In prospect theory, we have seen how human psychology slips into irrationality while understanding risks. The fourfold pattern is one such representation; of behaviours that deal with extreme probability events.
Imagine the following four cases of improving the chances of making one mln dollars. A. 0% to 5% B. 5% to 10% C. 50 to 55% D. 95 to 100%
A robot will perform the following calculations and conclude
A. (0.05 x 1,000,000 + 0.95 x 0) – 0 = $50,000 B. (0.1 x 1,000,000 + 0.90 x 0) – (0.05 x 1,000,000 + 0.95 x 0) = $50,000 C. (0.55 x 1,000,000 + 0.45 x 0) – (0.5 x 1,000,000 + 0.5 x 0) = $50,000 D. (1.0 x 1,000,000 + 0.0 x 0) – (0.95 x 1,000,000 + 0.05 x 0) = $50,000
that, all those situations lead to the same outcome – the robot has just performed an expected value calculation! But humans are not robots, and not all increment (wins or losses) has the same value.
A change from 0% to 5% is a movement from impossibility to a ray of hope. And that triggers the brain disproportionally. In other words, we overestimate that 5%. A classic example is a lottery ticket. How many of us would buy a ticket that expired a month ago? In reality, the chance of winning a lottery is almost the same as that of an expired one! This behaviour is called ‘risk-seeking‘.
On the other hand, progress from 95% to 100% is a change from possibility to certainty. An example is an out-of-court settlement. Assume you have a 95% chance of winning a lawsuit at $1 mln. Your lawyer indicated a 5% chance of losing the case and conveyed the other party’s willingness for a settlement of %750,000. Will you take it? This is ‘risk aversion‘ or underestimation of probability.
This one is picked from the Internet and attributed to a University of Maryland professor. The students have the opportunity to get extra marks. They can select 6 or 2 points, but with conditions: if more than 10% of the students choose 6, no one gets anything. What will be your choice?
Others pick 6 points
Your Pick
> 10%
< 10%
2 Points
0
2
6 points
0
6
So, in either case, you are better off or at least as good off by picking 6.
Imagine there is a lottery where you pick five numbers from an urn containing 100 numbers, 1 to 100. You win the draw if you select numbers in increasing or decreasing order. For example, [23, 34, 65, 80, 94] and [69, 54, 30, 18, 9] are winning sequences, but the string [12, 43, 32, 52, 94] is not. What is the probability of winning the lottery?
Analytical solution
Suppose you pick five numbers at random from the basket of 100. The number of ways you can arrange those five is 5! = 120. Out of those, one sequence will be in the increasing order and one in the decreasing. So the chance of getting your winning lot is (1/120) + (1/120) = 2/120 = 1.67%
You get an answer similar to the one before. Note that the function ‘all’ will return TRUE if all values match the criterion given a set of logical vectors. The function ‘diff’ calculates the difference between the elements ([element 2 – element 1], [element 3 – element 2] etc.) of a vector. For example,
Let’s visit our favourite subject, but after a long gap – the probability and Bayes’ theorem. Here is the question:
A new child arrives in a child-care facility that has three boys and the remaining girls. A statistician visits the centre and randomly picks up a boy child. What is the chance that the newly admitted child is a boy?
Before solving the puzzle, let the number of girls already in the centre be g. Therefore, the total number of children available for the statistician to count is 3 + 1 + g = 4 + g.
The Bayes’ equation is
The terms are P(B_n | B_r) = probability of the new child being a boy given the randomly picked is a boy P(B_r | B_n) = probability of picking a random boy given the new child is a boy = 4 /(4+g) P(B_r | G_n) = probability of picking a random boy given the new child is a girl = 3/ (4+g) P(B_n) = prior probability for the new child to be a boy = 0.5 P(G_n) = prior probability for the new child to be a girl = 0.5
I want to end the football penalty series with this one. We start with a finer data resolution and evaluate the statistical significance zone-wise. The insights from such objective analyses can tell you about statistical significance and how we can get misled easily.
Aiming high doesn’t solve
We have seen in the last post that the three chosen areas of the goal post – the top, middle and bottom – were not statistically differentiable. The following column summarises the results. Focus on whether or not the average success rate (0.69) falls within the confidence interval (for 90%) provided for each. Seeing the average inside the bracket means the observation is not significantly different.
Area
Success (total)
p-value
90% Confidence Interval
0.69 IN/OUT
Top
46 (63)
0.5889
[0.63, 0.81]
IN
Middle
63 (87)
0.6082
[0.64, 0.80]
IN
Bottom
86 (129)
0.4245
[0.60, 0.73]
IN
Overall
195 (279)
As you can see, none of the observations is out of the expected.
Zooming into zones
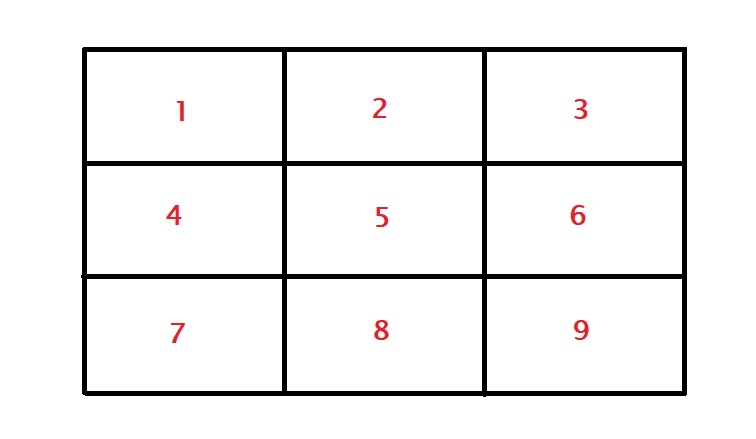
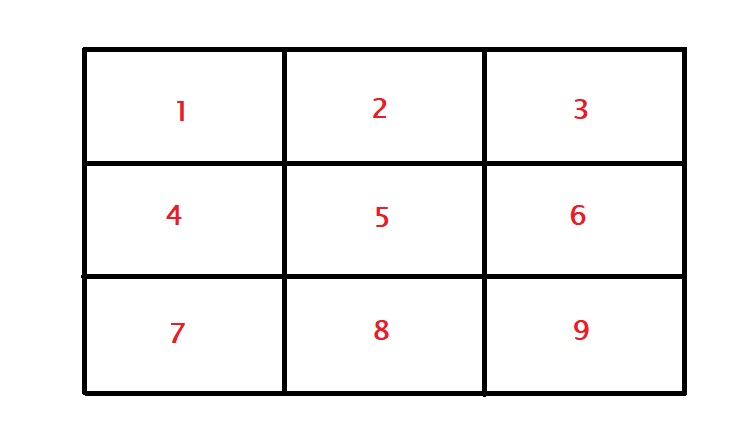
As the final exercise, we will check if a particular spot offers anything significant towards the goal. In case you forgot, here are the nine zones mapped between the goalpost. Note that these are from the viewpoint of the striker.
The data is in the following table.
Zone
Total
Success
Success (%)
zone 1
28
21
0.75
zone 2
19
11
0.58
zone 3
16
14
0.88
zone 4
36
27
0.75
zone 5
18
11
0.61
zone 6
33
25
0.76
zone 7
63
40
0.64
zone 8
20
12
0.6
zone 9
46
34
0.74
A quick eyeballing may appear to tell you something about zone 3 (top right for the striker or top left of the goalkeeper) or zone 2. Let’s run hypothesis testing on each, starting from zone 1.
prop.test(x = 21, n = 28, p = 0.6989247, correct = FALSE, conf.level = 0.9)
Zone
90% Confidence Interval
p-value
zone 1
[0.60, 0.86]
0.56
zone 2
[0.40, 0.74]
0.25
zone 3
[0.68, 0.96]
0.13
zone 4
[0.62, 0.85]
0.70
zone 5
[0.42, 0.77]
0.42
zone 6
[0.62, 0.86]
0.46
zone 7
[0.53, 0.73]
0.27
zone 8
[0.42, 0.76]
0.34
zone 9
[0.62, 0.83]
0.55
Fooled by smaller samples
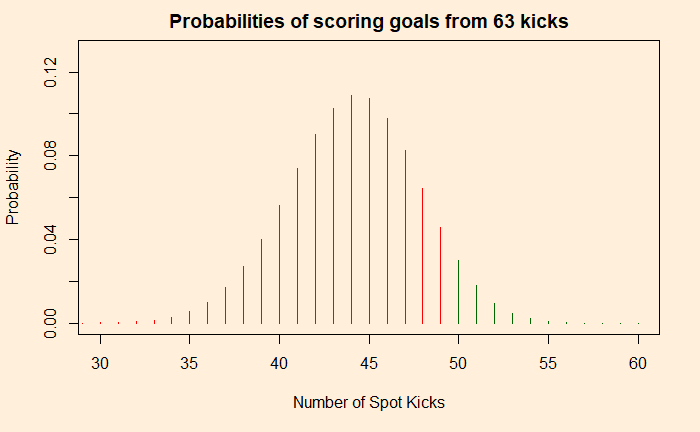
Particularly baffling is the result on the zone there, where 14 out of 16 have gone inside, yet not significant enough to be outstanding. It shows the importance of the number of data points available. Let me illustrate this by comparing the same proportion of goals but with double the number of samples (28 from 32).
prop.test(x = 14, n = 16, p = 0.6989247, correct = FALSE, conf.level = 0.90)
prop.test(x = 14*2, n = 16*2, p = 0.6989247, correct = FALSE, conf.level = 0.90)
1-sample proportions test without continuity correction
data: 14 out of 16, null probability 0.6989247
X-squared = 2.3573, df = 1, p-value = 0.1247
alternative hypothesis: true p is not equal to 0.6989247
90 percent confidence interval:
0.6837869 0.9577341
sample estimates:
p
0.875
1-sample proportions test without continuity correction
data: 14 * 2 out of 16 * 2, null probability 0.6989247
X-squared = 4.7146, df = 1, p-value = 0.02991
alternative hypothesis: true p is not equal to 0.6989247
90 percent confidence interval:
0.7489096 0.9426226
sample estimates:
p
0.875
85% success rate for a total sample of 32 is significant. The outcome occurred as the chi-squared statistic grew from 2.3 to 4.7 when the sample sizes increased from 16 to 32. If you recall, the magic number for a 90% confidence interval (and degree of freedom of 1) is 2.7, above which the statistics become significant. It is also intuitive because you know that more data increases the certainty of outcomes (reduced noise). So collect more data and then conclude.
NOTE: chi-squared test may not be ideal for the 14/16 case due to smaller samples. In such cases, suggest running binomial tests (binom.test())
Let’s recap the penalty data that we discussed last time.
Attempt
Success
goal %
Total
279
195
69.9%
Top section
63
46
73.0%
Middle section
87
63
72.4%
Bottom section
129
86
66.7%
Is top really on top?
We start with the null hypothesis, H0: H0 = Success rate at the section of the post is no different from the average rate of 0.699
There are many ways to test this hypothesis. The simplest way is to use the ‘prop.test’ in R. Note that we use a 90% confidence interval, which gives a better chance to disprove the premise.
prop.test(x = sum(top_suc), n = sum(top_suc) + sum(top_fai), p = 0.6989247, correct = FALSE, conf.level = 0.9)
1-sample proportions test without continuity correction
data: sum(top_suc) out of sum(top_suc) + sum(top_fai), null probability 0.6989247
X-squared = 0.29207, df = 1, p-value = 0.5889
alternative hypothesis: true p is not equal to 0.6989247
90 percent confidence interval:
0.6301125 0.8112506
sample estimates:
p
0.7301587
The p-value of 0.5889 suggests the hypothesis stays; there is no evidence to suggest that the top brings any advantage! The global average success rate (0.699) is well within the 90% confidence interval [0.63,0.81] of 46 in 63.
Penalty as a binomial trial
Another way to understand this problem is to consider penalty kicks as a binomial trial (with the probability of success = 0.699). If you kick 63 balls to the top section of the post, the expected number of goals, under the assumption of no special advantage, is between 38 and 50.
Another world championship for football is coming to a close, as the final match is scheduled for tomorrow. Getting a penalty kick, either inside the game or at a tie-breaker stage, is considered a sure-short chance to make the all-important goal for the team. Today we look at how teams have managed spot kicks (a.k.a. penalty kicks) in the world cup (from Spain in 1982 to Russia in 2018).
The data is collected from kaggle.com (WorldCupShootouts.csv). We use R to perform the step-by-step analysis. First, the data:
A tibble:279 x 9
Team Zone Foot Keeper OnTarget Goal
BRA 7 R L 0 0
FRA 7 R R 1 1
GER 1 L R 1 1
MEX 6 L L 1 1
GER 8 L L 1 1
MEX 8 R L 1 0
GER 7 R L 1 1
MEX 7 R L 1 0
GER 4 R L 1 1
SPA 7 R R 1 1
...
21-30 of 279 rows
The first meaningful data in the table is the column Zone, which represents which part of the goalpost (from the viewpoint of the player who takes the kick). The figure below shows all the zones. For example, zone 7 represents the bottom right side of the goalkeeper, 3 is the top left side of the goalkeeper etc.
The two other variables we will use in this analysis are – Ontarget: 1 = on target, 0 = off target, goal: 1 = goal, 0 = no goal.
The probability of scoring a penalty
There are many ways to calculate that – add a filter to the column, goal, = 1, and divide the term by the total number of attempts. We use something simple – the which function.
we have a 0.73 (73%) probability of scoring a goal. Run the code for the middle and bottom, and you get 72% and 67%, respectively. We will look at the significance of these differences at another time.
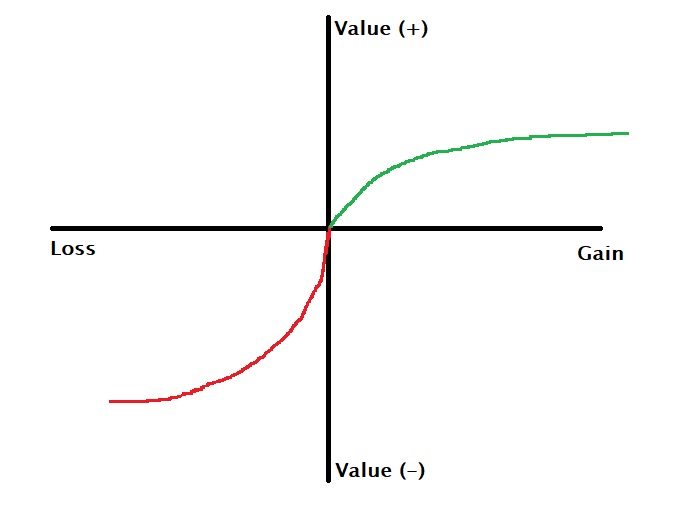
Prospect theory is a behavioural model which explains how people make decisions that involve risk. It has been observed that people take gains and losses differently. In short, to the decision maker, the pain of losing something scores higher over the pleasure of gaining – the risk aversion.
The plot below illustrates the prospect theory. While both the positive side (green part) and the negative side (red part) reflect diminishing marginal utility (flattening towards the higher x values), the initial few gains and losses have distinct shapes. Imagine the feeling you have when you get 100 dollars; compare that with gaining an additional hundred dollars, say from 2000 to 2100.
The fundamental question here is: what defines the origin of the plot? One possibility is that it represents the present state. I can also argue it marks the expectations. An example of the latter is the famous case of silver medal winners. Studies seem to indicate that the second-place winners of sports events were unhappier than the third-place holders, especially when it is contrary to prior expectations.
Daniel Kahneman and Amos Tversky; Econometrica, 47(2), 1979, 263-291 McGraw et al.; Journal of Experimental Social Psychology 41, 2005, 438–446
Now that the top contenders of the double Poisson projection – Belgium and Brazil – are back home, even before the semi-final stage, it is time to reflect on what may have gone with the predictions.
Reason 1: Nothing wrong
Nothing went wrong. The problem is with the understanding of the concept of probability. Having a chance of 14% may mean, in a frequentist’s interpretation, that if we play 100 world cups today, there could be about 14 times the Belgium team win. It also means around 86 times they don’t!
Reason 2: Insufficient data
Insufficient data for the base model could be the second issue. As per the reference, the foundations of the model are based on two parameters, viz., attacking strength and defensive vulnerability. In a match between A and B, the former could be the historical average number of goals that team A had scored divided by the number of goals scored in the tournament. The latter could be the number of goals that team A has conceded.
Here is the first catch: if it was a national league of clubs or a regional (e.g. European) league of countries, getting a decent number of data between A and B is possible. In the present case, Belgium lost the chance because of the loss suffered by Morocco. Not sure how many serious matches these two countries played in recent years. In the absence of that data, the next best alternative is to calculate the same by team A against a team of comparable strength.
Reason 3: Time has changed
Especially true for Belgium, whose golden generation has been on the decline since the last world cup (2018). The analysis may have used data from the past, where they were really good, leading to the present, where they are just fine!
Reason 4: World cup’s no friendly
It again goes back to the quality of data. Regular (qualifying or friendly) matches can’t compare to a world cup match. Many of the strong contenders get back their final group of key players (from the clubs) only as the finals get closer. So, using the vast amount of data from less serious matches and applying them in serious world cup matches reduces the forecasting power.
Reference
How big data is transforming football: Nature Double Poisson model for predicting football results: Plos One
The 2011 study by Mursu et al. is an excellent example of how confounding variables can mask actual results. It was an observational study conducted by assessing 38772 older women from Iowa.
The study was based on self-administered questionnaires, and the women were between 55-69 years of age. And it ran from 1986 until 2008, with reporting happening in 86, 97 and 2004. The queries included data from 15 supplements, including vitamins, iron, calcium, copper, iron, magnesium, selenium and zinc.
The researchers have used three statistical models. In the first model, they considered raw data with minimum adjustment (only age and energy intake). More parameters were added, such as education, place of residence, diabetes, blood pressure, BMI, physical activity, and smoking, in the second model. The final one has, in addition to the others, alcohol, vegetable, and fruit intake.
The minimally adjusted model showed a lower mortality risk with vitamin B-complex, vitamins C, D, and E, and calcium. One could observe several confounding variables that differentiated supplement takers from non-takers. The supplement users, on average, were non-smokers, had a lower intake of energy, were more educated, were more physically active, and had lower BMI and waist-to-hip ratio.
The refinements, model 2, showed only calcium had some beneficial effect on lowering mortality, whereas the other supplements had minimal impact. Further adjustment of non-nutritional factors turned things further: multivitamins, B6, folic acid, copper, iron, magnesium, and zinc contributed to an increase in mortality rate compared to the non-takers of supplements.
Marsu et al.; Arch Intern Med., 2011, 171(18): 1625–1633