Do you know how long it takes for light from 100 lightyears away from earth to reach us? The answer is: it depends; on where you place the clock. If it is your watch, it will take 100 years. But what if the timepiece was on the photon?
As per the ‘special theory of relativity‘, the faster an object moves, the slower the time ticks for it relative to the observer.
t = time as measured by a stationary observer tphoton = time as measured by the travelling object v = speed of the travelling object and c = speed of light.
Now, substitute v = c; photon (light) travels with the speed of light! tphoton becomes zero.
In other words, light – from wherever it is – reaches you the moment it is born. But you may take one hundred years to catch it!
Let’s visit our favourite subject, but after a long gap – the probability and Bayes’ theorem. Here is the question:
A new child arrives in a child-care facility that has three boys and the remaining girls. A statistician visits the centre and randomly picks up a boy child. What is the chance that the newly admitted child is a boy?
Before solving the puzzle, let the number of girls already in the centre be g. Therefore, the total number of children available for the statistician to count is 3 + 1 + g = 4 + g.
The Bayes’ equation is
The terms are P(B_n | B_r) = probability of the new child being a boy given the randomly picked is a boy P(B_r | B_n) = probability of picking a random boy given the new child is a boy = 4 /(4+g) P(B_r | G_n) = probability of picking a random boy given the new child is a girl = 3/ (4+g) P(B_n) = prior probability for the new child to be a boy = 0.5 P(G_n) = prior probability for the new child to be a girl = 0.5
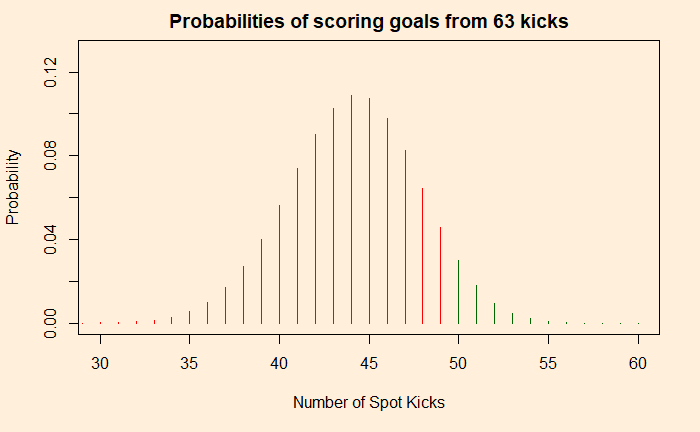
I want to end the football penalty series with this one. We start with a finer data resolution and evaluate the statistical significance zone-wise. The insights from such objective analyses can tell you about statistical significance and how we can get misled easily.
Aiming high doesn’t solve
We have seen in the last post that the three chosen areas of the goal post – the top, middle and bottom – were not statistically differentiable. The following column summarises the results. Focus on whether or not the average success rate (0.69) falls within the confidence interval (for 90%) provided for each. Seeing the average inside the bracket means the observation is not significantly different.
Area
Success (total)
p-value
90% Confidence Interval
0.69 IN/OUT
Top
46 (63)
0.5889
[0.63, 0.81]
IN
Middle
63 (87)
0.6082
[0.64, 0.80]
IN
Bottom
86 (129)
0.4245
[0.60, 0.73]
IN
Overall
195 (279)
As you can see, none of the observations is out of the expected.
Zooming into zones
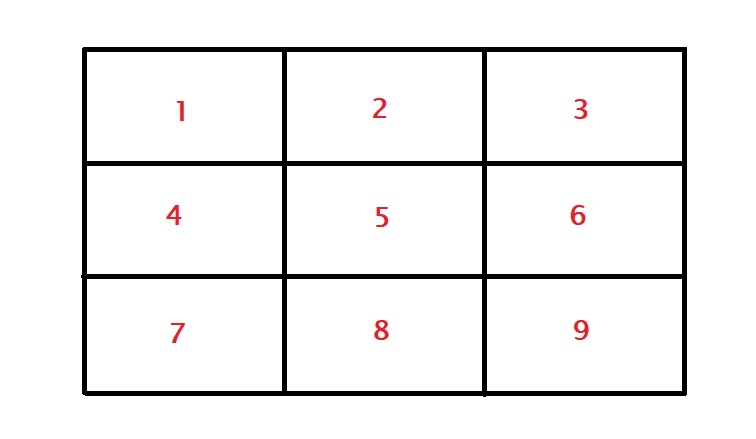
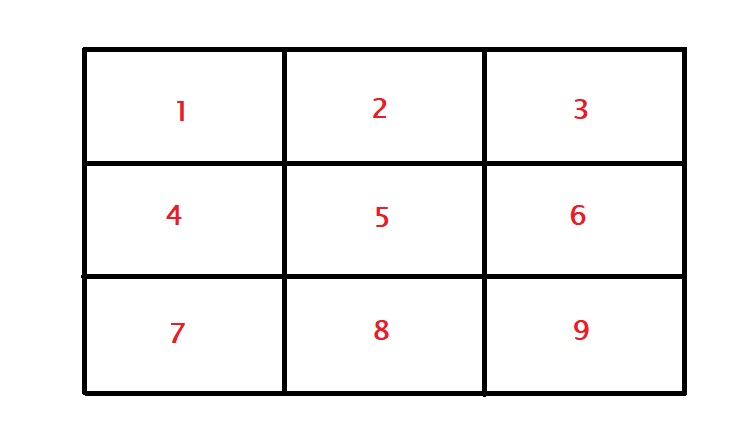
As the final exercise, we will check if a particular spot offers anything significant towards the goal. In case you forgot, here are the nine zones mapped between the goalpost. Note that these are from the viewpoint of the striker.
The data is in the following table.
Zone
Total
Success
Success (%)
zone 1
28
21
0.75
zone 2
19
11
0.58
zone 3
16
14
0.88
zone 4
36
27
0.75
zone 5
18
11
0.61
zone 6
33
25
0.76
zone 7
63
40
0.64
zone 8
20
12
0.6
zone 9
46
34
0.74
A quick eyeballing may appear to tell you something about zone 3 (top right for the striker or top left of the goalkeeper) or zone 2. Let’s run hypothesis testing on each, starting from zone 1.
prop.test(x = 21, n = 28, p = 0.6989247, correct = FALSE, conf.level = 0.9)
Zone
90% Confidence Interval
p-value
zone 1
[0.60, 0.86]
0.56
zone 2
[0.40, 0.74]
0.25
zone 3
[0.68, 0.96]
0.13
zone 4
[0.62, 0.85]
0.70
zone 5
[0.42, 0.77]
0.42
zone 6
[0.62, 0.86]
0.46
zone 7
[0.53, 0.73]
0.27
zone 8
[0.42, 0.76]
0.34
zone 9
[0.62, 0.83]
0.55
Fooled by smaller samples
Particularly baffling is the result on the zone there, where 14 out of 16 have gone inside, yet not significant enough to be outstanding. It shows the importance of the number of data points available. Let me illustrate this by comparing the same proportion of goals but with double the number of samples (28 from 32).
prop.test(x = 14, n = 16, p = 0.6989247, correct = FALSE, conf.level = 0.90)
prop.test(x = 14*2, n = 16*2, p = 0.6989247, correct = FALSE, conf.level = 0.90)
1-sample proportions test without continuity correction
data: 14 out of 16, null probability 0.6989247
X-squared = 2.3573, df = 1, p-value = 0.1247
alternative hypothesis: true p is not equal to 0.6989247
90 percent confidence interval:
0.6837869 0.9577341
sample estimates:
p
0.875
1-sample proportions test without continuity correction
data: 14 * 2 out of 16 * 2, null probability 0.6989247
X-squared = 4.7146, df = 1, p-value = 0.02991
alternative hypothesis: true p is not equal to 0.6989247
90 percent confidence interval:
0.7489096 0.9426226
sample estimates:
p
0.875
85% success rate for a total sample of 32 is significant. The outcome occurred as the chi-squared statistic grew from 2.3 to 4.7 when the sample sizes increased from 16 to 32. If you recall, the magic number for a 90% confidence interval (and degree of freedom of 1) is 2.7, above which the statistics become significant. It is also intuitive because you know that more data increases the certainty of outcomes (reduced noise). So collect more data and then conclude.
NOTE: chi-squared test may not be ideal for the 14/16 case due to smaller samples. In such cases, suggest running binomial tests (binom.test())
Let’s recap the penalty data that we discussed last time.
Attempt
Success
goal %
Total
279
195
69.9%
Top section
63
46
73.0%
Middle section
87
63
72.4%
Bottom section
129
86
66.7%
Is top really on top?
We start with the null hypothesis, H0: H0 = Success rate at the section of the post is no different from the average rate of 0.699
There are many ways to test this hypothesis. The simplest way is to use the ‘prop.test’ in R. Note that we use a 90% confidence interval, which gives a better chance to disprove the premise.
prop.test(x = sum(top_suc), n = sum(top_suc) + sum(top_fai), p = 0.6989247, correct = FALSE, conf.level = 0.9)
1-sample proportions test without continuity correction
data: sum(top_suc) out of sum(top_suc) + sum(top_fai), null probability 0.6989247
X-squared = 0.29207, df = 1, p-value = 0.5889
alternative hypothesis: true p is not equal to 0.6989247
90 percent confidence interval:
0.6301125 0.8112506
sample estimates:
p
0.7301587
The p-value of 0.5889 suggests the hypothesis stays; there is no evidence to suggest that the top brings any advantage! The global average success rate (0.699) is well within the 90% confidence interval [0.63,0.81] of 46 in 63.
Penalty as a binomial trial
Another way to understand this problem is to consider penalty kicks as a binomial trial (with the probability of success = 0.699). If you kick 63 balls to the top section of the post, the expected number of goals, under the assumption of no special advantage, is between 38 and 50.
Another world championship for football is coming to a close, as the final match is scheduled for tomorrow. Getting a penalty kick, either inside the game or at a tie-breaker stage, is considered a sure-short chance to make the all-important goal for the team. Today we look at how teams have managed spot kicks (a.k.a. penalty kicks) in the world cup (from Spain in 1982 to Russia in 2018).
The data is collected from kaggle.com (WorldCupShootouts.csv). We use R to perform the step-by-step analysis. First, the data:
A tibble:279 x 9
Team Zone Foot Keeper OnTarget Goal
BRA 7 R L 0 0
FRA 7 R R 1 1
GER 1 L R 1 1
MEX 6 L L 1 1
GER 8 L L 1 1
MEX 8 R L 1 0
GER 7 R L 1 1
MEX 7 R L 1 0
GER 4 R L 1 1
SPA 7 R R 1 1
...
21-30 of 279 rows
The first meaningful data in the table is the column Zone, which represents which part of the goalpost (from the viewpoint of the player who takes the kick). The figure below shows all the zones. For example, zone 7 represents the bottom right side of the goalkeeper, 3 is the top left side of the goalkeeper etc.
The two other variables we will use in this analysis are – Ontarget: 1 = on target, 0 = off target, goal: 1 = goal, 0 = no goal.
The probability of scoring a penalty
There are many ways to calculate that – add a filter to the column, goal, = 1, and divide the term by the total number of attempts. We use something simple – the which function.
we have a 0.73 (73%) probability of scoring a goal. Run the code for the middle and bottom, and you get 72% and 67%, respectively. We will look at the significance of these differences at another time.
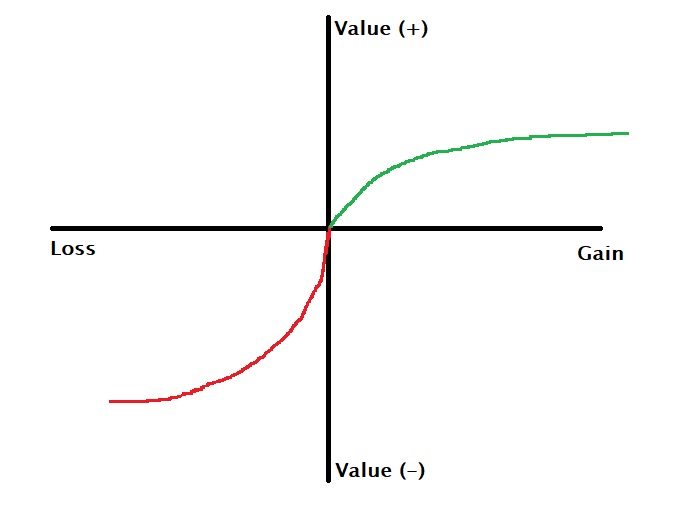
Prospect theory is a behavioural model which explains how people make decisions that involve risk. It has been observed that people take gains and losses differently. In short, to the decision maker, the pain of losing something scores higher over the pleasure of gaining – the risk aversion.
The plot below illustrates the prospect theory. While both the positive side (green part) and the negative side (red part) reflect diminishing marginal utility (flattening towards the higher x values), the initial few gains and losses have distinct shapes. Imagine the feeling you have when you get 100 dollars; compare that with gaining an additional hundred dollars, say from 2000 to 2100.
The fundamental question here is: what defines the origin of the plot? One possibility is that it represents the present state. I can also argue it marks the expectations. An example of the latter is the famous case of silver medal winners. Studies seem to indicate that the second-place winners of sports events were unhappier than the third-place holders, especially when it is contrary to prior expectations.
Daniel Kahneman and Amos Tversky; Econometrica, 47(2), 1979, 263-291 McGraw et al.; Journal of Experimental Social Psychology 41, 2005, 438–446
Muons are subatomic particles formed by high energy collisions of cosmic rays with air molecules in the earth’s atmosphere about 15 km from the surface. These particles have an average lifetime of 2.2 microseconds. How do you know about muons? Because you can measure their presence using particle detectors.
Do you see anything weird with the above statements? Well, take out your pen and paper and calculate the distance a muon travels before it’s finished. And use the maximum speed, the speed of light.
speed = 300,000 km/s time = 2.2 x 10-6 s distance = speed x time = 0.66 = 660 m
So, what’s going on here? The muons should be done in the first 660 metres after their journey from 15 km high. But they do come home. Think of it this way: that is only possible if their time of 2.2 microseconds is slower than ours or our distance of 15 km is shortened for them.
Since they are travelling pretty fast, their time passes slowly, like the following:
Put v = 99.9% of speed c, the speed of light, and you get 22 microseconds. So, for a muon that travels at 99.9% the speed of light, it will live for 22 microseconds (for us), and during that time, it can travel 6 km!
By the way, we just proved Einstein’s theory of special relativity.
From a muon’s perspective, we are moving closer to them at 99.9% speed of light. And when that happens, the distance contracts by the following formula.
This Paradox Proves Einstein’s Special Relativity: Up and Atom
We saw possibilities of random errors during cell divisions leading to mutations. Despite all the corrective mechanisms that the body has, some of those can lead to genetic diseases such as cancer. Naturally, one would expect the probability of cancer to be proportional to the number of cell divisions. If you extrapolate the logic further, it is logical to conclude that the number of cells, the larger the animal, will lead to more occurrences of cancer.
In other words, an elephant has more probability than humans, which, in turn, has a lower chance than a blue whale. But that is never seen in real life. This lack of correlation between animal size with the propensity to get cancer is known as Peto’s Paradox.
The Long-term Experimental Evolution Project of Prof. Richard Lenski’s team at Michigan state university is a significant movement in our understanding of evolution. The team so far has achieved three decades of evolution of E.Coli bacteria in their laboratory. That corresponds to more than 76,000 generations of the organism starting from the common ancestor, noting that it goes through six or seven generations per day!
The experiments started with growing bacteria colonies in a petri dish and taking small sub-samples to 12 flasks containing a solution of glucose, potassium phosphate, and citrate at 37 oC. On the next day, 1% of the sample from the flask is transferred to a fresh sterile flask. And the process has been repeated every day for the last 34 years.
For humans, 76,000 generations could mean more than 1.5 million years. But does it mean the experiments are expected to see what changes animals or humans to accumulate in 1.5 million? Well, this is a question that ant-evolutionists ask. We will answer these questions in the coming days.
The nuclear event in Fukushima started with the Tohuku earthquake and the subsequent tsunami in 2011. It was interesting to notice that employing a probabilistic risk assessment (PRA) would have resulted in a decent chance for station backout due to tsunami (5%) and should have been factored into the decision-making process. Now let’s look at the technical details of what happened.
What happened? The tsunami of 2011 resulted in the flooding of the low-lying blocks of the reactor buildings, and that caused system backout (main and electrical power and the Emergency diesel generators). This contributed to a lack of cooling and, thereby, the reactor melting. The cladding material of the fule rode is made of Zirconium (Zr), and at elevated temperatures, Zr reacted with water leading to the production of hydrogen and explosions. The end result was damage to the fuel core and a release of fission products, including the radioactive I and Cs.