What is in the Envelope
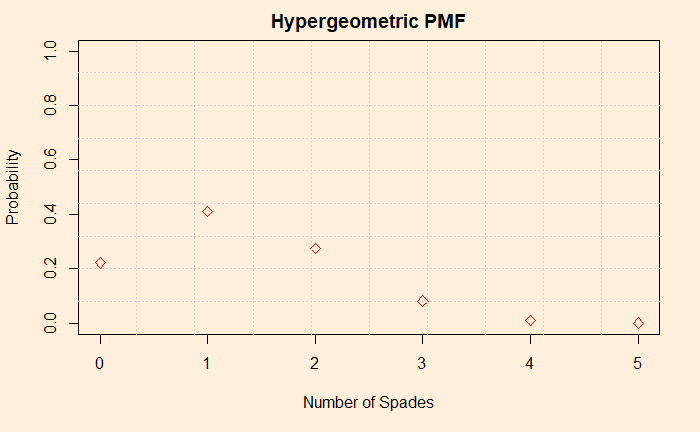
Here is a puzzle. There is a 200 EURO currency in one of the two envelopes, A and B. If you guess the right one, you can get the cash. Additionally, you can avail of a clue, which works as follows: There is a jar with five balls in it – three of them having the alphabet (A or B) of the envelope that carries the currency and two with the other alphabet. You can pick on the ball at random if you like. The price to pay for the clue is 25 EURO. The questions are:
1) Is the clue worth 25 EURO?
2) If not, what is the maximum amount you would like to pay?
3) Would you be willing to pay for a second clue and pick up another ball?
Let’s answer the first question. The expected value from the guess without taking any clues is 0.5 x 200 + 0.5 x 0 = 100 EURO. It is because there is a 50-50 chance that your guess turns right. What is the expected value of the guess with the first clue? It is 0.6 x 200 + 0.4 x 0 = 120 EURO. When you pick one ball, there is a 60% (0.6) chance that it is the right one (3 out of 5) and a 40% chance it is the wrong one.
Therefore, the maximum added value of going for the clue is 120 – 100 = 20 EURO. So, the answer to the first question is NO, and the second is 20 EURO.
What about a second pick? To answer this, we will need to perform several conditional probabilities using our favourite Bayes’ rule, which we’ll do next.
Is Extra Information Helpful? A Probability Puzzle: William Spaniel
What is in the Envelope Read More »