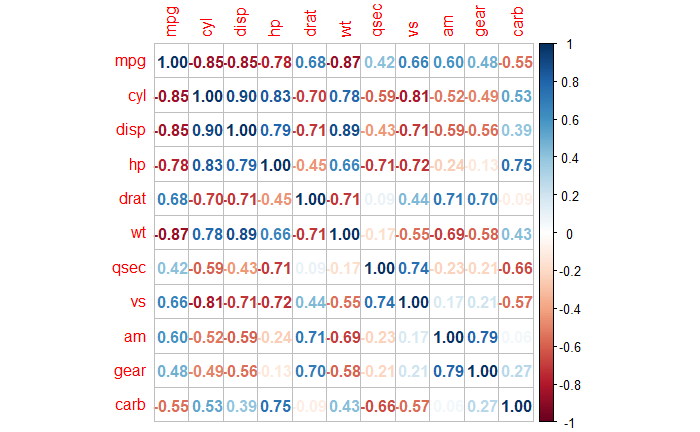
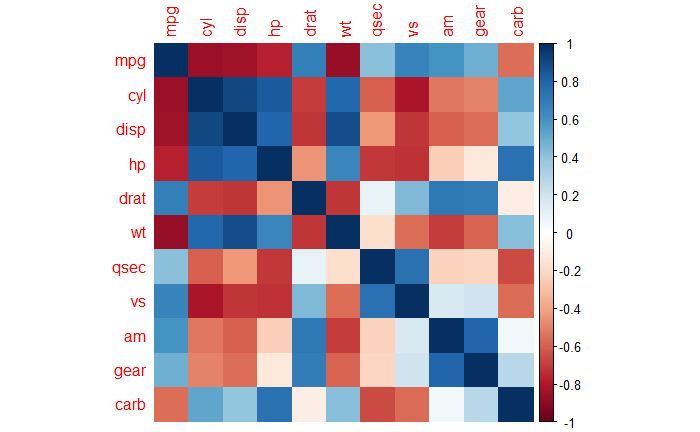
Pearson vs Spearman Correlations
We have seen Pearson’s correlation coefficient earlier. There is a nonparametric alternative to this which is Spearman’s correlation coefficient.
Pearson’s is a choice when there is continuous data for a pair of variables, and the relationship follows a straight line. Whereas Spearman’s is the choice when you have a pair of continuous variables that do not follow a linear relationship, or you have a couple of ordinal data. Another difference is that Spearman correlates the rank of the variable, unlike Pearson (which uses the variable itself).
Rank of variables
A rank shows the position of the variable if the variable is organised in ascending order. The following is an example of a vector, xx and its rank.
| Variable | Rank |
| 10 | 3 |
| 2 | 1 |
| 34 | 5 |
| 21 | 4 |
| 5 | 2 |
Let’s apply each of the correlation coefficients to the mtcars database.
Pearson Method
cor.test(car_data$mpg, car_data$hp, method = "pearson") Pearson's product-moment correlation
data: car_data$mpg and car_data$hp
t = -6.7424, df = 30, p-value = 1.788e-07
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.8852686 -0.5860994
sample estimates:
cor
-0.7761684 Spearman Method
cor.test(car_data$mpg, car_data$hp, method = "spearman") Spearman's rank correlation rho
data: car_data$mpg and car_data$hp
S = 10337, p-value = 5.086e-12
alternative hypothesis: true rho is not equal to 0
sample estimates:
rho
-0.8946646 Spearman via Pearson!
cor.test(rank(car_data$mpg), rank(car_data$hp), method = "pearson") Pearson's product-moment correlation
data: rank(car_data$mpg) and rank(car_data$hp)
t = -10.969, df = 30, p-value = 5.086e-12
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
-0.9477078 -0.7935207
sample estimates:
cor
-0.8946646 Pearson vs Spearman Correlations Read More »