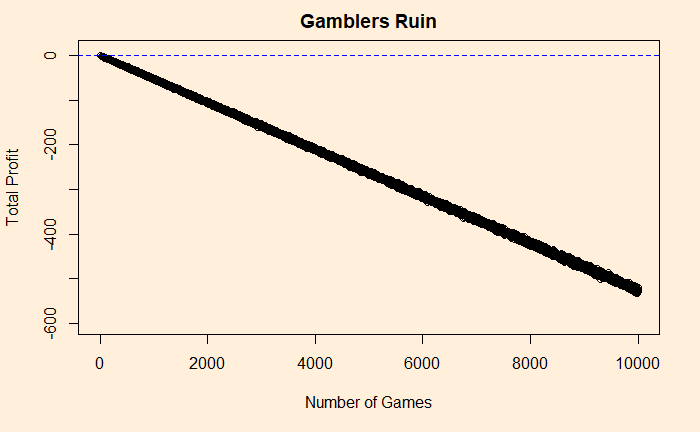
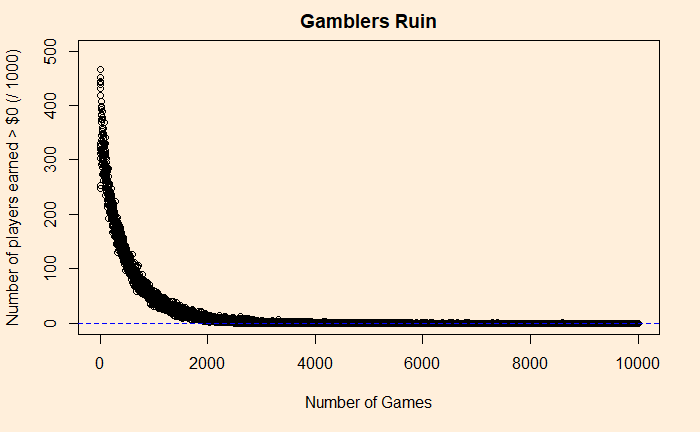
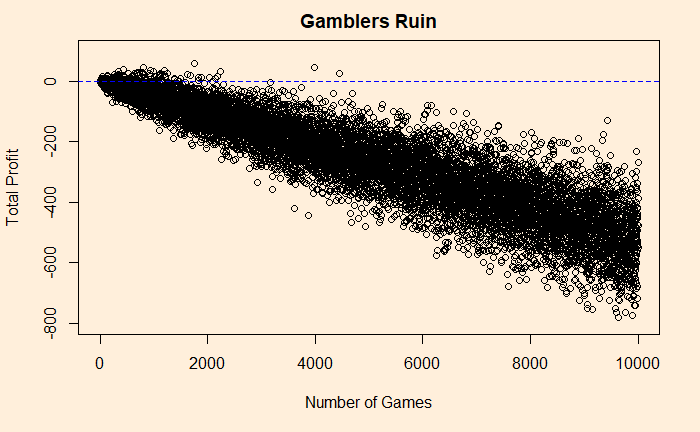
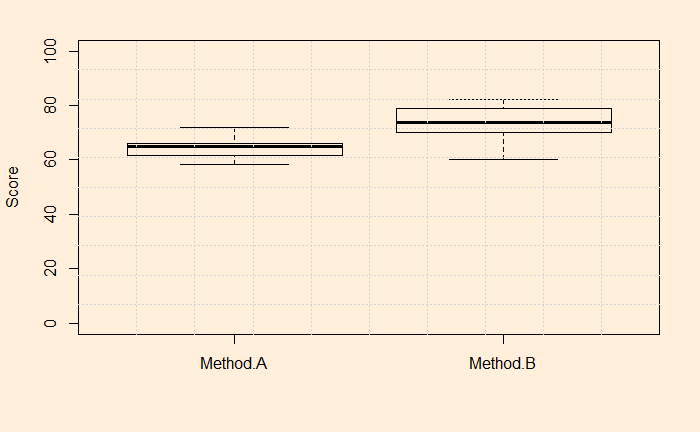
Ellsberg Paradox
Imagine an urn containing 90 balls: 30 red balls and the rest (60) black and yellow balls; we don’t know how many are black or yellow. You can draw one ball at random. You can bet on a red or a black for $100. Which one do you prefer?
| Red | Black | Yellow | |
| A | $100 | $0 | $0 |
| B | $0 | $100 | $0 |
Ellsberg found that people frequently preferred option A.
Now, a different set of choices: C) you can bet on red or yellow vs D) bet on black or yellow.
| Red | Black | Yellow | |
| C | $100 | $0 | $100 |
| D | $0 | $100 | $100 |
Most people preferred D.
Why is it irrational?
If you compare options A and B, you can ignore the column yellow because they are the same. The same is the case for C vs D (ignore yellow as they offer equal amounts). In other words – if you had preferred A, logic would suggest you choose C and not D.
| Red | Black | |
| A | $100 | $0 |
| B | $0 | $100 |
| C | $100 | $0 |
| D | $0 | $100 |
The second way is to look at it probabilistically. If you chose option A, you are implicitly telling that the probability of Red is more than the probability of Black. If that is the case, in the second exercise, the probability of Red or Yellow has to be greater than the probability of Black or Yellow. But you violated the law with your preference.
Decision under uncertainty
Clearly, the decision was not made based on probability or expected values. What is common for B and C is the perception of ambiguity. In the case of A, there is no 30% guarantee for a Red. In the case of D, there is a 60% guarantee to win $100.

![\text{The probability of winning 100 in 10 dollar bets starting with 10 is (n = 1 and N = 10)} \\ \\ x_{10} = \frac{1-[(18/38)/(18/38)]^1}{1-[(18/38)/(18/38)]^{10}} = 0.06 \\ \\ \text{The probability of winning 100 in 1 dollar bets starting with 10 is (n = 10 and N = 100)} \\ \\ x_{10} = \frac{1-[(18/38)/(18/38)]^{10}}{1-[(18/38)/(18/38)]^{100}} = 0.00005](https://thoughtfulexaminations.com/wp-content/ql-cache/quicklatex.com-2f37e567272f922695016f9869199d9d_l3.png "Rendered by QuickLaTeX.com")