Continuing with the Poisson distribution, we will work out an example today. The nursing supervisor of a busy hospital knows that, on average, 16 child-births happen in an 8-hr shift. How will she manage the wards, making sure the delivery service is optimally staffed?
Assuming delivery is dominated by natural delivery, which is stochastic, we resort to Poisson distribution to make the required calculations. Start with the extreme values.
What is the probability of having zero childbirth in a shift?
This can also be obtained directly using the R, ppois(0,16). What is the probability of getting up to 7 births (0 – 7)? ppois(7,16) = 0.00999 or about 1%. Also, the supervisor now knows at 90% certainty that it would not be more than 21 as ppois(21,16) is 91%.
Reference
Biostatistics for Medical and Biomedical Practitioners, 2015, Pages 259-278: Chapter 18 – The Poisson Distribution
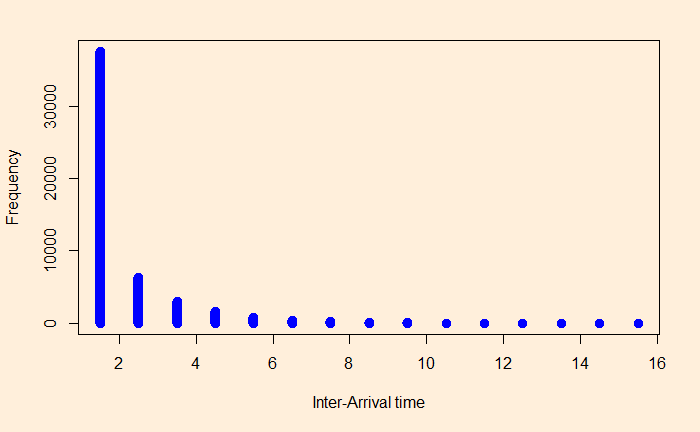
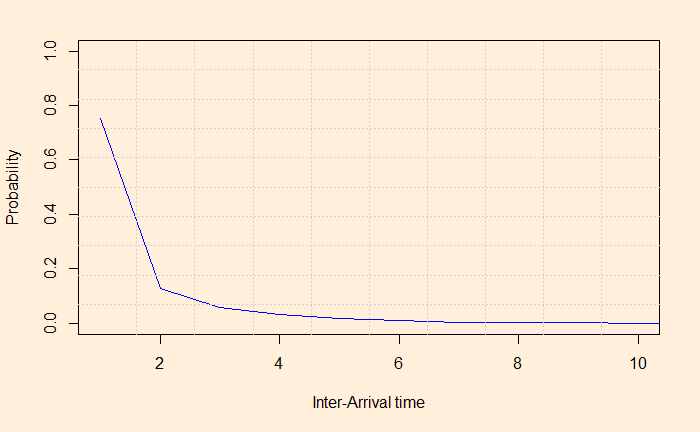
We did establish Poisson distribution through coin tossing. Here we calculate the distance between the arrivals or the interarrival times. This is obtained by marking the indices of heads and then finding the difference between two successive heads.
First, we run 100000 simulations of coin-tossing and collect the heads (H) as successes in an array. Find out the indices of the array, which are nothing but the arrival times. The difference between the indices is the interarrival times.
n <- 100000
xx_f <- sample(c("H", "T"), n, TRUE, prob = c(1/2, 1/2))
index <- which(xx_f =="H")
length(index)
dist <- rep(0,length(index)-1)
for (i in 1:length(index)-1) {
dist[i] <- index[i+1] - index[i]
}
We show the first 100 appearances of H in the following plot.
The frequencies and densities of the interval arrival distances are in the graphs.
Coin tossing exercises are a simple but valuable means to understand a lot of real-life situations. Here we learn Poisson distribution by tossing a coin.
Poisson processes are used to model the number of occurrences of events over certain periods of time. They are discrete processes and also stochastic, i.e. the outcomes are random.
Customer arriving at a shop is often viewed as an example of the Poisson process. The shopkeeper knows the number of customers she expects in a day or an hour based on experience but never can’t predict what happens next minute. The following set of plots describes four such distributions for different mean arrivals (lambda).
As you can see, mean arrivals, coinciding with the peaks of these plots, are informative. However, the actual comings will vary between higher and lower values making certain decisions, staff allocations to support customers, for instance, very tricky.
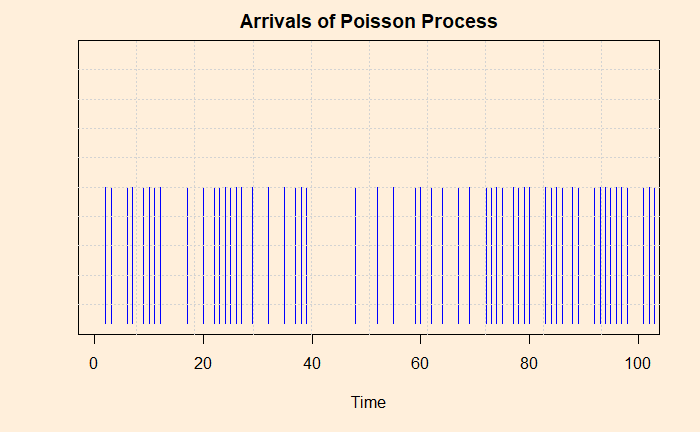
So far, we have focussed on fixed time duration but random arrivals. You can also understand Poisson differently – a specified number of arrivals at random intervals. Look at the following graph: it describes a Poisson activity; time on the x-axis, and each vertical line denotes one appearance. Don’t waste your time on a pattern; there is no pattern!
Toss a coin
The above picture describes the tossing of a coin (e.g. every second) and marking an entry whenever a head happens.
n <- 100000
xx_f <- sample(c("H", "T"), n, TRUE, prob = c(1/2, 1/2))
index <- which(xx_f =="H")
We just plotted the index values corresponding to H.
Which hand is more valuable, four-of-a-kind or full-house? Well, that depends on which of the two is rarer. Let’s calculate them. If you are still unsure what I am talking about – it is about the 5-card poker game.
In a 5-card hand poker game, a player gets five cards from a well-shuffled deck of cards. Remember: one deck has 52 cards – 13 ranks in each of the four suits. The 13 ranks are 2, 3, 4, 5, 6, 7, 8, 9, 10, J, Q, K, A, and the four suits are diamonds, hearts, aces and clubs. Now, over to calculations.
The probability of a hand equals the number of ways you get a particular pattern (four-of-a-kind and full-house, in our case) divided by the total number of ways you can get five random cards from a deck of 52. If you recall some of the earlier posts, the latter is nothing but the combination, 52C5.
Four of a kind
What is the number of possibilities to get this pattern? One way to approach this is to imagine five boxes. Your task is to fill the first four boxes with of kind (rank). There are 13C1 ways to find rank and 4C4 ways to arrange four suits from the maximum of four. So, the first four boxes can be filled by 13C1 x 4C4 number possibilities. Once the first rank is done in the first four boxes, there are 12 other ranks remaining for the last box. Using the same argument we used before, that becomes 12C1 x 4C1.
The final probability is (13C1 x 4C4 x 12C1 x 4C1) / (52C5) = 624 / 2598960 = 0.00024
Full house
You need three of one kind and two of another to get full-house.
Imagine the five boxes again. This time, we first fill three with 13 kinds, one at a time and four suits, three at a time. 13C1 x 4C3. The remaining two boxes need to be filled with another kind. 12C1 x 4C2. The total options are 13C1 x 4C3 x 12C1 x 4C2 = 3744 / 2598960 =0.00144.
Summary
The four-of-a-kind has a lower chance of occurrence compared to the full-house. The former is, therefore, more valuable.
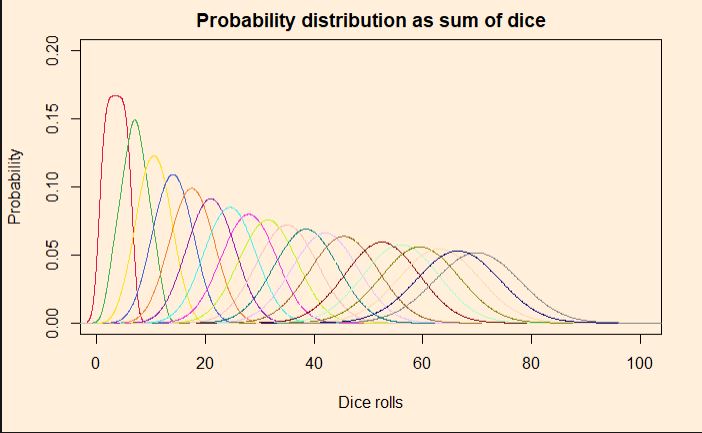
We have seen how outcomes from games with uniform probabilities add up to a normal distribution. Today we make a little R program that simulates this and plots the probability densities on one graph. In the end, we will explore how to construct the normal distribution that it approximates. Here is the plot that shows the rolling of up to 20 dice, starting from a single one.
Simulating the dice
As usual, we use the sample() function to throw out random outcomes by providing six options with equal probabilities. The sampling is then placed inside a loop that keeps on adding outputs.
plots <- 20
sides <- 6
roll_ini <- replicate(100,0)
roll <- sample(seq(1:sides), 1000000, replace = TRUE, prob = replicate(sides,1/sides))
Dist_ini <- density(roll, bw=0.9)
par(bg = "antiquewhite1")
plot(Dist_ini, ylim=c(0,0.2), xlim=c(1,100), main="Probability distribution as sum of dice", xlab = "Dice rolls", ylab = "Probability")
for (i in 1:plots){
roll <- roll_ini + sample(seq(1:sides), 1000000, replace = TRUE, prob = replicate(sides,1/sides))
Dist <- density(roll, bw=0.9)
mycolors <- c('#e6194b', '#3cb44b', '#ffe119', '#4363d8', '#f58231', '#911eb4', '#46f0f0', '#f032e6', '#bcf60c', '#fabebe', '#008080', '#e6beff', '#9a6324', '#fffac8', '#800000', '#aaffc3', '#808000', '#ffd8b1', '#000075', '#808080', '#ffffff', '#000000')
lines(Dist, col = mycolors[i])
roll_ini <- roll
}
We then derive the normal distribution that corresponds to the above. The mean and standard deviation of rolling a die are:
Add the following line at the end, and you get the comparison for normal distribution for rolls of 20 dice summed over.
norm_die <- 20
lines(seq(0,100), dnorm(seq(0,100), mean = norm_die*(7/2), sd = sqrt(norm_die*(35/12))), col = "red",lty= 2, lwd=2)
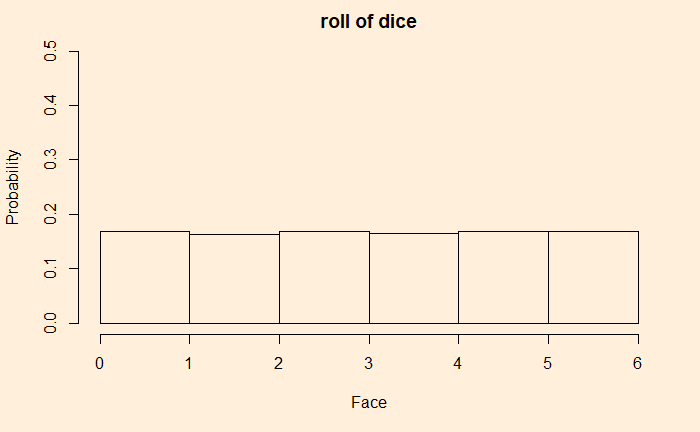
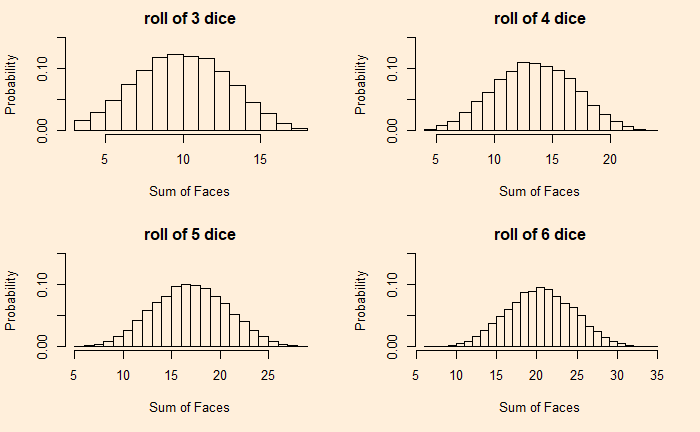
You know what happens if you roll a fair die; you get one of the six faces. But what happens when you try it 10000 times and plot the frequency or the probability?
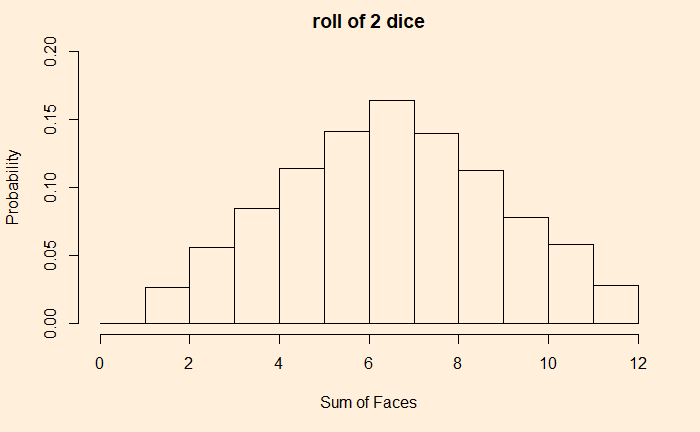
We have a uniform distribution with probability = 1/6. What happens if we throw two dice and plot the distribution of their sums?
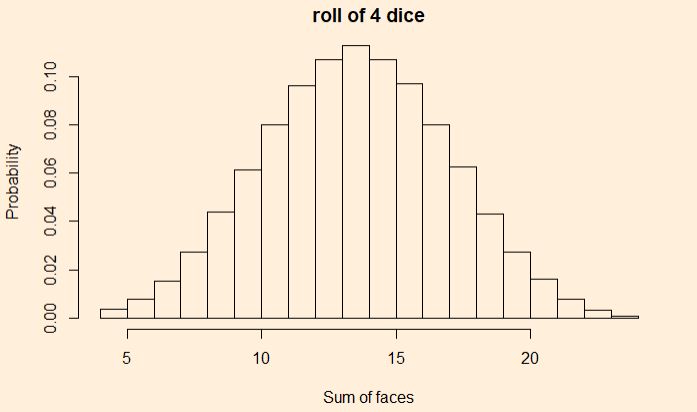
It resembles a triangular distribution with a maximum probability of getting seven as the sum. Let’s not stop here: add the outcomes of four dice.
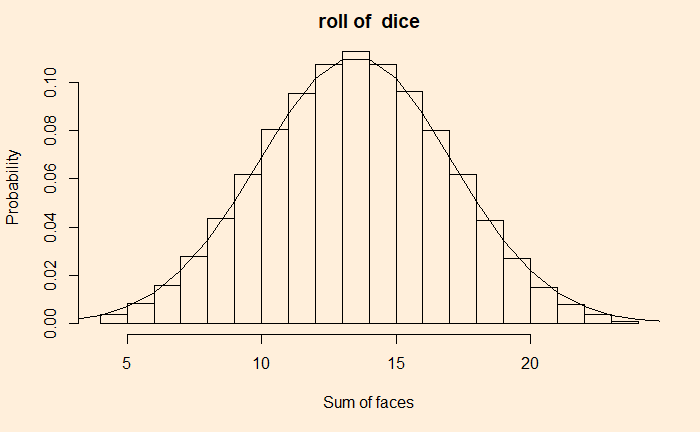
It appears more like a uniform distribution. Let’s insert one such distribution and see how it looks.
We can see the more the number of such random outcomes we add (more number of dice together), we approach the realm of the central limit theorem.
Let’s calculate a few poker probabilities for the 5-card hands. We employ basic calculations and some simulations.
5 hands from 52 cards
First, what is the total number of ways of getting five cards from a deck of 52? Is that a permutation or a combination? The fundamental question to ask is whether the order matters or not. The order of cards doesn’t matter here; hence we use combinations to get the required value.
Royal flush
This one comes first in the order and has a sequence of 10, J, Q, K, A, of a given suit.
The calculation is simple: Getting this combination out of five cards is 5C5 = 1. Since there are four types (suits), clubs, diamonds, spades and hearts, the total number becomes 4. The required probability of getting a royal flush is (4/2,598,956) = 0.00000154. Let’s do the simulation
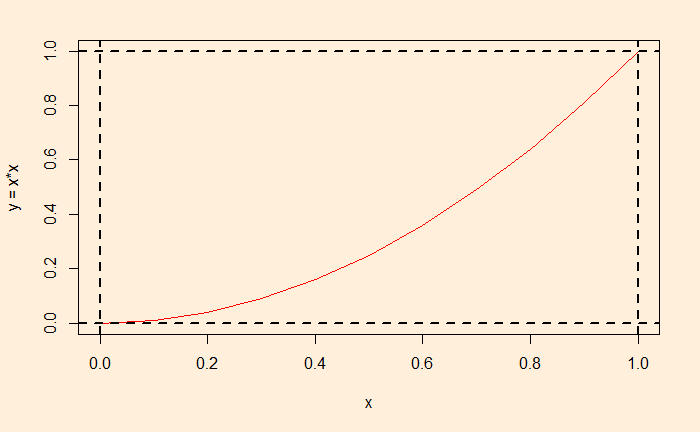
You may have known how to evaluate a definite integral or integrals bounded within limits. For example, consider the following:
We can estimate the value by integrating the function y = x2 and applying the limits.
The function (within those bounds) is plotted below, and the required integral is the area under the curve.
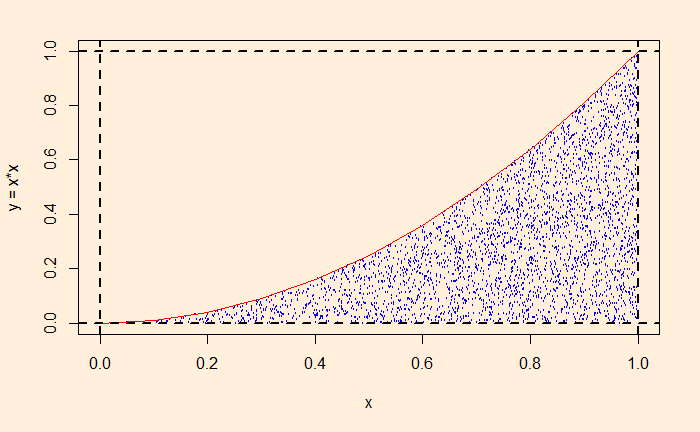
Looking at the graph above, one can envision that the required area is the fraction of a unit square at which the relationship, y </= x2 works. As we have done before, we will fill the unit square by selecting random numbers between 0 and 1 and collect the fraction that obeys the equation. This this:
itr <- 10000
xxx <- replicate(itr,0)
yyy <- replicate(itr,0)
counter <- 0
for (rep_trial in 1:itr) {
xx <- runif(1)
yy <- runif(1)
if(yy <= xx*xx){
xxx[rep_trial] <- xx
yyy[rep_trial] <- yy
counter <- counter + 1
}
}
counter/itr
And the output (the integral, counter/itr) is 0.3312.
Simulations like these, the probability of hitting between the restricted boundaries of a unit square, are handy for estimating areas under functions that are difficult to integrate analytically.
At Duke University, two students had received A’s in chemistry all semester. But on the night before the final exam, they were partying in another state and didn’t get back to Duke until it was over. Their excuse to the professor was that they had a flat tire, and they asked if they could take a make-up test. The professor agreed, wrote out a test and sent the two to separate rooms to take it. The first question (on one side of the paper) was worth 5 points, and they answered it easily. Then they flipped the paper over and found the second question, worth 95 points: ‘Which tire was it?’
Source: Marilyn vos Savant, Parade Magazine, 3 March 1996, p 14.
The question for today is: What is the probability for the students to get the second question right? 1) If the students have no preferences for a specific tyre? 2) If they have the following preference: right front, 58%, left front, 11%, right rear, 18%, left rear, 13%?
Counting
Let’s address the first problem by counting all possibilities.
RF
LF
RR
LR
RF
RF,RF
RF,LF
RF,RR
RF,LR
LF
LF,RF
LF,LF
LF,RR
LF,LR
RR
RR,RF
RR,LF
RR,RR
RR,LR
LR
LR,RF
LR,LF
LR,RR
LR,LR
There are a total of 16 possibilities, and four of them (highlighted in bold) are common. So the required probability for two students having the same random answers is 4/16 or 1/4.
Adding joint probabilities
Another way to reach the answer is by adding the joint probabilities of each of the four guesses. P(RF, RF) + P(LF, LF) + P(RR, RR) + P(LR, LR). P(RF, RF) is the joint probability of both the students arriving at the right front independently. If each one has a (1/4) chance, P(RF, RF) = P(RF) x P(RF) = (1/4)(1/4) = (1/16). Collecting all of them, P = P(RF) x P(RF) + P(LF) x P(LF) + P(RR) x P(RR) + P(LR) x P(LR) = (1/4)(1/4) + (1/4)(1/4) + (1/4)(1/4) + (1/4)*(1/4) = (1/4).
For the second question: P = 0.58 x 0.58 + 0.11 x 0.11 + 0.18 x 0.18 + 0.13 x 0.13 = 0.3978 or about 40%.
Simulation
Let’s run the following R code and verify the answer.
You must have heard of the odds of winning bets. It says what kind of bet you would be willing to make. It is often confusing as there are several conventions to describe. We will see them one by one and understand the associated probabilities.
Odds in stats
A 2 to 1 odds means that out of three possible outcomes, there will be 2 of one kind and 1 of another. It means there is a probability of 2/3 (66.7%) for one and 1/3 (33.3%) for the other. The relationship is:
For p = 2/3, odds = (2/3)/(1-(2/3)) = 2/3/1/3 = 2/1.
The odds of rolling a six in a die is 1 to 5. This means one outcome will favour a six, and five do not.
In gambling
Things take a slightly different turn in gambling. The odds in gambling focus on winning the stake and, therefore, represent the amount the bookmaker pays along with the original bet. Odds of 4/1 means the bettor stands to make 4 profit on a stake of 1 (gets a total of 4 + 1 = 5). And there are four styles of betting odds:
1. Americal style
Boston Celtics: +450 Golden State Warriors: +550 Milwaukee Bucks: +800
Those mean: If you bet 100 on the Celtics, you win 450; a total payout of 550. Warriors: bet 100, win 550, payout of 650. Finally, the bucks can win you 800 and a payout of 900 for a 100 bet.
Odds with a negative sign in front mean how much money you need to bet to win 100. So -200 means you get 100 if you bet 200 (total payout = 100 + 200 = 300).
2. Decimal style
Multiply the decimal with the wager, and you get the payout. So for the Celtics case, the decimal odd is 5.5. Bet 100, and you get 5.5 x 100 = 550 as the payoff.
3. Fractional style (UK)
Like the American style, this calculates the profit and not the payout. a/b (a-to-b) means your profit is (a/b) x wagered amount. So for the Celtics, the fractional odds are 4.5/1 or 9/2.
4. Implied odds
It is the probability equivalent in the betting world. A 9-to-2 odds imply it is an underdog with a chance of 2 out of 11 for winning or 18.18%.





![\\ \text{ mean } = E[X] = \sum\limits_{i=1}^6 x_i p_i = x_1p_1 + x_2p_2 + x_3p_3 + x_4p_4 + x_5p_5 + x_6p_6 \\ \\ = 1 * \frac{1}{6} + 2 * \frac{1}{6} +3 * \frac{1}{6} +4 * \frac{1}{6} +5 * \frac{1}{6} +6 * \frac{1}{6} = \frac{21}{6} = \frac{7}{2} = 3.5\\\\ \text {for n rolls,} \\ \\ E[X_1 + X_2 + ... + X_n] = E[X_1] + E[X_2] + ... + E[X_n] \\ \\ E[X + X + ... + X] = E[nX] = nE[X] = 3.5*n \\ \\ \text{variance} = Var[X] = E[(X - \mu)^2] \\ \\ Var[X] = \sum\limits_{i=1}^6 \frac{1}{6} (i-\frac{7}{2})^2) = \frac{1}{6} [ (- \frac{5}{2})^2 + (- \frac{3}{2})^2 + (- \frac{1}{2})^2 + (\frac{1}{2})^2 + ( \frac{3}{2})^2 + ( \frac{5}{2})^2] \\ \\ Var[X] = \frac{35}{12} \\ \\ \text{standard deviation } = \sigma = \sqrt{(Var[X])} = \sqrt{\frac{35}{12}} \\ \\ \text {for n rolls,} \\ \\ Var[(X+Y)] = Var[X] + Var[Y] + Cov(X,Y) \\ \\ Var[(nX)] = n*Var[X] + 0 \text{ , } Cov(X,X) = 0\\ \\ Var[(nX)] = \frac{35}{12} n \\\\ \sigma = \sqrt{\frac{35}{12} n}](https://thoughtfulexaminations.com/wp-content/ql-cache/quicklatex.com-dae737128427a51955019607d5d1b795_l3.png "Rendered by QuickLaTeX.com")