The Sheriff’s Dilemma is an example of a simultaneous move Bayesian game. In a standard game, the Nash equilibrium is formed by a player’s understanding of the other player. Whereas in Bayesian, the type (of the other) also matters. We will see that through an example. But before that, the rules.
Civilian vs criminal
The sheriff encounters an armed suspect, and they must decide whether to shoot at the other.
The suspect could be a criminal with probability p and civilian with (1-p).
The sheriff shoots if the suspect shoots
The criminal always shoots
The payoffs are
civilian (1-p)
sheriff
Shoot
Not
suspect
Shoot
-3,-1
-1,-2
Not
-2,-1
0,0
criminal (p)
sheriff
Shoot
Not
suspect
Shoot
0,0
2,-2
Not
-2,-1
-1,1
Before moving to the sheriff, let’s find out the strategy of the suspect. If the suspect is a civilian, his dominant strategy is not to shoot (-2 > -3 AND 0 > -1). For the criminal, the dominant strategy is to shoot (0 > -2 AND 2 > -1).
The sheriff’s payoff
The expected payoffs if the sheriff shoots is = -1 x (1-p) + 0 x p = p – 1 The expected payoffs if the sheriff doesn’t shoot is = 0 x (1-p) -2 x p = -2p
So, the payoffs match for p = 1/3. If p is greater than 1/3, the sheriff is better off if he shoots.
Look at the above graphic. There are two lines terminated with either arrowheads or arrow tails. While the length of the lines in both cases is the same, the illusion created by the form of the terminals makes our brain believe that the one on the bottom is longer. This is the Muller-Lyer illusion.
The wisdom of the crowd is an idea that stems from the fact that the average estimation by a group of people is better than by individual experts. In other words, when a large group of non-experts (not biased by knowledge!) possessing diverse opinions starts predicting a quantity, their assessment tends to form a kind of bell curve – a large pack in the middle and outliers nicely distributed on either side.
In other words, the outlier of the crowd has a lower probability of estimating it accurately. Mark this line; we need it later.
Estimating the weight
Let’s go back to Francis Galton (1907) and the story of the prize-winning-ox. It was a competition in which a crowd of about 800 people participated to predict the weight of an ox after it had been slaughtered and dressed. The person whose prediction came closer would win the prize. On the event in which Galton participated, he found a nearly normal distribution of ‘votes’, and the middlemost value, the popular choice or the vox populi, was 1207 lb which was not far from the actual dressed weight of 1198 lb.
Bidding for the meat
Now, change the scenario: the winner is no longer the predictor of weight but who will pay the most. Therefore, by definition, the people in the middle of the pack, those with a better estimation of the actual value of the meat (estimated weight x market price), are not going to get the prize. The bid belongs to the person furthest outlier (to the right) of the distribution. This is the winner’s curse – the winner is the one who overvalues the object. The only time it doesn’t apply is if the winner attaches a personal value to it, such as collecting a painting.
It is interesting to see how posterior distributions are a compromise between prior knowledge and the likelihood. An extreme, funny case is a coin that is thought to be bimodal, say at 0.25 and 0.75. But when data was collected, it gave almost equal heads and tails.
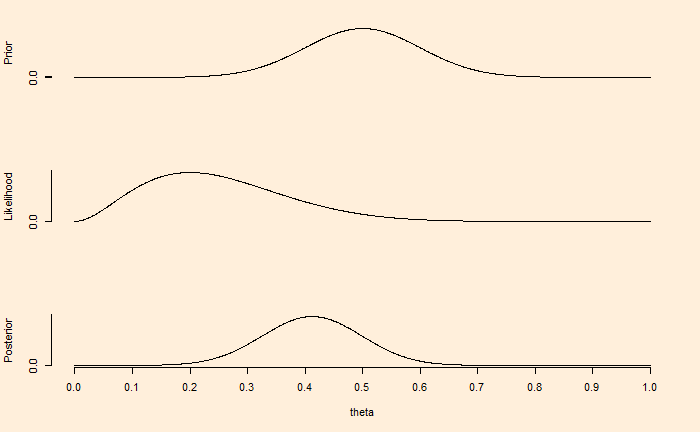
Last time, we have seen how the choice of prior impacts the Bayesian inference (the updating of knowledge utilising new data). In the illustration, a well-defined (narrower) distribution of existing understanding more or less remained the same after ten new, mostly contradicting data.
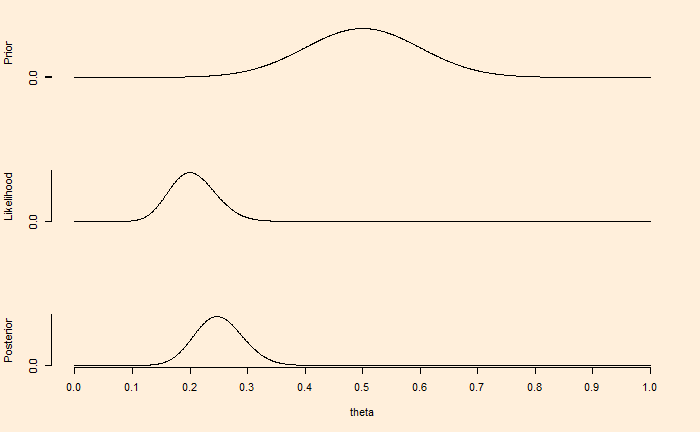
Now, the same situation but collected 100 data, with 80% leading to tails (the same proportion as before).
Now, the inference is leaning towards new compelling pieces of evidence. While Bayesian analysis never prohibits the use of broad and non-specific beliefs, the value of having well-defined facts is indisputable, as illustrated in these examples.
If there are multiple sets of prior available, it is prudent to check their impact on the posterior and map their sensitivities. Sets of priors can also be joined (pooled) together for inference.
We have seen in an earlier post how the Bayes equation is applied to parameter values and data, using the example of coin tosses. The whole process is known as the Bayesian inference. There are three steps in the process – choose a prior probability distribution of the parameter, build the likelihood model based on the collected data, multiply the two and divide by the probability of obtaining the data. We have seen several examples where the application of the equation to discrete numbers, but in most real-life inference problems, it’s applied to continuous mathematical functions.
The objective
The objective of the investigation is to find out the bias of a coin after discovering that ten tosses have resulted in eight tails and two heads. The bias of a coin is the chance of getting the observed outcome; in our case, it’s the head. Therefore, for a fair coin, the bias = 0.5.
The likelihood model
It is the mathematical expression for the likelihood function for every possible parameter. For processes such as coin flipping, Bernoulli distribution perfectly describes the likelihood function.
Gamma in the equation represents an outcome (head or tail). If the coin is tossed ‘i’ times and obtains several heads and tails, the function becomes,
The calculations
1. Uniform prior: The prior probability of the Bayes equation is also known as belief. In the first case, we do not have any certainty regarding the bias. Therefore, we assume all values for theta (the parameter) are possible as the prior belief.
The first figure demonstrates that if we have a weak knowledge of the prior, reflected in the broader spread of credibility or the parameter values, the posterior or the updated belief moves towards the gathered evidence (eight tails and two heads) within a few experiments (10 flips).
On the other hand, the prior in the second figure reflects certainty, which may have been due to previous knowledge. In such cases, contradictory data from a few flips is not adequate to move the posterior towards it.
But what happens if we collect a lot of data? We’ll see next.
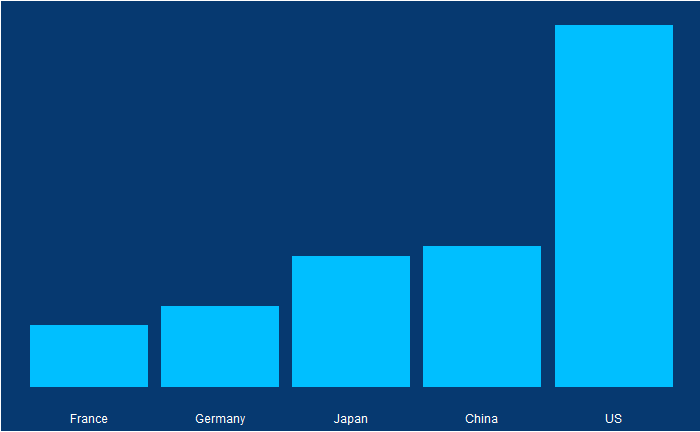
Political pitches are notorious for exaggerating facts. One example is the 2011 state of the union address of then-US President Obama. Here, he created a visual illusion using a bubble plot in the following form to represent how America’s economy compared with the rest of the top 4. Note what follows here is not the exact plot he showed but something I reproduced using those data.
Doesn’t it look fantastic? The actual values of GDP of the top 5 in 2010 were:
Country
GDP (trillion USD)
US
14.6
China
5.7
Japan
5.3
Germany
3.3
France
2.5
The president used bubble radii to scale the GDP numbers, which is not an elegant style of representation. It is because the area of the circle and the perspective it creates for the viewer squares with the radius. In other words, if the radius is three times, the area becomes nine times.
What would have been a better choice was to use the radius for scaling the bubble.
Or use a barplot.
Reference
The 2011 State of the Union Address: Youtube (pull up to 14:25 for the plot)
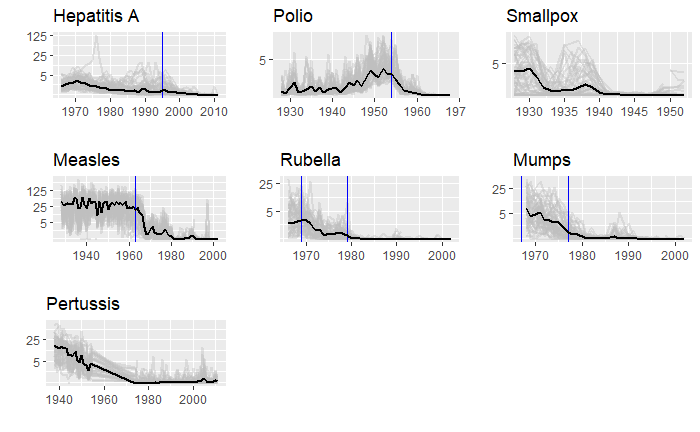
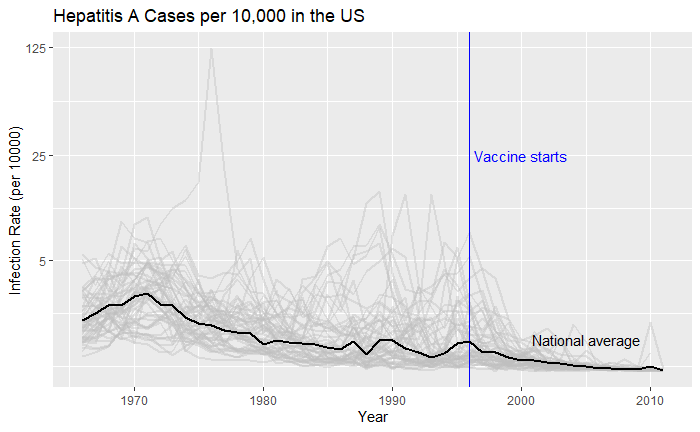
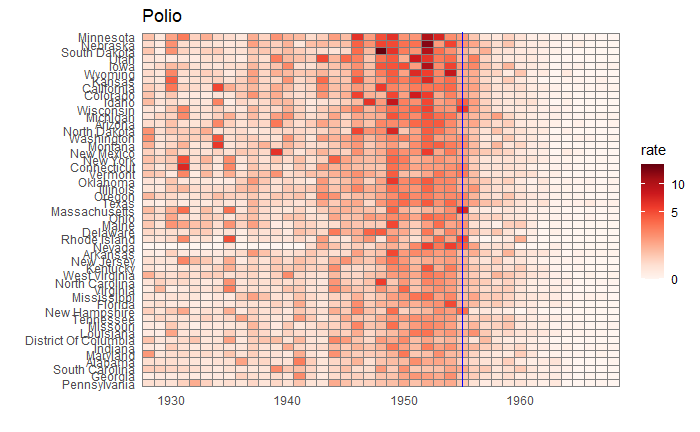
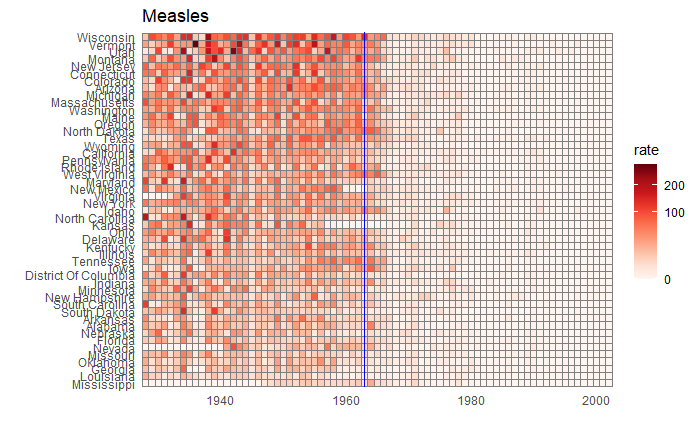
We will end this series on vaccine data with this final post. We will use the whole dataset and map how disease rates changed after introducing the corresponding vaccines. The function, ‘ggarrange’ from the library ‘ggpubr‘ helps to combine the individual plots into one.
We have used years corresponding to the introduction of vaccines or sometimes the year of licencing. In Rubella and Mumps, lines corresponding to two different years are provided to coincide with the starting point and the start of nationwide campaigns.
We have seen how good visualisation helps communicate the impact of vaccination in combating contagious diseases. We went for the ’tiles’ format with the intensity of colour showing the infection counts. This time we will use traditional line plots but with modifications to highlight the impact. But first, the data.
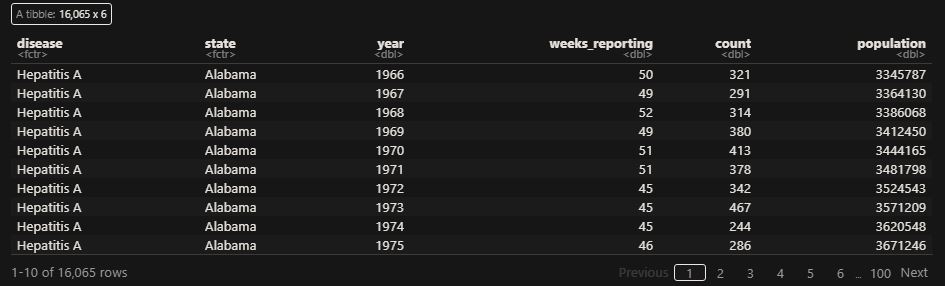
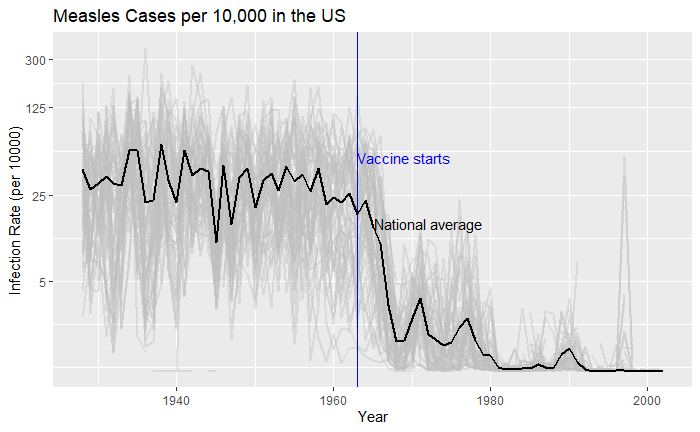
‘count’ represents the weekly reported number of the disease, and ‘weeks_reporting’ indicates how many weeks of the year the data was reported. The total number of cases = count * 52 / weeks_reporting. After correcting for the state’s population, inf_rate = (total number of cases * 10000 / population) in the unit of infection rate per 10000. As an example, a plot of measles in California is,
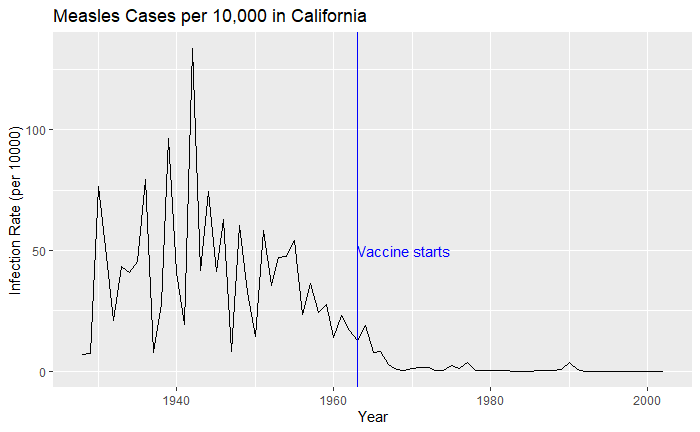
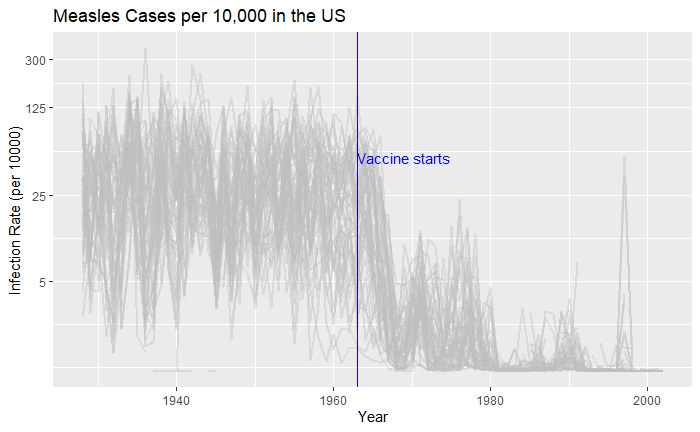
Nice, but messy, and therefore, we will work on the aesthetic a bit. First, let’s exaggerate the y-axis to give more prominence to the infection rate changes. So, transform the axis to “pseudo_log”. Then we reduce the intensity of the lines by making them grey and reducing alpha to make it semi-transparent.
vac_data %>% filter(disease == "Measles") %>% ggplot() +
geom_line(aes(year, inf_rate, group = state), color = "grey", alpha = 0.4, size = 1) +
xlab("Year") + ylab("Infection Rate (per 10000)") + ggtitle("Measles Cases per 10,000 in the US") +
geom_vline(xintercept = 1963, col ="blue") +
geom_text(data = data.frame(x = 1969, y = 50), mapping = aes(x, y, label="Vaccine starts"), color="blue") +
scale_y_continuous(trans = "pseudo_log", breaks = c(5, 25, 125, 300))
What about providing guidance with a line on the country average?
Vaccination is a cheap and effective way of combating many infectious diseases. While it has saved millions of people around the world, vaccine sceptics also emerged, often using unscientific claims or conspiracy theories. This calls for extra efforts from the scientific community in fighting against misinformation. Today, we use a few R-based visualisation techniques to communicate the impact of vaccination programs in the US in the fight against diseases.
We use data compiled by the Tycho project on the US states available with the dslabs package.