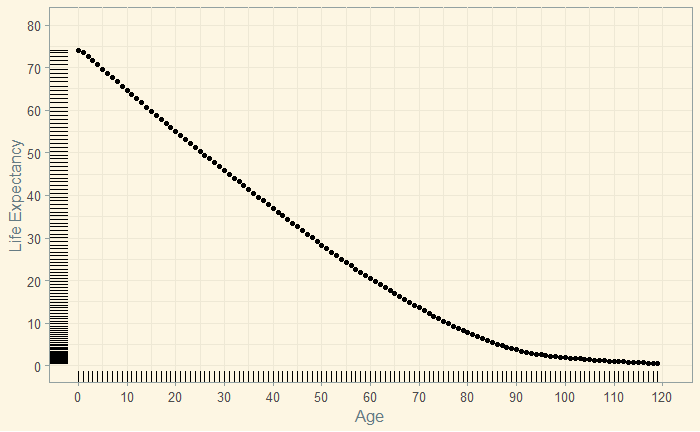
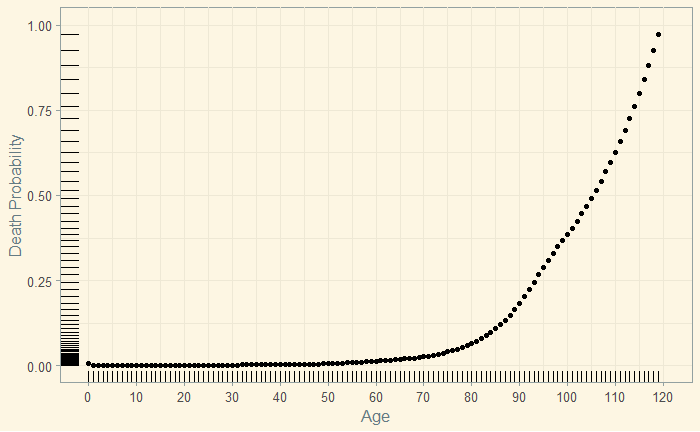
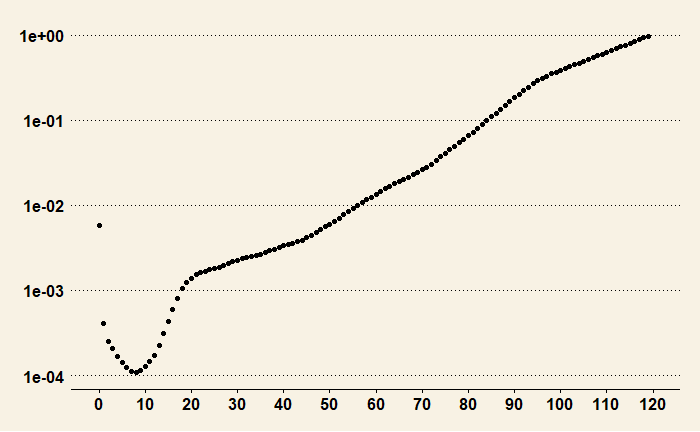
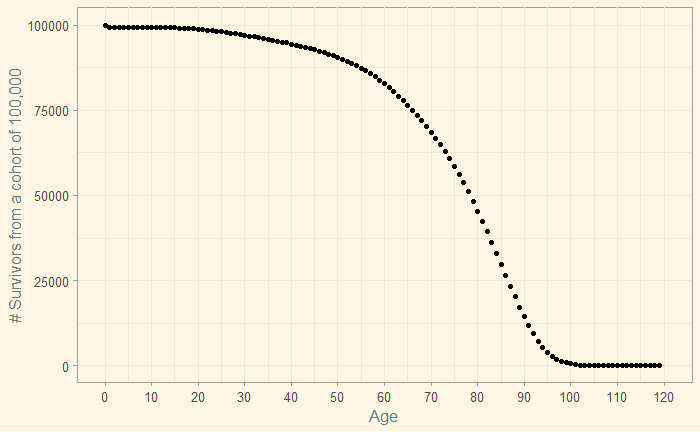
Gambler, Learner and Logician
Amanda, Becky and Carol are at a betting station near the coin-flipping game. They observe five tosses and see all of them landing on heads.
Amanda: “It landed five times on heads; a tail is due, and I will bet on tails this time.
Becky: “It is a bised coin. The probability for the next flip to land on heads is high; I will bet on heads.
Carol: “Amanda has committed a fallacy. Becky may be right, but induction based on the first five tosses can still be logically incorrect. So there is no point betting either way”.
Who is right here?
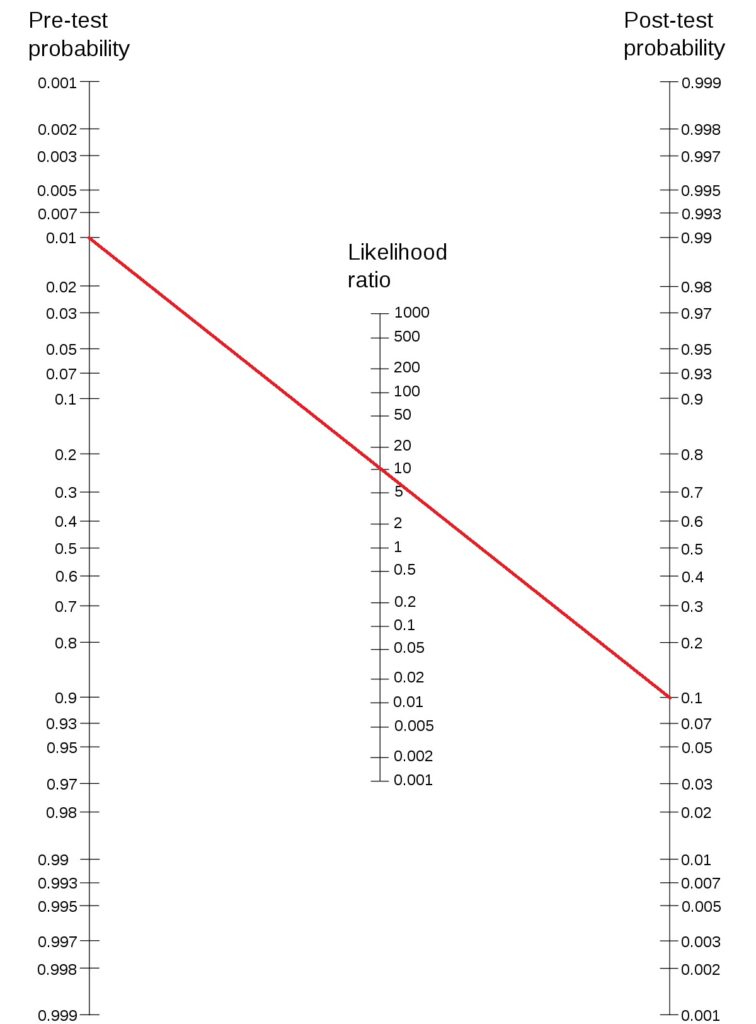
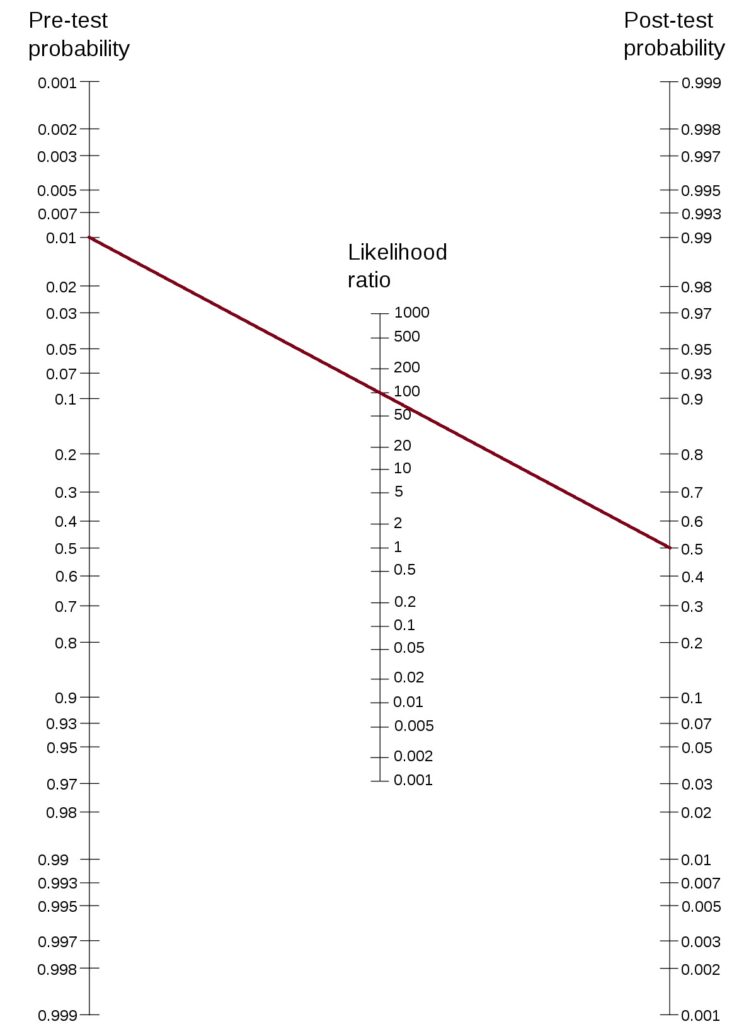
Amanda has committed the Gambler’s fallacy. By expecting a tails due, she forgets about the independence of the trials.
Becky’s stand is based on her interpretation of the observations. Her argument is still not logically water-tight. From the casino’s point of view, using a biased coin is risky; people like Becky will find it easily and become rich.
In the absence of strong evidence, Amanda’s logic is more acceptable.
Gambler, Learner and Logician Read More »