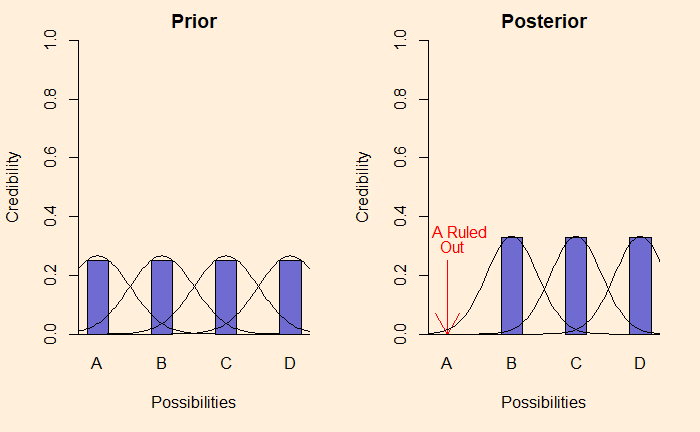
Motivated Reasoning
When there are scientific data, why do people still debate? This was one fundamental question that attracted the attention of scientists and sociologists.
From education levels to ideology
There are multiple hypotheses on this topic. One suggests that the ability to interpret data, such as numerical abilities, is a predictor of people’s understanding of scientific studies. The other was about the ideological biases of people.
One study was carried out by Kahan et al., who selected 1111 US adults from diverse backgrounds. Their composition was summarised in the following tables. Two sets of problems are used – one was ideologically neutral (the skin rash problem), and the other was sensitive (the gun possession problem).
The skin cream problem
| Rash got worse | Rash got better | |
| Patients who used cream | 223 | 75 |
| Patients who did not use cream | 107 | 21 |
| Rash got better | Rash got worse | |
| Patients who used cream | 223 | 75 |
| Patients who did not use cream | 107 | 21 |
The hypothesis formed here was that the individuals holding higher numeracy to score right results in the skin care problem. It turned out to be true – the people with higher cognitive abilities interpreted the results correctly. There was no real pattern suggesting a dependence on whether the subject was a Democrat or a Republican.
The gun control problem
| Increase in Crime | Decrease in Crime | |
| Cities that banned concealed guns in public | 223 | 75 |
| Cities that banned concealed guns in public | 107 | 21 |
| Decrease in Crime | Increase in Crime | |
| Cities that banned concealed guns in public | 223 | 75 |
| Cities that banned concealed guns in public | 107 | 21 |
But the pattern of gun control was different. It was not the numeracy that dominated the outcome but the ideology. The liberals increasingly corrected identified results that supported their view – crime decreases with gun control. And almost a complete shun to the crime increases scenario.
Conservatives, on the other hand, increasingly ‘understood’ (as a function of their numeracy) the crime-increased-by-gun-control data but ignored the opposite results.
Motivated Reasoning Read More »