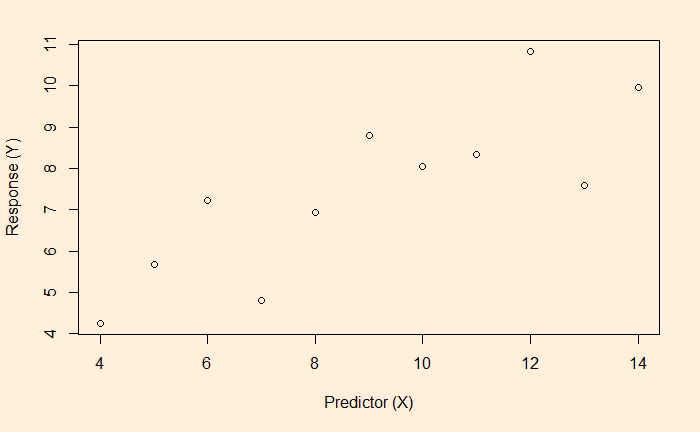
The foundation of predictive R-squared is cross-validation. We will examine the LOOCV method in this post. First, the data set that we used in the past exercises.
| Approval High | Historians Rank |
| 2 | 84 |
| 6 | 87 |
| 8 | 79 |
| 9 | 83 |
| 12 | 79 |
| 29 | 67 |
| 24 | 71 |
| 26 | 75 |
| 10 | 68 |
| 22 | 89 |
| 18 | 73 |
| 38 | 90 |
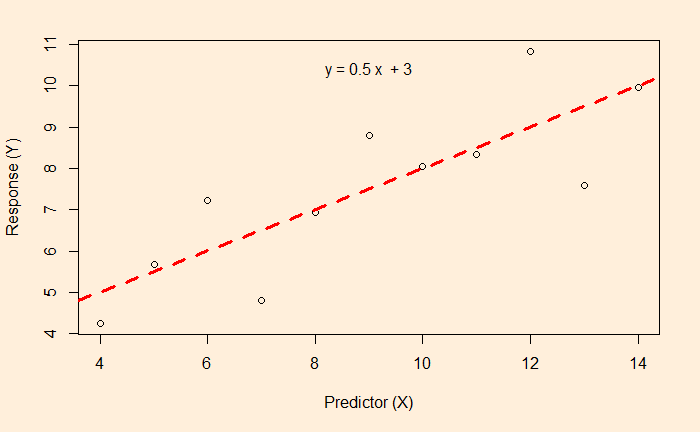
Then,
- The first row is removed from the list, and the regression model is developed with the other 11 data (2:12)
- The model is used to predict observation 1 (y). By plugging in the x value (e.g. 2) in the formula (cubic form)
- The predicted y is subtracted from the actual y for observation 1 and squared (called the squared residual)
- Observation 1 is returned to the list, and observation 2 is removed (1, 3:12)
- The process is continued until the last observation and squared residual are collected
- Sum all the squared residual to get what is known as PRESS (predicted residual error sum of squares)
- Predicted R2 = 1 – (PRESS/TSS)
res_sq <- 0
for (i in 1:12) {
new_presi <- Presi_Data[-i,]
model1 <- lm(new_presi$Historians.rank ~ new_presi$Approval.High + I(new_presi$Approval.High^2) + I(new_presi$Approval.High^3))
res <- Presi_Data[i,1] - (model1$coefficients[1] + model1$coefficients[2]*Presi_Data[i,2]+model1$coefficients[3]*Presi_Data[i,2]^2 +model1$coefficients[4]*Presi_Data[i,2]^3)
res_sq <- res_sq + res^2
}
res_sqThe res_sq is PRESS.
TSS (or SST) is the total sum of squares = sum of (response (y) – mean of response)2
sum((Presi_Data$Historians.rank-mean(Presi_Data$Historians.rank))^2)predict_r_sq <- 1 - (res_sq/sum((Presi_Data$Historians.rank-mean(Presi_Data$Historians.rank))^2))Predicted R-Squared Read More »