Disease Spreading through Friendship
You saw friendship paradox as a concept, including its mathematics, but might be wondering if that had any real-life significance. Here is one interesting publication by Christakis and Fowler, who used this feature to predict pandemics.
The researchers monitored the friends of randomly selected individuals for the propagation of an outbreak. The hypothesis was that the illness spreads through the centrally located individuals, who have more connections than the peripheral ones. In such cases, the scientists expected, the S-shaped epidemic curve would shift to the left side (earlier times) for the more well-connected people, who are, as we know, the friends of friends in a friendship network.
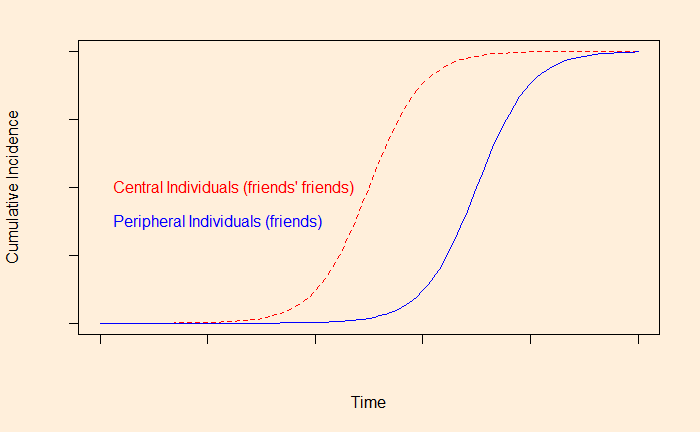
And that literally happened. The investigators monitored the propagation of H1N1 (and seasonal flu) from September 1 to December 31, 2009, at Harward college. Note that H1N1 had started in the US a few months earlier. A group of 744 undergraduate students participated in the study. The students were divided into two groups 1) randomly selected individuals (319) and 2) their friends (425) as named by the random group.
The results showed that the cumulative incident curve for the ‘friends’ group occurred 13.9 days earlier than that of the random group, paving the way for a potential means for the early detection (and intervention) of outbreaks.
Christakis, N. A.; Fowler, J. H., Social Network Sensors for Early Detection of Contagious Outbreaks
Disease Spreading through Friendship Read More »
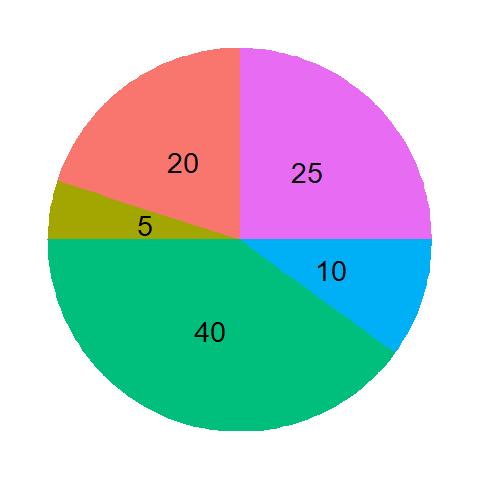
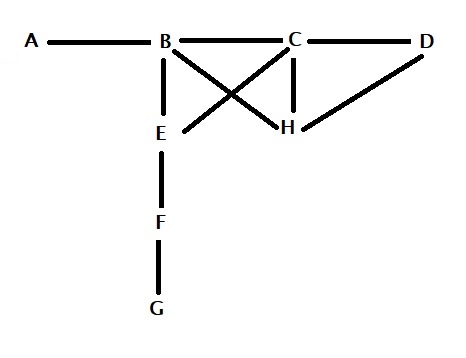




![\\ \text{the average number of friends of friends = } \\\\ \frac{d_A*d_A + d_B*d_B + d_C*d_C + d_D*d_D + d_E*d_E + d_F*d_F + d_G*d_G + d_H*d_H}{d_A + d_B + d_C + d_D + d_E + d_F + d_G + d_H} \\ \\ = \frac{d_A^2 + d_B^2 + d_C^2 + d_D^2 + d_E^2 + d_F^2 + d_G^2 + d_H^2}{d_A + d_B + d_C + d_D + d_E + d_F + d_G + d_H} \\ \\ = \frac{\Sigma{x_i^2}}{\Sigma{x_i}} \\ \\ \text{divide the numerator and the denominator by n} \\ \\ = \frac{\Sigma{x_i^2}/n}{\Sigma{x_i}/n} \\ \\ \text{add and subtract } (\Sigma{x_i})^2/n^2 \text { at the numerator} \\ \\ = \frac{[\Sigma{x_i^2}/n + (\Sigma{x_i})^2/n^2 - (\Sigma{x_i})^2/n^2]}{\Sigma{x_i}/n} \\ \\ = \frac{[\Sigma{x_i^2}/n - (\Sigma{x_i})^2/n^2]}{\Sigma{x_i}/n} + \frac{[(\Sigma{x_i})/n]^2}{\Sigma{x_i}/n} \\ \\ = \frac{[\Sigma{x_i^2}/n - (\Sigma{x_i})^2/n^2]}{\Sigma{x_i}/n} + {\Sigma{x_i}/n}](https://thoughtfulexaminations.com/wp-content/ql-cache/quicklatex.com-786ce585899542d9a42a1b8449675861_l3.png "Rendered by QuickLaTeX.com")

