In one of my previous posts, we have seen theoretical considerations of gambling with the roulette wheel. Today, we play the game not by going to a casino but by sitting behind a computer, using a simulation technique known as the Monte Carlo method.
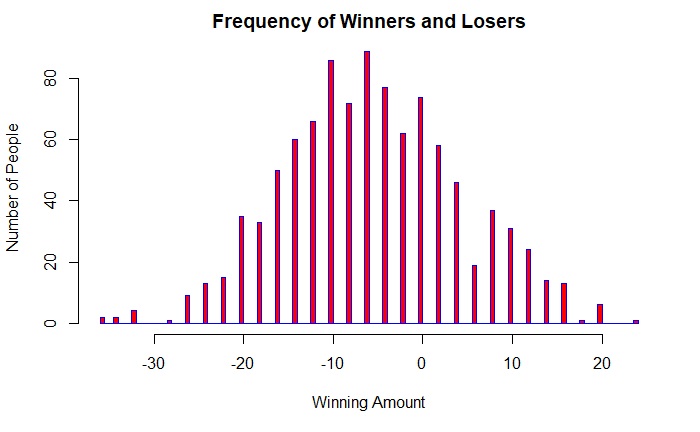
Here, we let 1000 people play 100 games of each red/black betting. Starts with the players first:
Approximately 250 people (25%) have won some money. Also, you don’t see the perfect distribution that you would have expected in a Bernoulli trial. This is because it is not a theoretical estimation but a real game using random numbers.
The Game is for Casino
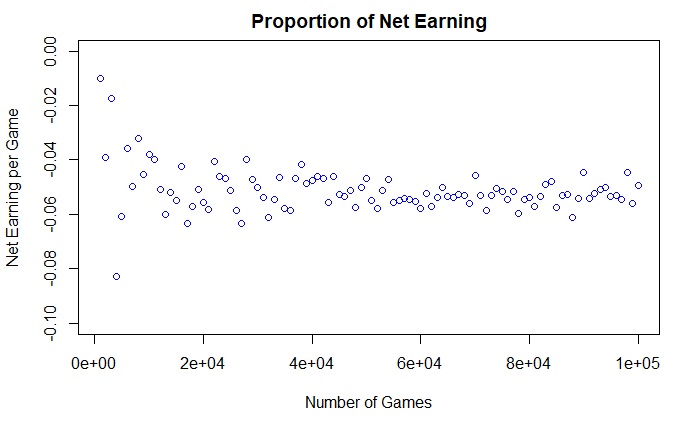
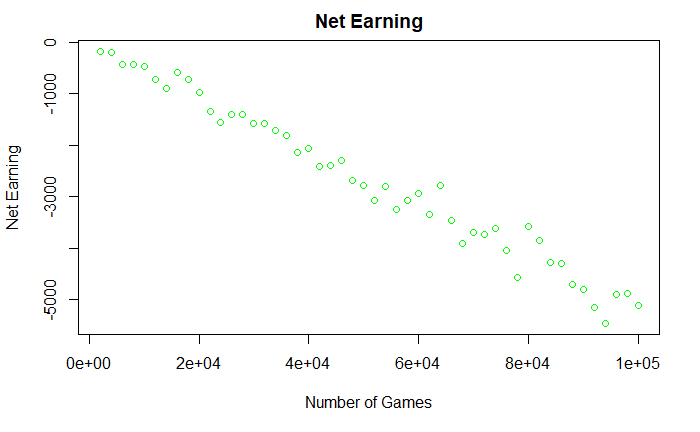
The rest of the post is about the casino owner. We know that the odds of a gambler winning colour is (18/38), and the odds of losing is (20/38) – about five cents per dollar net going the casino’s way. You will see from the picture that as the number of games increases, the certainty of getting 5 cents per dollar increases. It is sometimes known as the law of large numbers, where the actual value converges to the expected value as the number of events increases.
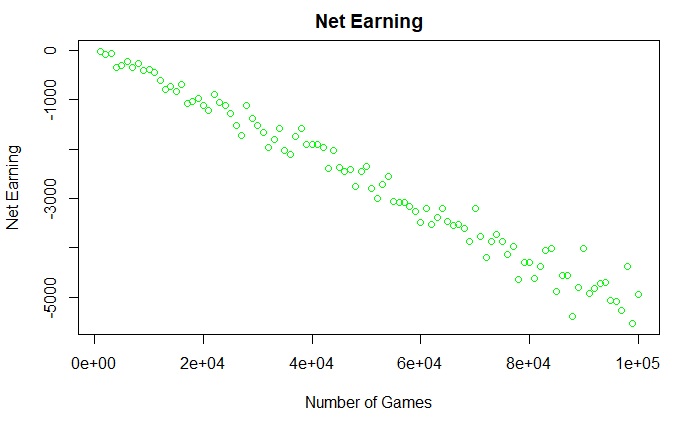
The next plot summarises the net money the casino earned in the day. Unless a few people turn up and play a really small number of games, the company would make what is expected: 5 cents per every dollar of value.
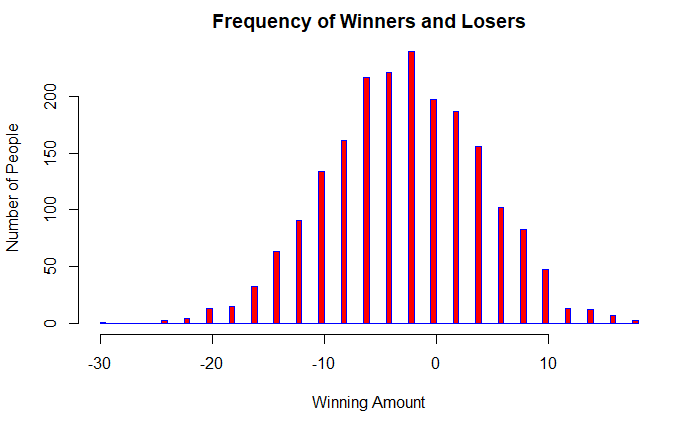
Now, let 2000 people play fewer (50) games each.
About 600 people out of 2000 (30%) may have won some money. As far as the Casino owner is concerned, he is pretty happy!
This one is going to disappoint some of you. What causes cancer? The answer is – life. Cancer happens; well, most of the time!
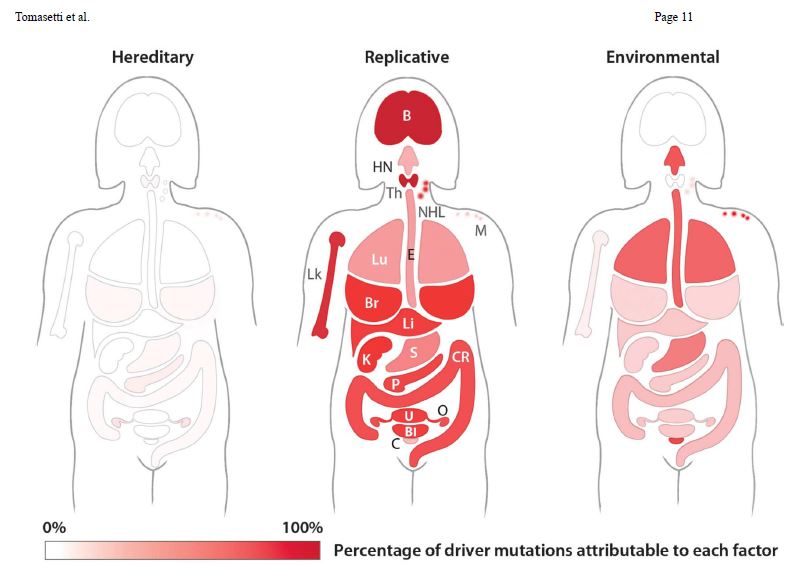
Primary reasons for cancer in humans are classified into three categories: environmental (E), hereditary (H), and mistakes during DNA replications (R).
Researchers at Johns Hopkins University evaluated cancer incidence in 69 countries and found correlations between cancer risks and these factors. Before going into details, please see the picture that I copied from Tomasetti’s paper (Tomasetti et al., Science. 2017 March 24; 355(6331): 1330–1334. doi:10.1126/science.aaf9011.).
First, a primer on what I meant by the replication factor, R. Approximately three mutations occur every time a stem cell divides. Most of these are inconsequential to us, but occasionally, they cause trouble. What is so special about stem cells? Stem cells are the body’s prime cells that give birth to cells with specialized functions – the blood cells, brain cells, heart muscle cells or bone cells.
Leading environmental factors known to cause cancer in humans include UV from sunlight, tobacco, soot, asbestos, carcinogenic chemicals, and ionising radiation.
Randomness, Again
These results also partly explain the observed stochastic nature of the disease. Remember, “my granny had cancer without smoking, and my uncle still smoking healthy”, all that stuff! Now you know the reasons for the deadly outcome are many – some you know already, some don’t, and perhaps never will.
Not an Either Or
Results from the study also point to the human tendency to rush to wrong conclusions, similar to a deductive fallacy. Environmental reasons are responsible for some cancer types, but it does not mean all cancers are due to Environment. To be precise, two in three are not! Does it mean you ignore environmental factors, smoke, eat tobacco, and give up sunscreen? Quite the opposite. One must continue avoiding exposure to carcinogens as they are the levers to manage those individual probabilities that are within your control, which eventually leads to a reduction in the combined chances of getting the disease (remember the AND rule of probability?). You thus avoided the disease, at least for a while!
The last takeaway of the study, which showed Pearson’s linear correlation of 0.804 between total stem cell divisions and lifetime cancer risk, leads to an unwanted prize for achieving higher life expectancies – the more you live, the more your chance of dying of cancer!
We all understand deterministic processes, where the outcome of an action is definite and predictable. You touch a hotplate, and it hurts, possibly a blister by the next day! Press the pedal, and the car goes faster. Certainty is nice and visible, a cause and an effect; decision-making is easy. Personal stories reinforce our appreciation for deterministic processes. The brain is wired for determinism.
On the other hand, stochastic processes are not straightforward and require deliberate training to understand. Doctors say smoking causes cancer, yet we don’t see all smokers dying of cancer. To make matters worse, some non-smokers suffer lung cancer!
When Reasons are Many, Output is a Chance
It is the randomness of input that governs stochastic processes. The output becomes a set of probabilities. Be it weather predictions or movements in the stock market. Climate scientists use the best of their physics and thermodynamics to forecast the weather using the available data on wind speed, temperature, humidity, and pressure. Even small uncertainties in those variables can result in large ranges in predictions. Some of them may be random, others we never understand.
Extreme cases are the black swan events. Here, an event has a tiny chance of occurring but creates unimaginable consequences. Is anything better than the COVID-19 pandemic and its impact on the global economy?
This post is inspired by the famous book Fooled by Randomness by Nassim Nicholas Taleb.
Imagine a person who wants to play Russian Roulette. It is a game in which the referee (or the executioner?) takes a revolver containing one bullet in one of its six chambers, spins the cylinder, points to the head and pulls the trigger. If you survive, you get a prize – 4 million dollars.
Alive at Age 50
As seen in my previous posts, one can determine the person’s survival chance is 5 in 6 (83%) in one game. This person decides to play this game once a year, starting at age 25. What is the probability that she will become a 100-million-dollar net-worth individual (NWI) by 50? Use the Bernoulli trial that we had discussed in the previous post, and we get a survival chance of about 1% after 25 games [25C25 (5/6)25(1/6)0]. The odds to earn 100 million this way are, indeed, small; no two opinions but to acknowledge her exceptional luck!
Let me complicate the plot: imagine 1000 individuals started playing this game in different parts of the world (different venues, referees, different TV sponsors!). There is a definite possibility of about ten winners (give or take a few) after the 25th season of this deadly game.
A Superhero is Born
Suddenly, these superstars are on the covers of Fortune, in popular TV shows, and parents of young children start pressuring their kids to learn this game. Spiritual gurus proclaim their remarkable moral habits; TV anchors interview their grandmothers; data analysts flood YouTube, fitting their BMI to eating habits to academics with their achievements. Ladies and gentlemen, I am presenting you this evening: the superhero of all fallacies, the Survivorship Bias. It is a selection bias in which reasoning is made by considering only the survivors’ data and not those that have already ceased to exist.
Survivorship bias exists everywhere, far more than what you think. The superstars of the stock market were Taleb’s favourite example. Consistent longer-term performances of fund managers have been the subject of many studies. More often than not, they were no better than Roulette gamers. Then comes the band of ultra-rich business leaders – risk-takers, college dropouts, lonely, full of grand ideas …
Another example is our obsession with the past. You must have heard about extraordinary claims of how prosperous, healthy and long-living our ancestors used to be when living ‘close to nature’ – all these when the average life expectancy was just in the 20s! Of course, the author who wrote the stories included only those who survived their adolescence AND showed some amazing ‘acts of valour’. Try calculating the joint probability of the following: chance of surviving adolescence x having some remarkable skills x being found by the author x getting the king’s approval to include in the book.
Guess Which outcome is more likely if I flip a coin six times – HHHHHH or HTTHTH?
Now, a slightly different one: assume a gambler gets 1 dollar for every head and loses 1 for the tail on a coin-tossing game; which of the two outcomes can shock you at the end of the sixth round of play – 6 dollars or 0 dollars?
These two problems have few things in common other than the fact that both are coin games. Let’s understand them quantitatively.
One Prize or Multiple Prizes?
The first problem is getting a specific sequence, i.e. HHHHHH or HTTHTH. The probability of getting any of the two is the same, which is (1/2) multiplied six times (0.5 x 0.5 x 0.5 x 0.5 x 0.5 = 0.0156). In other words, both outcomes have the same chance of about 1%!
In the second problem, the sequence doesn’t matter, but getting (in some order) six heads or three. The second problem needs a new technique called a Bernoulli or binomial trial. In the mathematical form,
the probability of s successes in n rounds is nCs x ps x q(n-s)
nCs, The number of combinations of nthings, taken sat a time or [n!/s!(n-s)!]
p = probability of success in an individual trial
q = probability of failure in an individual trial (= 1 – p)
That “!” mark in the formula means factorial. For example, 4! (four factorial) means 4 x3 x 2 x1; 5! = 5 x 4 x 3 x 2 x 1 etc
Binomial Distribution
Chance for 3 heads out of 6 (which means 0 dollars in the end!) 6C3 x (1/2)3 x (1/2)(6-3) = (6 x 5 x 4 x 3 x 2 x 1)/(3 x 2 x 1 x 3 x 2 x1) x 0.0156 = 0.3125 31% chance of losing all money
Chance for 6 heads out of 6 (6 dollars in the end!) 6C6 x (1/2)6 x (1/2)(6-6) = (6 x 5 x 3 x 2 x 1)/(6 x 5 x 3 x 2 x 1) x 0.0156 = 0.0156. 1% chance of winning all.
Note that the binomial coefficient, 6C3 or 6C6, made the difference between the first problem and the second.
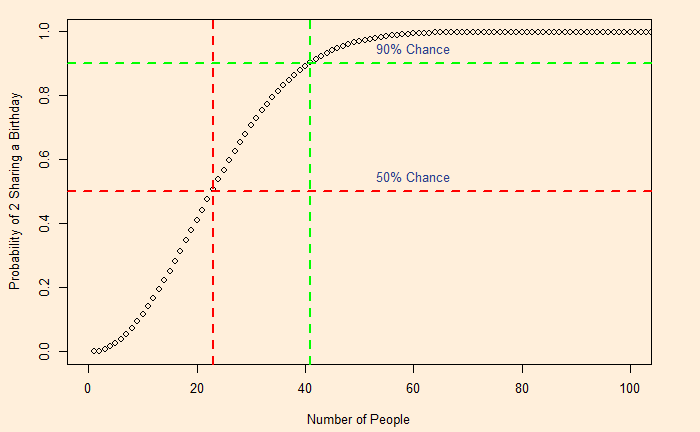
The birthday problem. What is the minimum number of people required to be in a room to have a 90% chance that at least two individuals share a birthday? The answer is about 41 people. You may have guessed more than 41; the puzzle has led to people overestimating the number.
We will see the calculations but a few basic probability concepts first.
Two definitions
Independent Events. Two events are independent if one does not affect the other. Two flips of a coin: the outcome from the second is independent of the first outcome.
Mutually Exclusive Events. When one happens, the other can not occur. Examples are day and night, winning and losing a game, or turning left and right in one.
1. The law of multiplication (AND Rule)
For independent events, the joint probability of occurrence of one and the second is obtained by multiplying their individual probabilities.
P (A and B) = P(A) x P(B)
Flip a coin twice: the chance of getting two heads in succession is equal to the chance of getting the first head x chance of getting the second head. The probability of each is 1 in 2. So the overall probability P (head and head) = (1/2) x (1/2) = 0.25 (25% chance).
Note that this AND rule is a special case of a general Conjunction Rule that says
P(A and B) = P(A) x P(B given A)
[if A and B are independent, P(B given A) = P(B)]
An example: the probability of drawing two Aces from a deck of cards (no replacement). It is given by multiplying the probability of getting the first ace (4/52), and the second given the first is an ace (3/51) = 12/(52 x 51) = 1/221.
2. The Law of addition (OR Rule)
The probability of getting A or B is equal to the probability of getting A plus the probability of getting B minus the probability of A and B. P (A or B) = P(A) + P(B) – P (A and B)
The equation simplifies when the events are mutually exclusive, or P (A and B) = 0 (both can not happen at once)
P (A or B) = P(A) + P(B). I throw a 6-sided dice, and the chance of getting 1 or 3 is = (1/6)+(1/6) = 2/6.
3. The law of subtraction
The probability of something to occur is equal to 1 minus the probability that it does not occur. P(A) = 1 – P(A’)
The Birthday Problem
Let’s build the solution from the smallest group. What is the probability of two people sharing a birthday in a group of 2? To answer this, we first go to the inverse problem – the chances of two people not sharing a birthday – and subtract that from 1 (using the subtraction rule because you can not have unique and shared birthdays at once).
The chance of one person having a unique birthday = 1
The chances that the second person does not share the previous birthday = 364 available days in 365 = (364/365)
Using the AND rule, we calculate the probability of the two having unique birthdays. It is because the second person’s birthday is not affected by the birth of the first person (independent events).
So, it is 1 x (364/365).
If we extend this logic for a group of 3, the probability becomes 1 x (364/365) x (363/365). So, for 20 people, it becomes 1 x (364/365) x (363/365) x … x (346/365) = 0.58. Therefore, the chance of at least one shared birthday in a group of 20 is equal to (1 – nobody shares) = (1 – 0.58) = 0.42 (42%)
For a group of 41, it is [1 – 1 x (364/365) x (363/365) x … x (325/365)] = [1 – 0.10] = 0.90 (90%) So the minimum number of people for a 90% chance to share a birthday is 41
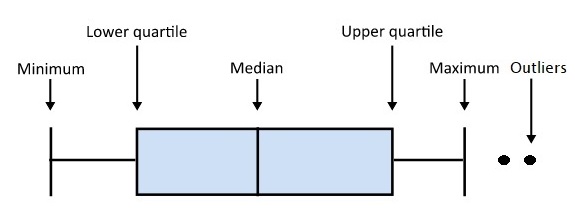
The boxplot is my favourite plot. The plot can summarise and maintain the statistical perspective by showing the data distribution. So, what is a boxplot? The following picture explains it.
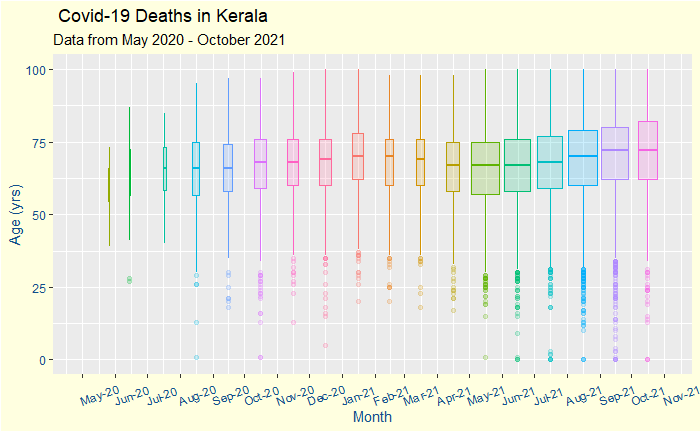
Now, let’s apply the plot to COVID-19 deaths. The data summarises the distribution of COVID deaths from its beginning. Data comes from the Covid dashboard of the Government of Kerala.
First, it is a time series organised monthly. The box’s width represents the total number of deaths in that month. The ‘boxes’ take you through the time of the first wave and the second one caused by the Delta (B.1.617.2) variant.
Broad Observations
The number of deaths shot up from May 2021, the start of the fast-spreading second wave of infection.
The median age of the deceased did not show any reduction after May 2021 (after the arrival of the delta), dismissing speculations on the deadliness of the new strain.
The median age of death marginally dropped starting in March, which coincided with the vaccination program for the elderly. The number systematically increased after June, coinciding with the younger population taking the vaccination. Note that these are correlations and do not necessarily mean causations!
Deaths for people below the age of 35 years do happen but are rare outliers in the statistics.
The incidence of death may be beginning to ease out towards the end.
If you like the boxplot, here is your bonus plot
The new plot includes the actual data points. More men have died from the disease, and for whatever reason, their median age at death is also a couple of years lower than women.
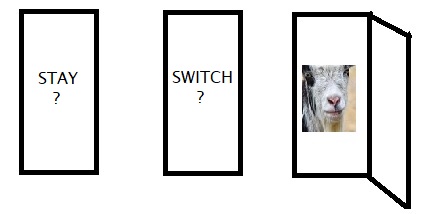
The Monty Hall problem has confused the heck out of people. It is a probability puzzle loosely based on an American game show, Let’s Make a Deal, once hosted by Monty Hall. The problem statement is as follows:
You are in a game show, and the host shows three closed doors behind which there are three objects – one car and two goats. Your task is to guess the correct door and win the car. Once you make the pick, the host opens one of the other two doors and shows you a goat. She now hands in a chance to switch your original choice. Will you stick with your original door or switch to the remaining unopened door?
The correct answer is: you better switch the door, but let’s work out how I arrived at this.
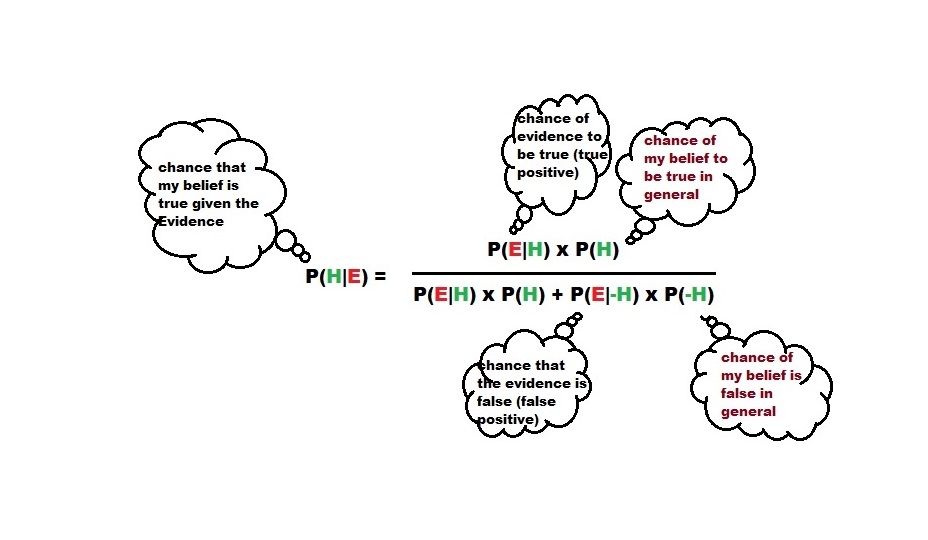
Method 1: Bayes’ Theorem
The equation of life! The equation is pasted below:
Turn that to fit our problem, the chance that my door is correct, provided the host showed me the goat, P(MyDoor|ShowGoat) =
P(ShowGoat|MyDoor) x P(MyDoor) / [ P(ShowGoat|MyDoor) x P(MyDoor) + P(ShowGoat|OtherDoor) x P(OtherDoor)]
P(ShowGoat|MyDoor) = chance of the host showing a goat in that door if my choice is right = 0.5 (or 50% chance to pick one of the remaining doors as both have goats)
P(MyDoor) = prior chance of my door having a car = 0.33 (or 1 in 3, at the beginning of the game, it’s anyone’s pick)
P(ShowGoat|OtherDoor) = 1, (100%, the host has only this option as the other door has the car)
P(OtherDoor) = 0.33 (original chance of the other door having a car)
P(ShowGoat|MyDoor) = (0.5 x 0.33) / [ (0.5 x 0.33) + (1 x 0.33)] = 0.33 (1 in 3 chance)
Now, evaluate the chances that the other door has the car once the host showed me a ‘goat door’. P(OtherDoor|ShowGoat) =
P(ShowGoat|OtherDoor) x P(OtherDoor) / [ P(ShowGoat|OtherDoor) x P(OtherDoor) + P(ShowGoat|MyDoor) x P(MyDoor)]
P(ShowGoat|OtherDoor) = chance of the host showing goat in that room if the other room has a car = 1 (or 100%, she has no other option)
P(OtherDoor) = prior chance of the other room having a car = 0.33 (or 1 in 3 at the beginning of the game)
P(ShowGoat|MyDoor) = 0.5. If my door has the car, the host had a 50% chance of opening that door
P(MyDoor) = 0.33 (my original chance of choosing one door)
P(OtherDoor|ShowGoat) = (1 x 0.33) / [ (1 x 0.33) + (0.5 x 0.33)] = 0.667 (2 in 3 chances)
So, switching doors has double the chance of winning than sticking to the original choice.
Method 2: Argument
In the beginning, you have a 1 in 3 chance of picking a door that has the car. That automatically means a 2 in 3 (67%) chance to find the car outside your door. Initially, that 67% was hiding behind two doors, but the host has helped you narrow that chance by removing one. It’s so simple!
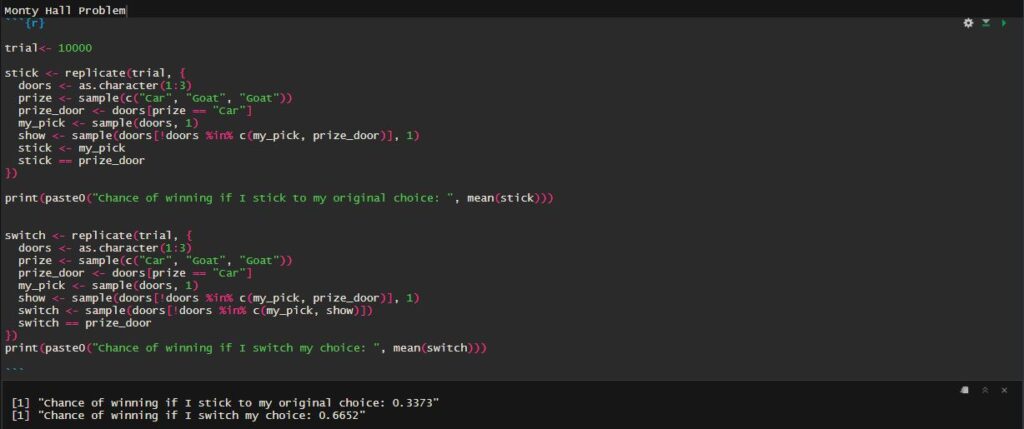
Method 3: Perform Experiments
Still not convinced? Then, you do the actual experiment. There are two ways to experiment: 1) Build three doors, perform hundreds of trials with a partner, and find the average. 2) Perform a Monte Carlo simulation and run the trial a few thousand times. Trust me, I have done the latter using R programming, and the code is here:
In an ideal world, our activities should result in about 2 tonnes of CO2 emissions per person per year, but in reality, it is 70 tonnes for the top 1% and less than 1 for the bottom 50%
The new Oxfam report starkly reminds us of the global disparity in consumption-based CO2 emissions and how the Paris Effect may impact the low-income 50%. The report presents a collection of data and future realisations, but I will not go through all of them.
In one of my previous posts, I commented about the present total CO2 emissions, around 47 billion tonnes in 2018 (Gt/yr). Oxfam report estimates the consumption-based emission to be about 35 Gt in 2015. The emission ratewe need to target for 2030 is 18 GtCO2 to stay on course with the 1.5 oC target. Before we jump into the report details, take a stop for a quick recap of climate targets.
The global mean temperature has now reached about 1 oC above the pre-industrial level; the world needs to keep its peak to about 1.5 oC to manage catastrophic climate change. In other words, the world can only emit a total of 420 – 580 Gt, as per the IPCC special report (SR 15), which is already three years old! So what remains with us to spend from today is less than 500 billion tonnes (carbon budget). There are different pathways to achieve the goal, and one of them is to cut the emissions by half by 2030 and net-zero emissions by 2050.
Back to the report: today’s total global consumption-based carbon emission is 35 GtCO2 – 17 from the top 10%, 15 from the middle 40% and a mere 3 from the bottom 50%! The per capita emissions are
21 tonnes per person for top 10%
5 tonnes per person for middle 40%
< 1 tonne per person for bottom 50%
Note that the top 10% is already trending at the total target of 2030 (18 GtCO2). The report estimates the expected reduction of the richest and the middle to be about 10%, which is much lower than the 90% and 57% required to reach parity (everyone shares the same per capita emissions).
The Paris Effect and its gaining traction in the developed world can lead to another moral failure of the equity principle. As we have seen in the distribution of COVID-19 vaccines, the morally agnostic twins, capitalism and technology, parented by populism and mistrust, will again fail to support the marginalised. Forcing emission cuts across the board will disproportionately impact the poor and widen the existing wealth and opportunity gaps. There must be additional climate finance, with a fair share from the top emitters, not just countries but also individuals beyond borders, to support the lower and middle-income groups to achieve the climate targets. Innovators, especially from the developing world, should also use this opportunity and focus more on inclusive low-carbon technologies.
WebMD ran an article in 2008 titled Eating Breakfast May Beat Teen Obesity. The article caused quite a stir in the public domain. The original study, published in Pediatrics, focused on the dietary and weight patterns of 2,216 teenagers over five years (1998-2003) from public schools in Minneapolis-St. Paul, Minnesota.
Did the study conclude that breakfast is a medicine for teenagers to fight against obesity? At least the title and the opening remarks gave that impression. Before jumping to a conclusion, let us examine the various possibilities.
Cause or a Coincidence?
The first possibility is that it could be a complete coincidence that those who ate breakfast gained less weight. That is an easy remark that one can pass to any such study.
What Other Reasons?
Think about possibilities that can make someone skip breakfast. Maybe she wakes up late and has no time to breakfast before school. This could be because she sleeps long or goes to bed late. What about the eating habits of people who sleep late at night? The late sleepers may pack their meal with more or multiple sets of food.
What about some of them skipping breakfast because they were already obese (for any other reasons) and wished to cut some calories (cause and outcome reversed)?
How important are the study location, socioeconomic background, and education levels? As per the CDC, even in the US, obesity is lower among people with lower and higher income but higher in middle-income groups. What could be the outcome had the research been conducted in India, Australia, The Netherlands, or the Republic of Congo?
Or Just a Correlation?
Would the conclusions have differed if the researchers had examined their lunch, dinner, or snack habits? WebMD leaves some clues.
“A new study shows teenagers who eat breakfast regularly eat a healthier diet and are more physically active throughout their adolescence than those who skip breakfast”.
So it is not just eating breakfast, but a set of other things, or confounding factors, are also important. The first word to notice is regularly, which suggests certain habits. The second one is more physically active, and the third is a healthier diet, which may include more fibre and less fat. We know cutting excessive fat consumption and regular exercise leads to weight loss.
There are many possible explanations to explain this correlation other than a simplistic statement for weight loss. In statistics, these are confounding variables, which happen when a common cause gives out multiple results, leading to the confusion that one of the outcomes is caused by the other.