Now, we create a new variable, FAT (in kg), multiplying fat percentage with weight. First, we rerun the correlation to check how the new variables relate.
We have seen estimating the variance inflation factor (VIF) is a way of detecting multicollinearity during regression. This time, we will work out one example using the data frame from “Statistics by Jim”. We will use R programs to execute the regressions.
This regression will model the relationship between the dependent variable (Y), the bone mineral density of the femoral neck, and three independent variables (Xs): physical activity, body fat percentage, and weight. The first few lines of the data are below:
The objective of the regression is to find the best (linear) model that fits BMD_FemNeck with pcFAT, Weight, and Activity.
Call:
lm(formula = BMD_FemNeck ~ pcFAT + Weight + Activity, data = M_data)
Residuals:
Min 1Q Median 3Q Max
-0.210260 -0.041555 -0.002586 0.035086 0.213329
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 5.214e-01 3.830e-02 13.614 < 2e-16 ***
pcFAT -4.923e-03 1.971e-03 -2.498 0.014361 *
Weight 6.608e-03 9.174e-04 7.203 1.91e-10 ***
Activity 2.574e-05 7.479e-06 3.442 0.000887 ***
---
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Residual standard error: 0.07342 on 88 degrees of freedom
Multiple R-squared: 0.5201, Adjusted R-squared: 0.5037
F-statistic: 31.79 on 3 and 88 DF, p-value: 5.138e-14
The relationship will be:
5.214e-01 – 4.923e-03 x pcFAT + 6.608e-03 x Weight + 2.574e-05 x Activity
To estimate each VIF value, we will first consider the corresponding X value as the dependent variable (against the remaining Xs as the independent variables), do regression and evaluate the R-squared.
The first thing that can be done is to find pairwise correlations between all X variables. If two variables are perfectly uncorrelated, the correlation is zero, one suggesting a perfect correlation. In our case, a correlation of > 0.9 must sound an alarm for multicollinearity.
Another method to detect multicollinearity is the Variance Inflation Factor (VIF). VIF estimates how much the variance of the estimated regression coefficients is inflated compared to when Xs are not linearly related. The way to estimate VIF work the following way:
Create an auxiliary regression for each X, such as X1 = A0 + A*1 X2 + A*2 X3 + … Or how much the X1 regresses using the other independent variables.
Estimate R-squared from the regression model
VIF (X1) = 1/(1-R21)
As a rule of thumb, a VIF of > 10 suggests that X is redundant in the original model.
Regression, as we know, is the description of the dependent variable, Y, as a function of a bunch of independent variables, X1, X2, X3, etc. Y = A0 + A1 X1 + A2 X2 + A3 X3 + …
A1, A2, etc., are coefficients representing the marginal effect of the respective X variable on the impact of Y while keeping all the other Xs constant.
But what happens when the X variables are correlated? – that is multicollinearity.
Finding the average of a set of values (of samples) is something we all know. Annie has 50 dollars, Becky has 30, and Carol has 10. What is the average amount of money they hold? You sum the numbers and divide by the number of sums, i.e., (50+30+10)/3 = 90/3 = 30. This is mean, but more specifically, the arithmetic mean.
Now look at this: I have invested 100 dollars in the market. It gave 10% in the first year, 20% in the second, and 30% in the third. What is the average annualised rate of return? The first instinct is to take the arithmetic mean of the three numbers and report it as 20%. Well, is that correct? Let’s check.
Money at the end of year 1 = 100 x (1.1) = 110 Money at the end of year 2 = 110 x (1.2) = 132 Money at the end of year 3 = 132 x (1.3) = 171.6
Now, let’s calculate the final amount using the proposed mean, i.e., 20%. The calculation led to 100x(1.2)3 = 172.8; not quite the same!
Here, we estimate the geometric mean by multiplying the returns and taking the cube root. Mean = [(1.1)x(1.2)x(1.3)]1/3 = 1.7163 = 1.197216; the average return is 0.1972 or 19.72%. The average return using the new (geometric) mean is 100x(1.197216)3 = 171.6.
Abby ran the first lap at 10 km/hr speed and the second at 12 km/hr. What is Abby’s average speed? The answer is neither (10+12)/2 nor (10×12)1/2. It is 2/(1/10 + 1/12) = 10.9. It is known as the harmonic mean and is given by:
We know standard deviation quantifies the spread of data from the mean. It is an absolute measure, and therefore, it has the same unit as the variable. However, it is limited when comparing two standard deviations of samples having different means. For example, compare the spread of the following two samples: the spending habits of two types of households.
Sample 1 (high income = mean income 400,000): standard deviation = 40,000 Sample 2 (low income = mean income 10,000): standard deviation = 1,000
It appears that the variability of data in the high-income category is higher. Or is it?
In such cases, non-dimensionalizing or standardization of the spread comes in handy. The Coefficient of Variation (CV) is one such. It is the ratio between the standard deviation and the mean. Since both possess the same unit, the ratio is dimensionless.
CV = Standard Deviation / Mean
Let’s calculate the CVs of sample 1 and sample 2. CV1 (high income) = 400,000 / 40,000 = 10 CV2 (low income) = 10,000 / 1,000 = 10
Anna must select seven classes out of the 30 non-overlapping courses. Each course happens once a week and is distributed equally from Monday through Friday (6 courses a week). What is the probability that she has courses every day (Monday through Friday)?
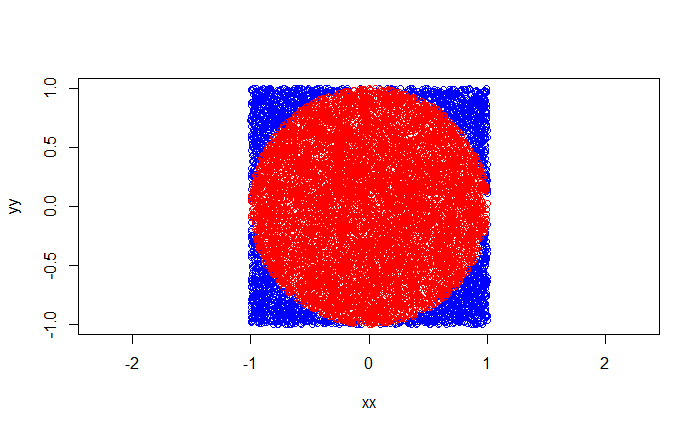
The probability of hitting inside the circle inscribed in a square is a well-known problem. Looking at the geometries, one can find that the required probability is pi/4.
If X is the radius of the circle, then the diameter, 2X, is equivalent to the side of the square. The required probability is the area of the circle (green) over the area of the square. I.e., pi x X2 / (2X) x (2X) = pi / 4. Or four times this probability is pi.
We will do an R code to simulate this case. Step 1: Create random uniformly distributed points between two equal intervals (-1, 1) to produce a 2 x 2 square.
pts <- 10000
xx <- runif(pts, -1, 1)
yy <- runif(pts, -1, 1)
plot(xx, yy, asp = 1, col = "blue")
Step 2: Select only those points that satisfy the following conditions for a circle: X2 + Y2 < 1, 1 being the circle’s radius that fits inside the square.
for(i in 1:pts){
if(xx[i]^2 < 1 - yy[i]^2) {
xx1[i] <- xx[i]
}else{
xx1[i] <- 0
}
}
yy1[which(xx1 == 0)] <- 0
plot(xx1, yy1, asp = 1, type = "p", col = "red")
Combining two plots,
The ratio of the number of points inside the circle to that of the square multiplied by 4 is:
4*length(xx1[abs(xx1) > 0 ]) / length(xx)
3.1456
Tailpiece
Increase the number of points to 100,000, and you get a much cleaner picture:
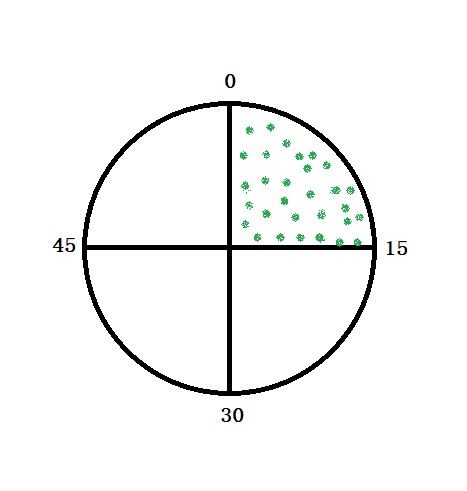
Romeo and Juliet plan to meet over coffee between 3 PM and 4 PM. Not known for punctuality, either is willing to wait 15 minutes for the other to show up. What is the probability they will have coffee together?
We will do a graphical solution followed by simulations.
The required probability is the chance of two people meeting inside the shaded area of the circle. It is estimated as 1 – chance of both not making it inside the region = 1 – (3/4)x(3/4) = (16-9)/16 = 7/16 = 0.437.
Police know that the crime was committed by one of the two suspects, A and B, with equal evidence against them initially. Further investigation suggests that the blood type of the guilty is found in 1/10 of the population. If A’s blood matches this type, whereas B’s is unknown, what is the probability that A is guilty?
The probability that A is guilty, given his blood matches = P(A|M) P(A|M) = P(M|A) x P(A) /(P(M|A) x P(A) + P(M|B) x P(B)) P(A|M) = 1 x (1/2) /[1 x (1/2) + (1/10)x (1/2)] = 10/11

![\sqrt[n]{\Pi x}](https://thoughtfulexaminations.com/wp-content/ql-cache/quicklatex.com-fbf592781a23df1cd19d67b85addacdc_l3.png "Rendered by QuickLaTeX.com")